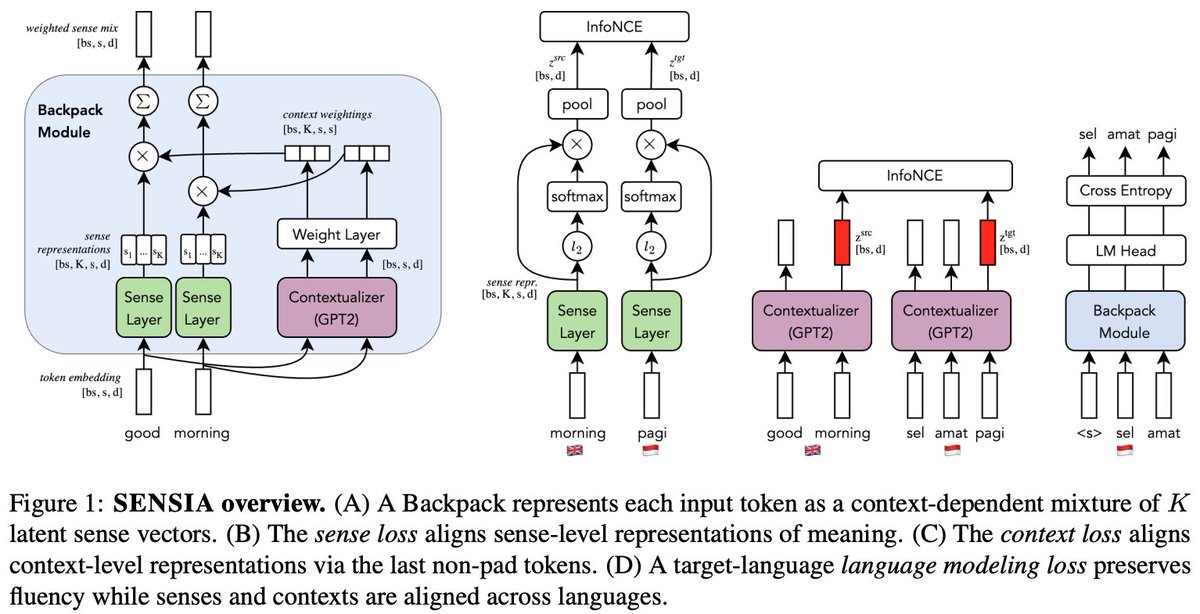
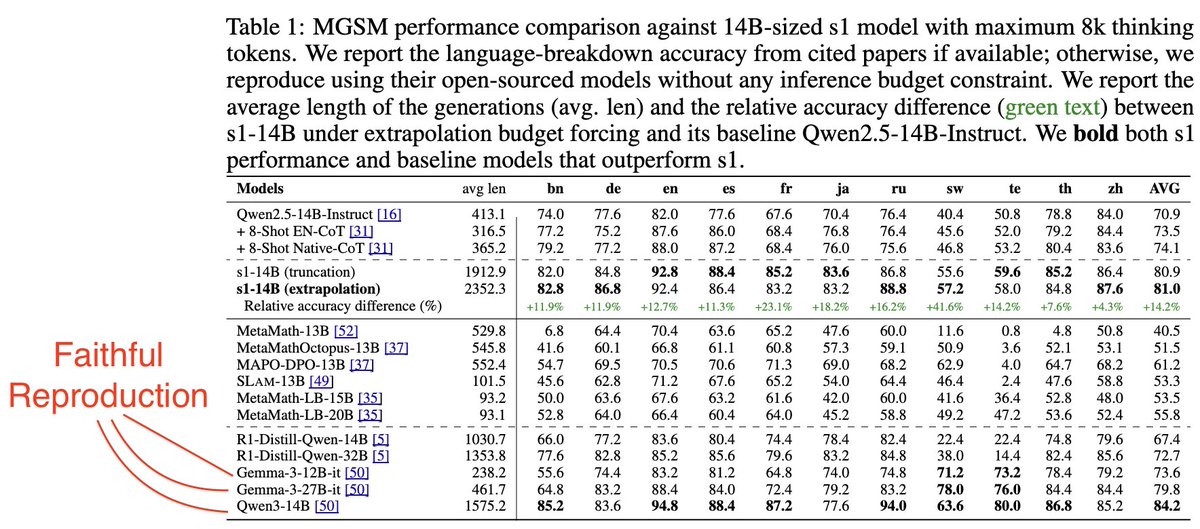
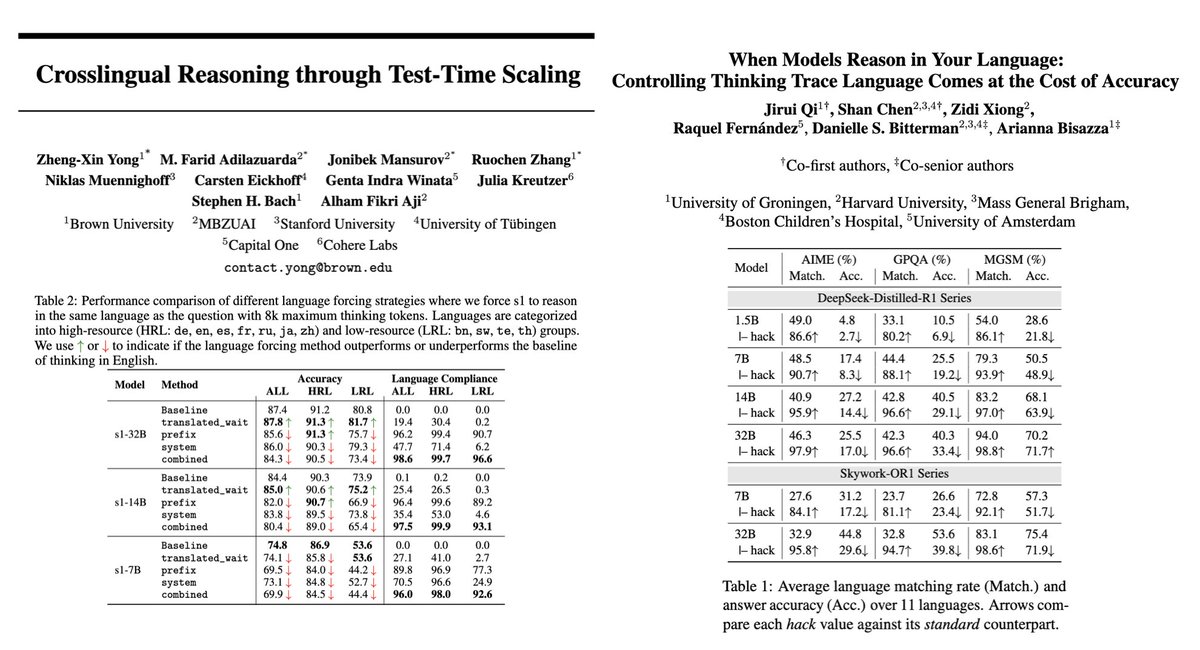
Jonibek Mansurov retweetledi

@akshay_pachaar The main (first, last/corresponding) authors are from MBZUAI. The UCL author is also visiting MBZUAI. Please credit them accordingly
x.com/AlhamFikri/sta…
Alham Fikri Aji@AlhamFikri
"Researchers from UCL" but they are all from MBZUAI, even the first and corresponding authors Give proper credit please. You don't have to go this low for clout
English