Ahmad Al-Dahle@Ahmad_Al_Dahle
It’s here! Meet Llama 3, our latest generation of models that is setting a new standard for state-of-the art performance and efficiency for openly available LLMs.
Key highlights
• 8B and 70B parameter openly available pre-trained and fine-tuned models.
• Trained on more than 15T tokens, 7x+ larger than Llama 2's dataset!
• Improved tokenizer with vocabulary of 128K tokens for better performance.
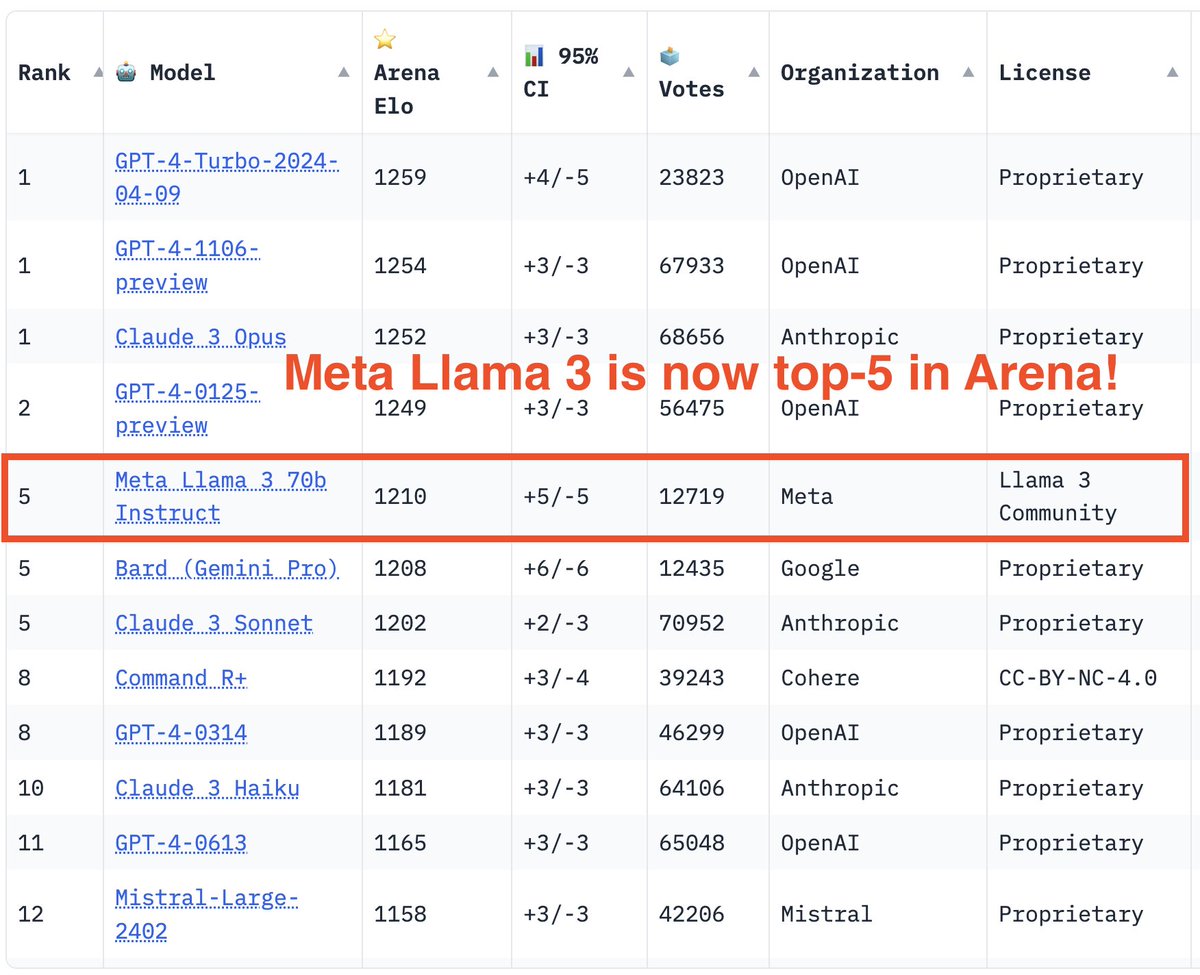
• State-of-the-art performance across industry benchmarks.
• New capabilities, including enhanced reasoning and coding.
• 3x more efficient training than Llama 2.
• New trust and safety tools with Llama Guard 2, Code Shield, and CyberSec Eval 2.
• Integrated into Meta AI, and available in more countries across our apps.
• And, just the beginning with more models and new capabilities coming soon!
Visit the Llama 3 website to read more and download the models. llama.meta.com/llama3