Sabitlenmiş Tweet

Under the Hood: The LLM Engineering Manual - the 2026 Version 2 update is live.
36 projects that build every layer of a large language model from scratch, from a scalar .backward() all the way to a production serving stack. One rule throughout: build it, break it, measure it. ~1,030 pages, and every number traces to a primary source.
What's new in v2
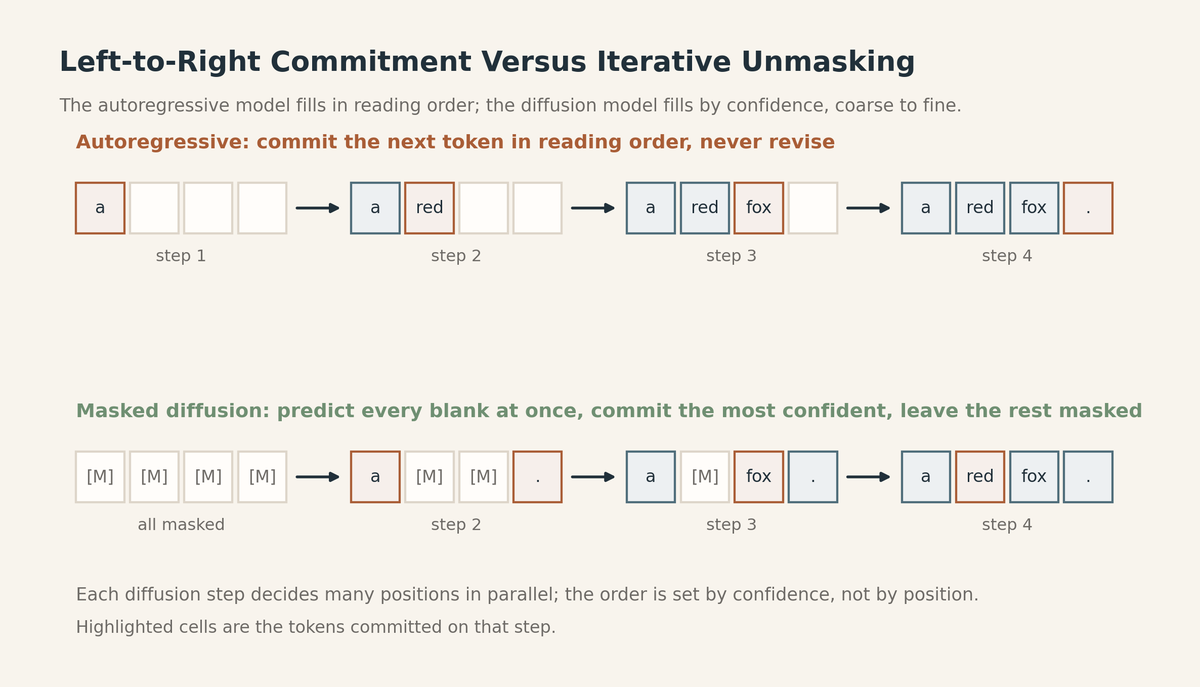
A brand-new project: Diffusion & Non-Autoregressive Decoding. You build a decoder by hand, on a laptop, that writes a sentence the way you fill a crossword, committing the words it's surest of first instead of strictly left to right. Then you break it and watch coherence collapse when you rush the step count.
12 chapters got surgical 2026 updates, each fact-checked to primary sources:
• KV cache quantized to ~3 bits + fp8 serving
• speculative decoding: block-diffusion drafters & multi-token prediction
• hybrid SSM/attention models (Jamba, Mamba-2): mostly-linear stacks with a thin spine of attention
• inference-time compute, best-of-N, and RL with verifiable rewards
I ran the new fp8-serving labs on real hardware (an NVIDIA GB10) to confirm the claims reproduce: fp8 KV holds ~2.07x the token budget of bf16, and a causal drafter composes with it for ~1.9x throughput at 71% draft acceptance. Charts + raw data are in the free code repo. In addition, many of the items called out by users in v1 have been rewritten/fixed.
Already own it? It's a free update. Just re-download the PDF/EPUB.
Book: leanpub.com/under-the-hood
Code, all 36 projects: github.com/mechramc/Under…
Next step: Amazon KDP (In progress) - drop a like, comment or retweet if you liked the updates



English













