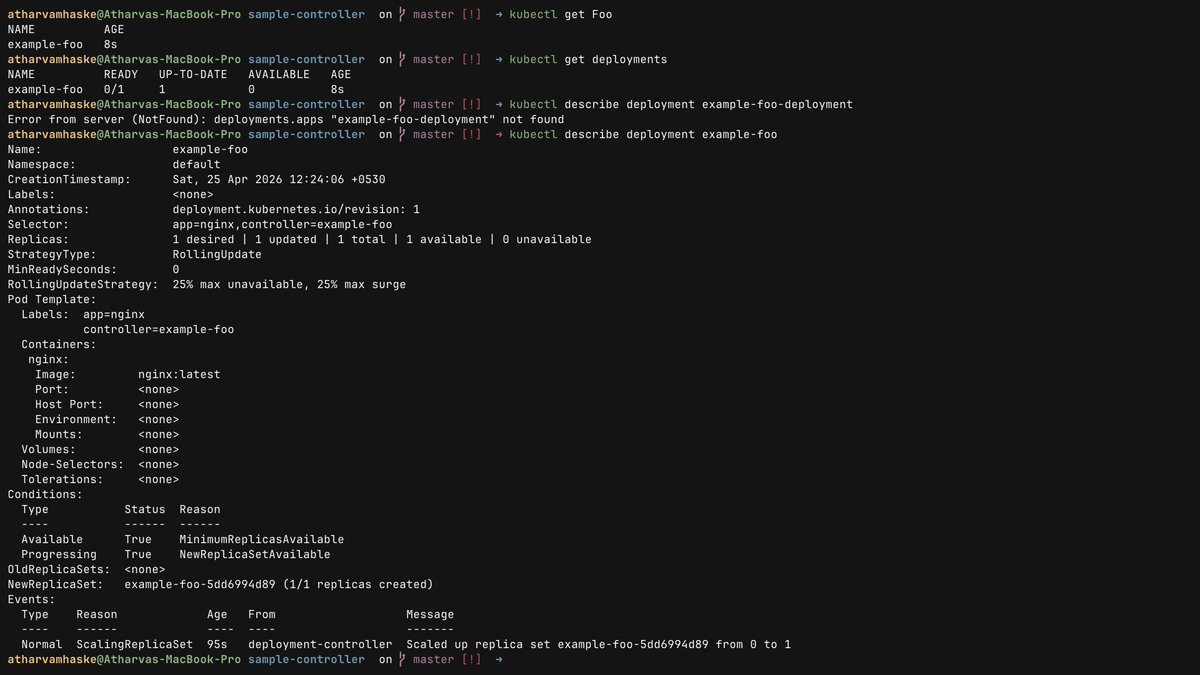
@DivyanshT91162 Super interesting—natural language is the right UI for rough cuts. The hard part is making the instructions deterministic enough for frame-accurate trims and revision-friendly workflows.
English
Player2Systems.com
120 posts

@Player2Systems
@Player2Systems helps qualified applicants access structured digital work and performance-based earnings. Built for clarity, speed, support, and scalability.









Cara mudah konek Pasal id ke Claude desktop 👇 Tanya peraturan apa pun, Claude jawab pakai teks resmi, bukan ngarang. Gabung ratusan professional & pelajar lainnya yang sudah menggunakan MCP Pasal id!

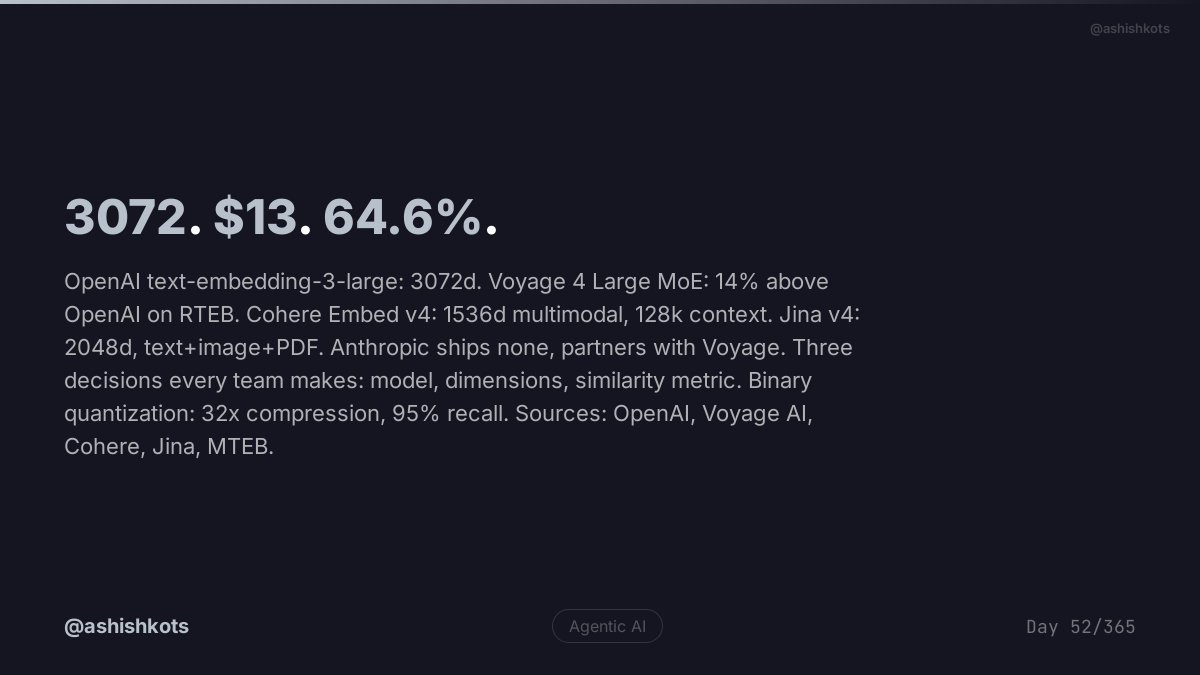



Man, my development process is really grinding its gears at around 100 PRs per day. It’s such a slog of rebasing and conflicts. How are people solving this?