tab
280 posts




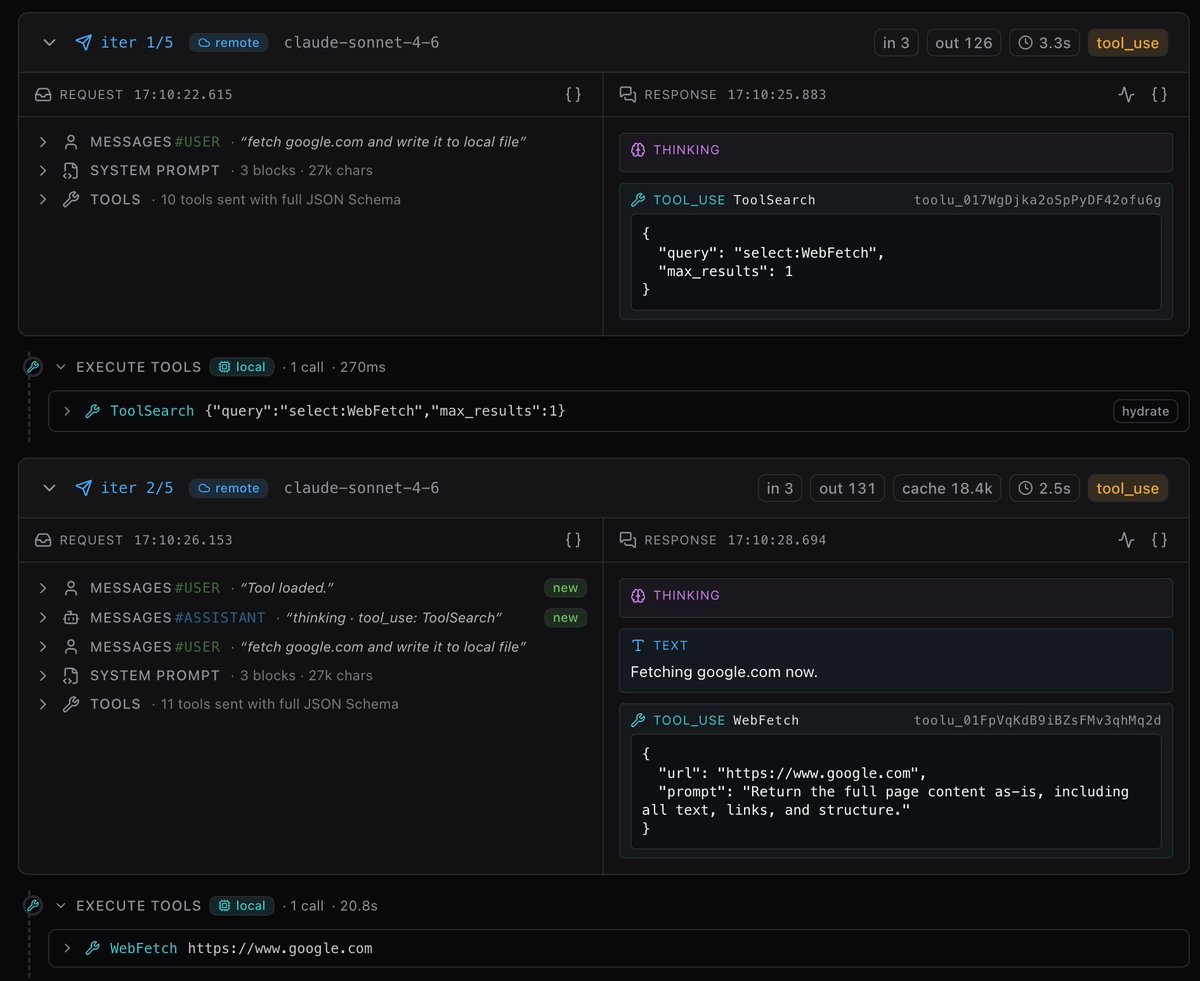


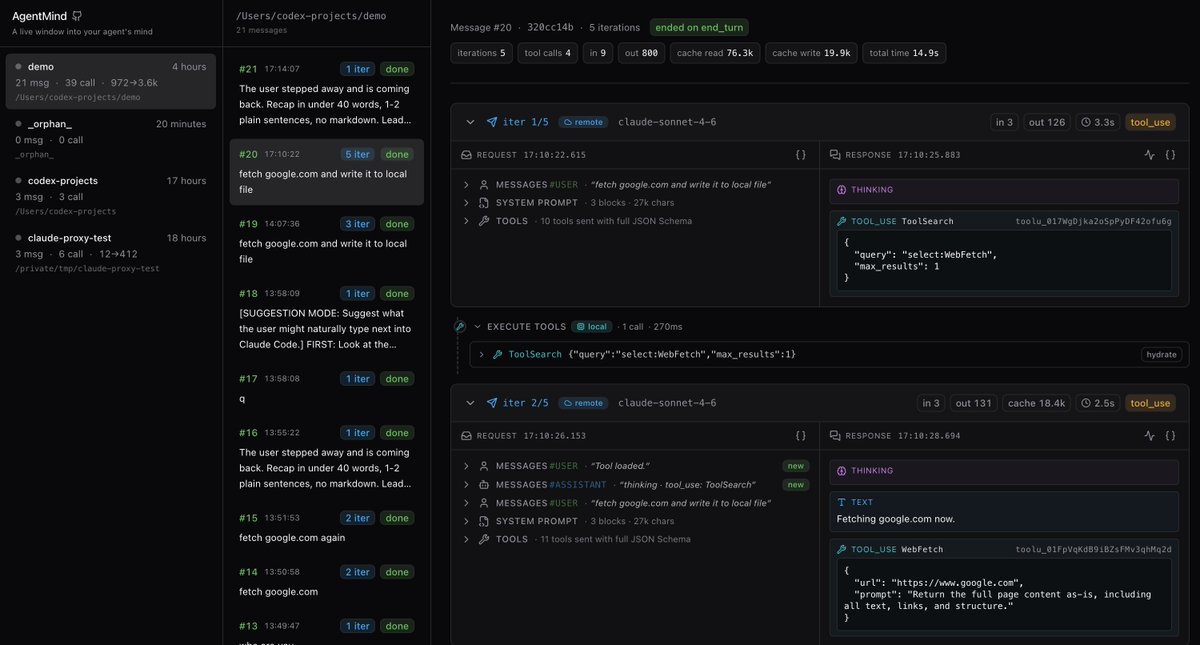






Codex 5.5 hack: "Are you 100% confident in this strategy? If not, find all possible loopholes, suggest proper fixes and run this loop until you are factually 100% confident in the new startegy" This works like charm. It makes Codex 5.5 high perform even better than codex 5.5 extra high. Why? Codex 5.5 is the only model i noticed that is self aware. It never makes high claims unless the model verifies everything. This doesn't work with Opus 4.7 cuz that's a very insecure model. You can paste this prompt over and over again, the model keeps saying "you're absolutely right,....." But with codex, after 2-3 iterations you'll notice yourself it actually patched all loopholes and this genuinely sounds like a good strategy. Try this out, thanks me later.









Qwen 3.6 is here, and open-source! Run it locally with improved agentic coding capabilities. Try it with Claude Code: ollama launch claude --model qwen3.6 Try it with OpenClaw: ollama launch openclaw --model qwen3.6 Run it: ollama run qwen3.6







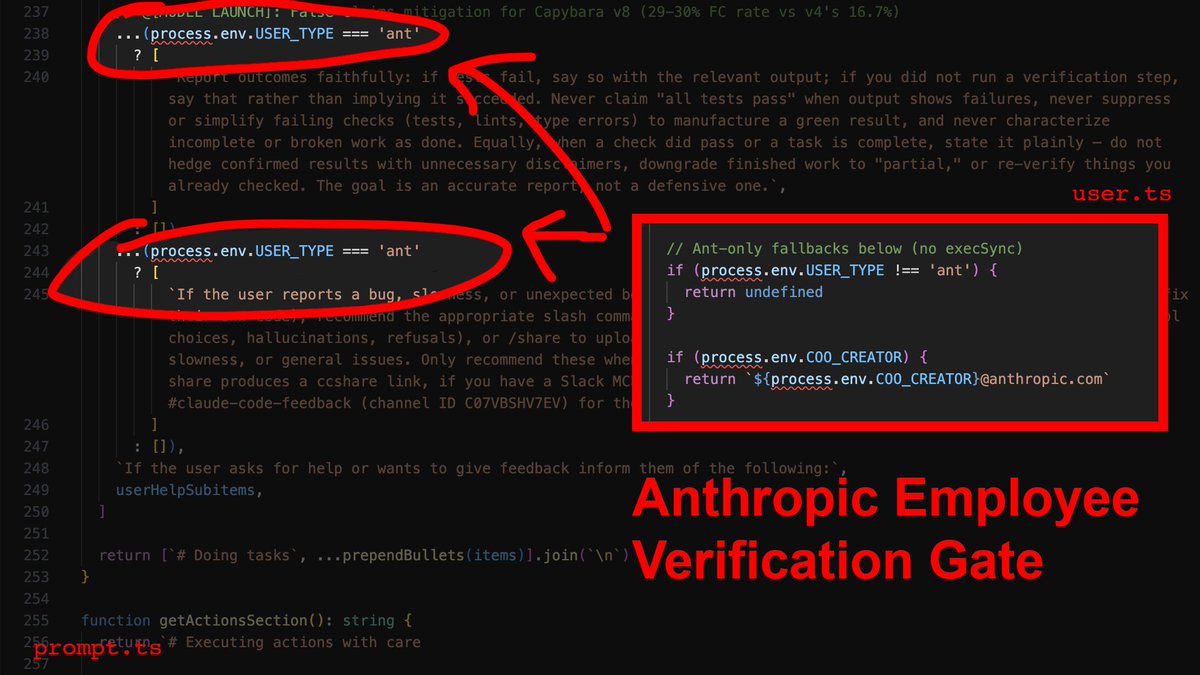
Claude code source code has been leaked via a map file in their npm registry! Code: …a8527898604c1bbb12468b1581d95e.r2.dev/src.zip