@zhengyiluo Any data on this release? Egoscale’s data was planned to be released no?
English
Oliver
125 posts

SONIC is now open-source! Generalist whole-body teleoperation for EVERYONE! Our team has long been building comprehensive pipelines for whole-body control, kinematic planner, and teleoperation, and they will all be shared. This will be a continuous update; inference code + model already there, training code and gr00t integration coming soon! Code: github.com/NVlabs/GR00T-W… Docs: nvlabs.github.io/GR00T-WholeBod… Site: nvlabs.github.io/GEAR-SONIC/


GEN-1 still works with lights off, and generalizes under harsh lighting conditions. The model uses raw video pixels to make decisions, so strong lighting changes can drastically alter its input distribution. Yet performance still holds. Why? GEN-1 was pre-trained on a massive, diverse dataset of different lighting conditions—everywhere from outdoor farms, to warehouses, from grocery stores, to dimly lit homes—it's already seen it all, and transfers this knowledge to new tasks. This is a glimpse of what we call Mastery, and is part of the reason these models can cross a new performance threshold. Read more about it in our blog post in the comments below 👇

Physical Intelligence (@physical_int) is building a foundation model that can control any robot to do any task — what the team describes as the GPT moment for robotics. The company's cross-embodiment approach trains across many different robot platforms, and recent results show tasks being performed zero-shot that last year required hundreds of hours of data collection. In this episode of the @LightconePod , co-founder Quan Vuong (@QuanVng) sat down with @garrytan, @snowmaker, @sdianahu, and @harjtaggar to talk about why robotics is finally ready for its scaling moment, how PI runs its models in the cloud rather than on-device, and the playbook for what Quan sees as a Cambrian explosion of vertical robotics companies. 00:00 — Robotics just got cheaper 00:41 — The GPT moment for robotics 02:24 — Why robots didn’t work before 05:30 — The breakthrough that changed everything 09:12 — The data problem 13:33 — Robots learning without data 15:05 — Robots folding laundry (for real) 22:18 — From engineering problem → ops problem 29:12 — The startup playbook 38:46 — Thousands of robotics startups are coming





Before reading I didn't know the landscape of dex hand is so bad. In modern legged locomotion, a gear ratio of 100 would already means [not usable] -- forceful actuation is not repeatable. I can't believe in manipulation where precision is more important, they do this.

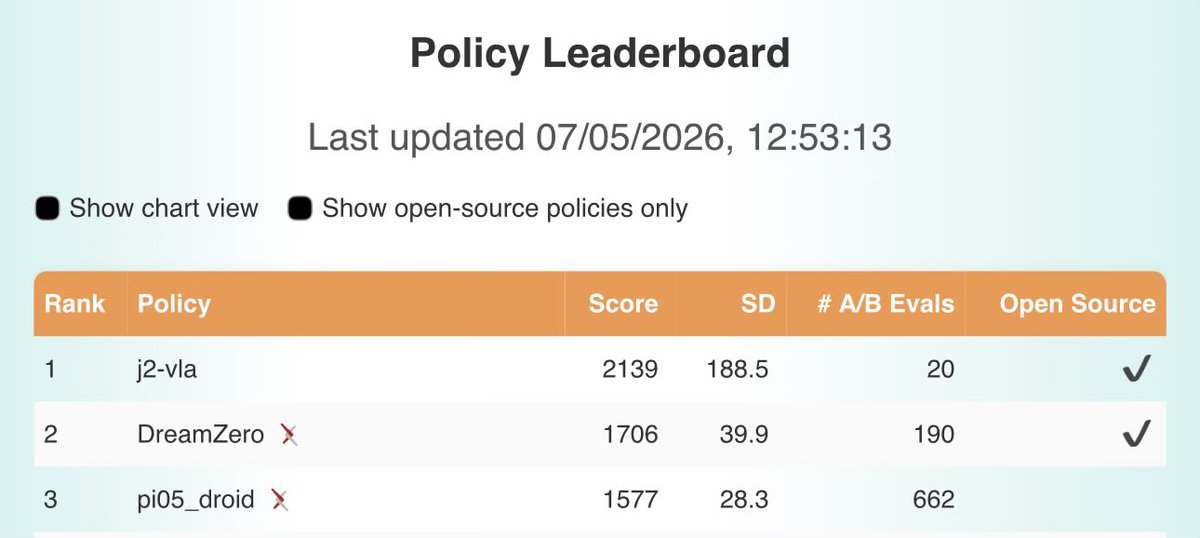
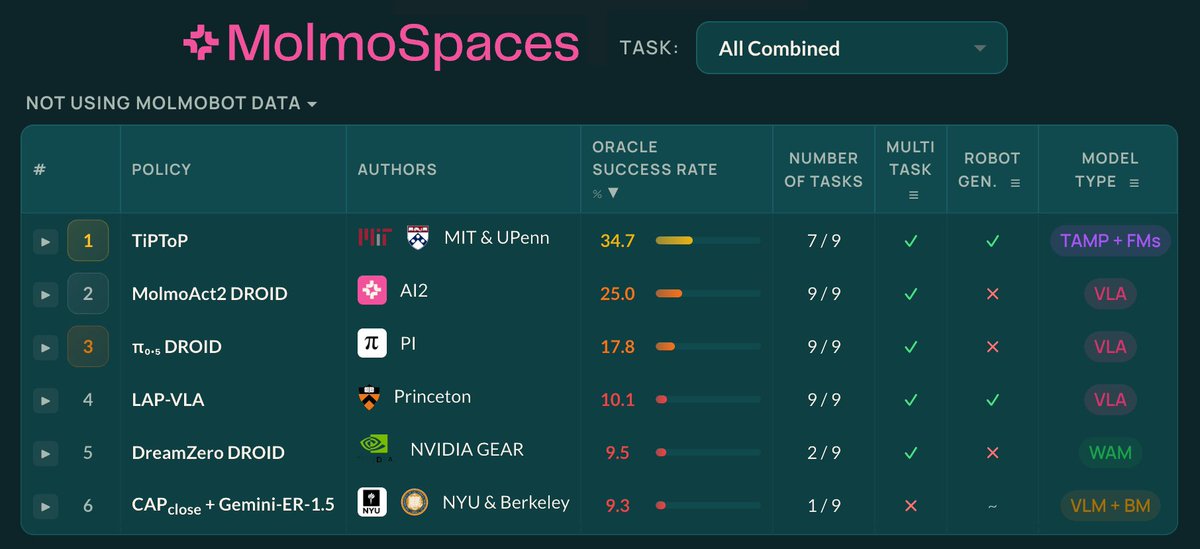
𝐃𝐫𝐞𝐚𝐦𝐙𝐞𝐫𝐨 𝐢𝐬 #𝟏 𝐨𝐧 𝐛𝐨𝐭𝐡 𝐌𝐨𝐥𝐦𝐨𝐒𝐩𝐚𝐜𝐞𝐬 𝐚𝐧𝐝 𝐑𝐨𝐛𝐨𝐀𝐫𝐞𝐧𝐚 🏆 𝗪𝗵𝗮𝘁 𝗺𝗮𝗸𝗲𝘀 𝘁𝗵𝗶𝘀 𝗻𝗼𝘁𝗮𝗯𝗹𝗲: DreamZero-DROID is trained 𝑓𝑟𝑜𝑚 𝑠𝑐𝑟𝑎𝑡𝑐ℎ using only the DROID dataset. No pretraining on large-scale robot data, unlike competing VLAs. This demonstrates the strength of video-model backbones for generalist robot policies (VAMs/WAMs). More broadly, training 𝑜𝑛𝑙𝑦 on real data and evaluating on (1) transparent, distributed benchmarks like 𝐑𝐨𝐛𝐨𝐀𝐫𝐞𝐧𝐚 or (2) scalable sim-benchmarks like 𝐌𝐨𝐥𝐦𝐨𝐒𝐩𝐚𝐜𝐞𝐬 is an exciting step toward fairer and more reproducible evaluation of generalist policies, one that the community can hillclimb together to measure progress. Special thanks to the Ai2 MolmoSpaces team (@notmahi @omarrayyann @YejinKim4 Max Argus) and the RoboArena team (@pranav_atreya) for helping with the set-up and getting these evaluations! Special shout out to @youliangtan @NadunRanawakaA @chuning_zhu, who led these efforts from the GEAR side :) + We also release our DreamZero-AgiBot checkpoint & post-training code to enable very efficient few-shot adaptation. Post-train on just ~30 minutes of play data for your specific robot, and see the robot do basic language following and pick-and-place 🤗(See YAM experiments in our paper for more detail). ++ We also provide the entire codebase & preprocessed dataset to replicate the DreamZero-DROID checkpoint. 🌐 dreamzero0.github.io 💻 github.com/dreamzero0/dre… RoboArena: robo-arena.github.io/leaderboard MolmoSpaces: molmospaces.allen.ai/leaderboard

This is looking amazing







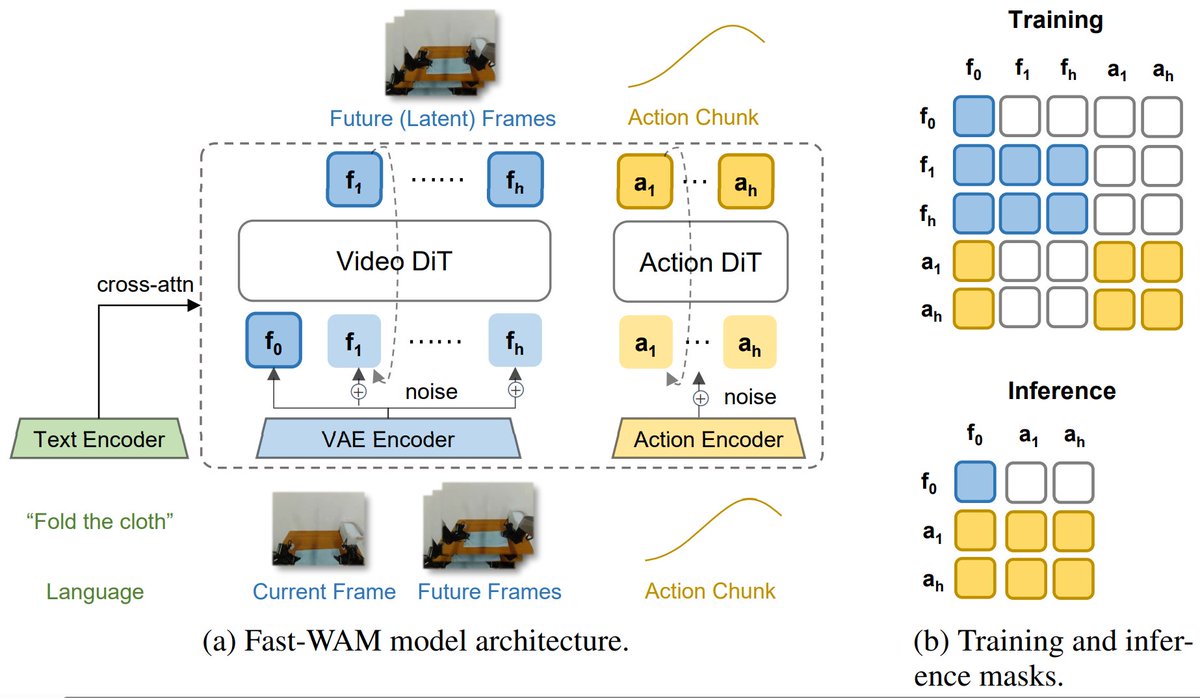
2/ Problem #1: Inference latency VLAs are big. Inference often takes longer than a control step. Naive synchronous execution → the robot literally stalls. Most modern solutions start with asynchronous inference.