IanZ retweetledi

IanZ
663 posts


@ZanIReverse
Crypto & SaaS & AI / Digitization of the world


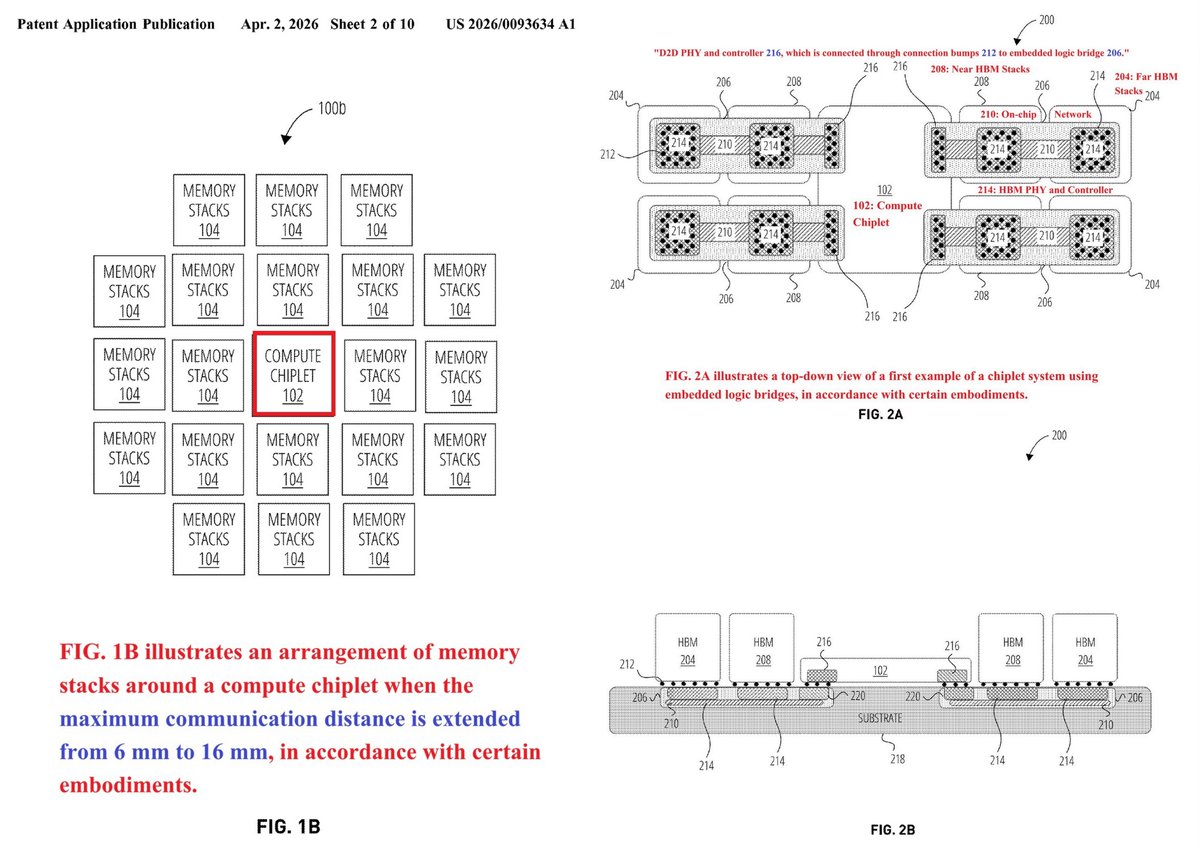
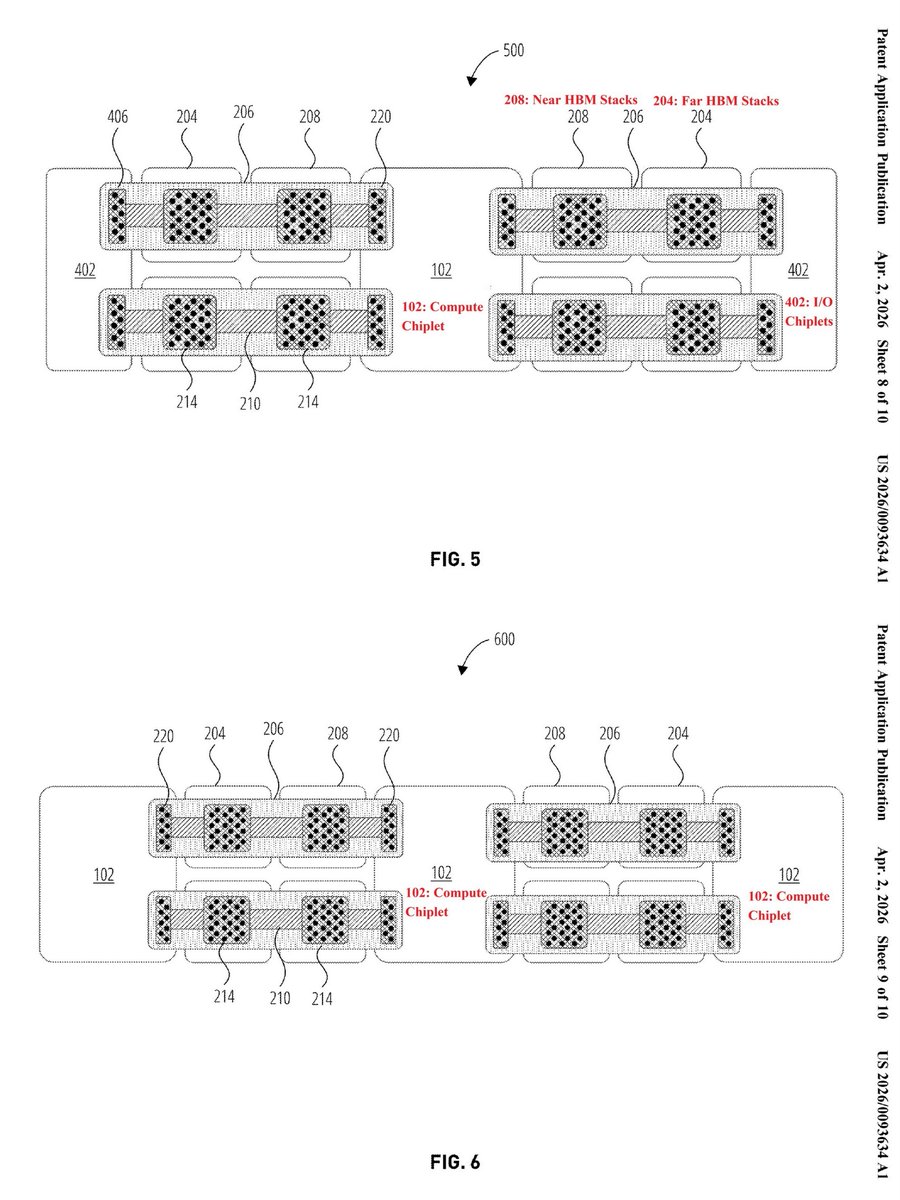

"High Bandwidth Memory Buffer Bridge Die in Routing Substrate", Apple, Appl (P: Mar 2024) patents.google.com/patent/US20250… Scalable System on a Chip, Mar 2024 (P: Aug 2021) x.com/ogawa_tter/sta… <= Optics-Based Distributed Unified Memory System, (P: Sep 2023) x.com/ogawa_tter/sta…

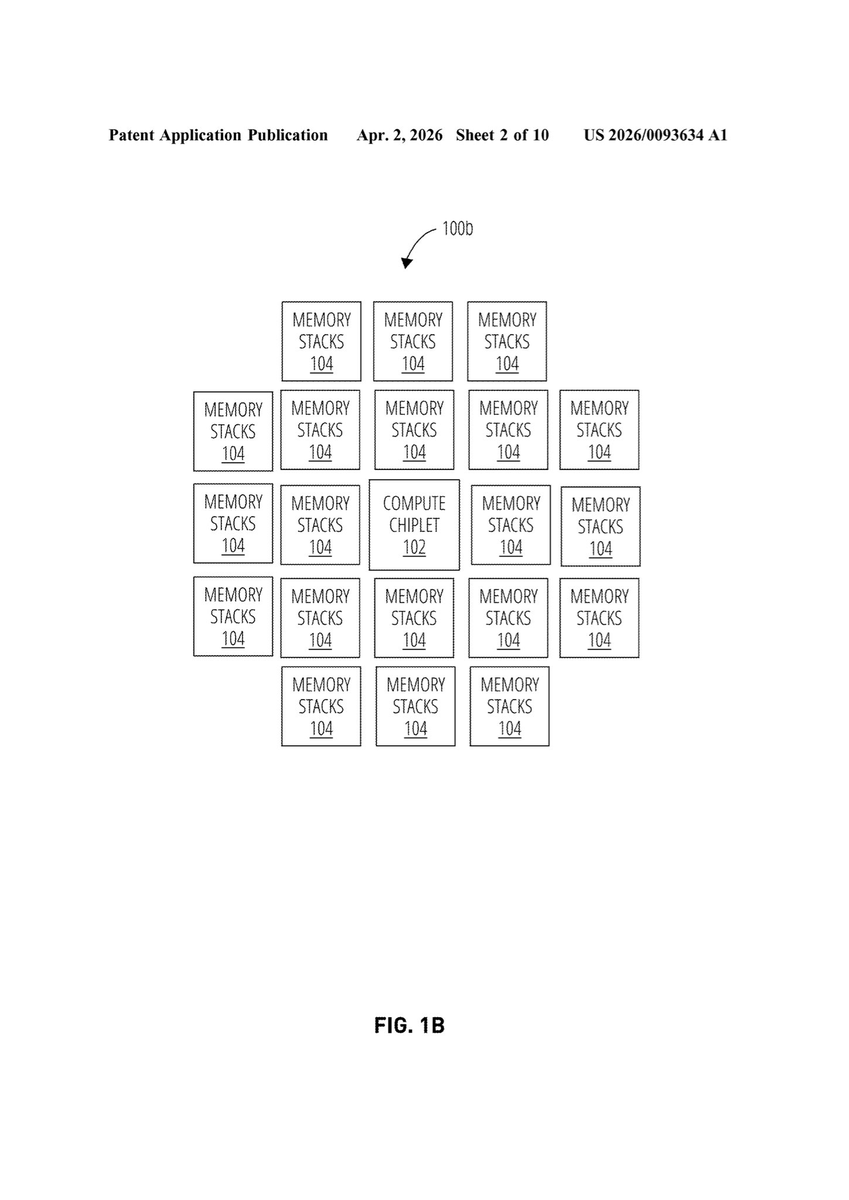
이번주에 공개된 특허 중 OpenAI의 칩 구조 특허가 있었네요. HBM 떡칠이라니 ... 이게 뭔가요. 🤣🤣🤣 아니다, 대한민국 국민으로서는 OpenAI가 칩에서 꼭 성공하기를 빌어야겠네요. 컴퓨터 유닛 하나당 HBM가 몇 개야 ... 🤣🤣🤣 @jukan05 @Semicon_player

the community notes COOKED anthropic 😭😭

@EthanLipnik 👋 Early versions of Claude Code used RAG + a local vector db, but we found pretty quickly that agentic search generally works better. It is also simpler and doesn’t have the same issues around security, privacy, staleness, and reliability.



I'm Boris and I created Claude Code. I wanted to quickly share a few tips for using Claude Code, sourced directly from the Claude Code team. The way the team uses Claude is different than how I use it. Remember: there is no one right way to use Claude Code -- everyones' setup is different. You should experiment to see what works for you!




Gemini 3 Pro is the new leader in AI. Google has the leading language model for the first time, with Gemini 3 Pro debuting +3 points above GPT-5.1 in our Artificial Analysis Intelligence Index @GoogleDeepMind gave us pre-release access to Gemini 3 Pro Preview. The model outperforms all other models in Artificial Analysis Intelligence Index. It demonstrates strength across the board, coming in first in 5 of the 10 evaluations that make up Intelligence Index. Despite these intelligence gains, Gemini 3 Pro Preview shows improved token efficiency from Gemini 2.5 Pro, using significantly fewer tokens on the Intelligence Index than other leading models such as Kimi K2 Thinking and Grok 4. However, given its premium pricing ($2/$12 per million input/output tokens for <200K context), Gemini 3 Pro is among the most expensive models to run our Intelligence Index evaluations. Key takeaways: 📖 Leading intelligence: Gemini 3 Pro Preview is the leading model in 5 of 10 evals in the Artificial Analysis Intelligence Index, including GPQA Diamond, MMLU-Pro, HLE, LiveCodeBench and SciCode. Its score of 37% on Humanity’s Last Exam is particularly impressive, improving on the previous best model by more than 10 percentage points. It also is leading in AA-Omniscience, Artificial Analysis’ new knowledge and hallucination evaluation, coming first in both Omniscience Index (our lead metric that takes off points for incorrect answers) and Omniscience Accuracy (percentage correct). Given that factual recall correlates closely with model size, this may point to Gemini 3 Pro being a much larger model than its competitors 💻 Advanced coding and agentic capabilities: Gemini 3 Pro Preview leads two of the three coding evaluations in the Artificial Analysis Intelligence Index, including an impressive 56% in SciCode, an improvement of over 10 percentage points from the previous highest score. It is also strong in agentic contexts, achieving the second highest score in Terminal-Bench Hard and Tau2-Bench Telecom 🖼️ Multimodal capabilities: Gemini 3 Pro Preview is a multi-modal model, with the ability to take text, images, video and audio as input. It scores the highest of any model on MMMU-Pro, a benchmark that tests reasoning abilities with image inputs. Google now occupies the first, third and fourth position in our MMMU-Pro leaderboard (with GPT-5.1 taking out second place just last week) 💲Premium Pricing: To measure cost, we report Cost to Run the Artificial Analysis Intelligence Index, which combines input and output token prices with token efficiency to reflect true usage cost. Despite the improvement in token efficiency from Gemini 2.5 Pro, Gemini 3 Pro Preview costs more to run. Its higher token pricing of $2/$12 USD per million input/output tokens (≤200k token context) results in a 12% increase in the cost to run the Artificial Analysis Intelligence Index compared to its predecessor, and the model is among the most expensive to run on our Intelligence Index. Google also continues to price long context workloads higher than lower context workloads, charging $4/$18 per million input/output tokens for ≥200k token context. ⚡ Speed: Gemini 3 Pro Preview has comparable speeds to Gemini 2.5 Pro, with 128 output tokens per second. This places it ahead of other frontier models including GPT-5.1 (high), Kimi K2 Thinking and Grok 4. This is potentially supported by Google’s first-party TPU accelerators Other details: Gemini 3 Pro Preview has a 1 million token context window, and includes support for tool calling, structured outputs, and JSON mode See below for further analysis









I quite like the new DeepSeek-OCR paper. It's a good OCR model (maybe a bit worse than dots), and yes data collection etc., but anyway it doesn't matter. The more interesting part for me (esp as a computer vision at heart who is temporarily masquerading as a natural language person) is whether pixels are better inputs to LLMs than text. Whether text tokens are wasteful and just terrible, at the input. Maybe it makes more sense that all inputs to LLMs should only ever be images. Even if you happen to have pure text input, maybe you'd prefer to render it and then feed that in: - more information compression (see paper) => shorter context windows, more efficiency - significantly more general information stream => not just text, but e.g. bold text, colored text, arbitrary images. - input can now be processed with bidirectional attention easily and as default, not autoregressive attention - a lot more powerful. - delete the tokenizer (at the input)!! I already ranted about how much I dislike the tokenizer. Tokenizers are ugly, separate, not end-to-end stage. It "imports" all the ugliness of Unicode, byte encodings, it inherits a lot of historical baggage, security/jailbreak risk (e.g. continuation bytes). It makes two characters that look identical to the eye look as two completely different tokens internally in the network. A smiling emoji looks like a weird token, not an... actual smiling face, pixels and all, and all the transfer learning that brings along. The tokenizer must go. OCR is just one of many useful vision -> text tasks. And text -> text tasks can be made to be vision ->text tasks. Not vice versa. So many the User message is images, but the decoder (the Assistant response) remains text. It's a lot less obvious how to output pixels realistically... or if you'd want to. Now I have to also fight the urge to side quest an image-input-only version of nanochat...







今儿应该是被这个刷屏了 - @the_nof1 目前Deepseek遥遥领先! 讲真这比去年Goat/Ai16Z时代的AI Meme给人的“感知感”强太多了,AI X Crypto 终于找到了正确的打开方式?😂 而且你进去看人家每个策略都是有止盈止损点位或者条件的(比如图中Deepseek的ETH 10倍多策略),我一向不提倡玩合约,但你真要玩,也跟人家AI学习下,设置好止盈止损条件再开单不是? 目前几个AI普遍多头为主,好奇过两天市场要是跌一波这些AI的表现会如何……这已经不光是AI之间的PK,也是AI跟咱们这些人类Trader之间的PK(你难道心里不憋着一口气要跑赢他们?)。如果时间线拉长,发现咱们绝大多数人P不过AI,币圈以后的发展方向会不会Cex和Dex上只剩一堆AI策略在P,人类P小将日渐凋零?AI现在连炒币这个“工作”都要从人类这里抢走么?!😱