Jielin Qiu retweetledi

Today I finally get to share something our team has been quietly grinding on for months – we've created an 𝗼𝗽𝗲𝗻 𝘀𝗼𝘂𝗿𝗰𝗲𝗱 𝘃𝗲𝗿𝘀𝗶𝗼𝗻 𝗼𝗳 Cursor 𝗕𝗲𝗻𝗰𝗵 @cursor_ai .
If you’ve been following Cursor’s Composer launch and their internal "Cursor Bench" for testing vibe coding models, you can think of our 𝗟𝗖𝗕𝗔 𝗯𝗲𝗻𝗰𝗵 as the open-source, model-agnostic counterpart.
Here is what we provide by @SFResearch . With 𝗟𝗖𝗕𝗔 𝗯𝗲𝗻𝗰𝗵 we:
• Ship a 𝗖𝘂𝗿𝘀𝗼𝗿-𝘀𝘁𝘆𝗹𝗲 𝗮𝗴𝗲𝗻𝘁 𝘀𝘁𝗮𝗰𝗸: ReAct loop, semantic @ codebase search, grep, file read/write, refactor tools, and a three-tier memory system inspired by production coding assistants like Cursor.
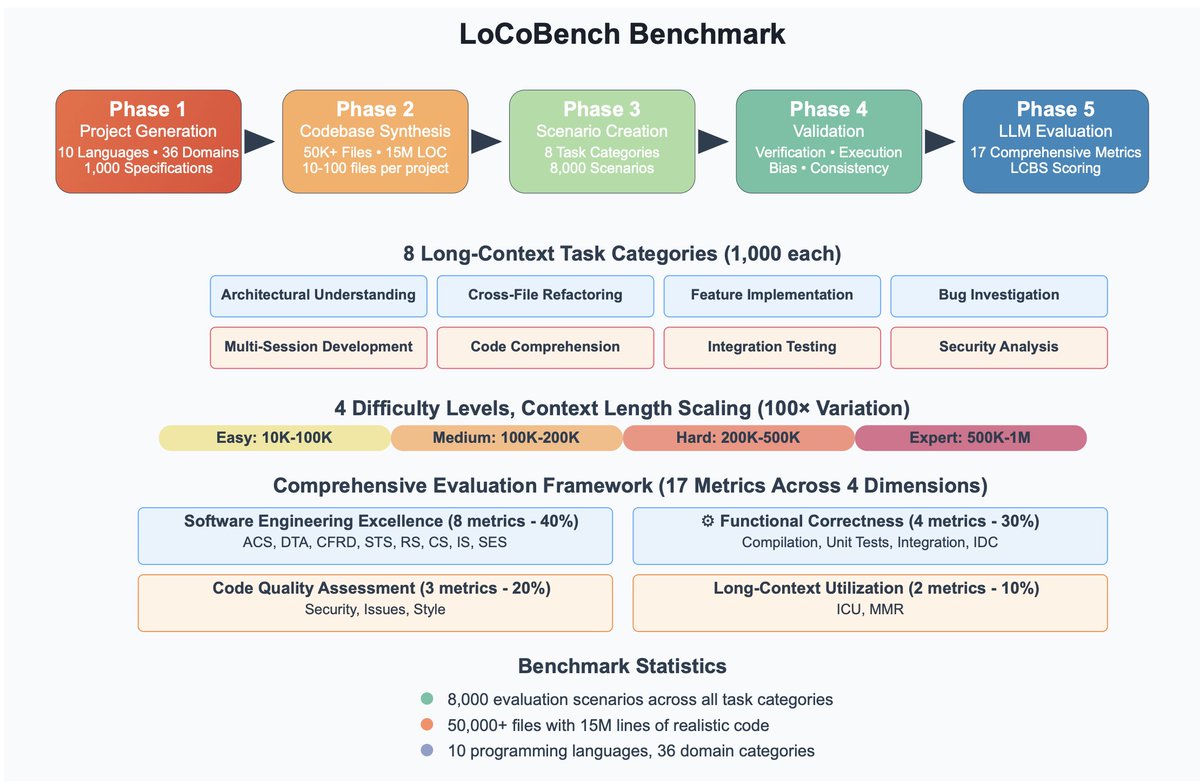
• 𝗧𝗮𝗸𝗲 𝟴,𝟬𝟬𝟬 𝗿𝗲𝗮𝗹-𝘄𝗼𝗿𝗹𝗱 𝘃𝗶𝗯𝗲 𝗰𝗼𝗱𝗶𝗻𝗴 𝘀𝗰𝗲𝗻𝗮𝗿𝗶𝗼𝘀 and turn them into interactive agent gyms across 10 languages and 10K–1M token codebases.
• Let you plug in any model (GPT-5, Claude Sonnet 4.5, Gemini 2.5 Pro, etc.) and see how it actually behaves on long, messy, multi-turn coding tasks.
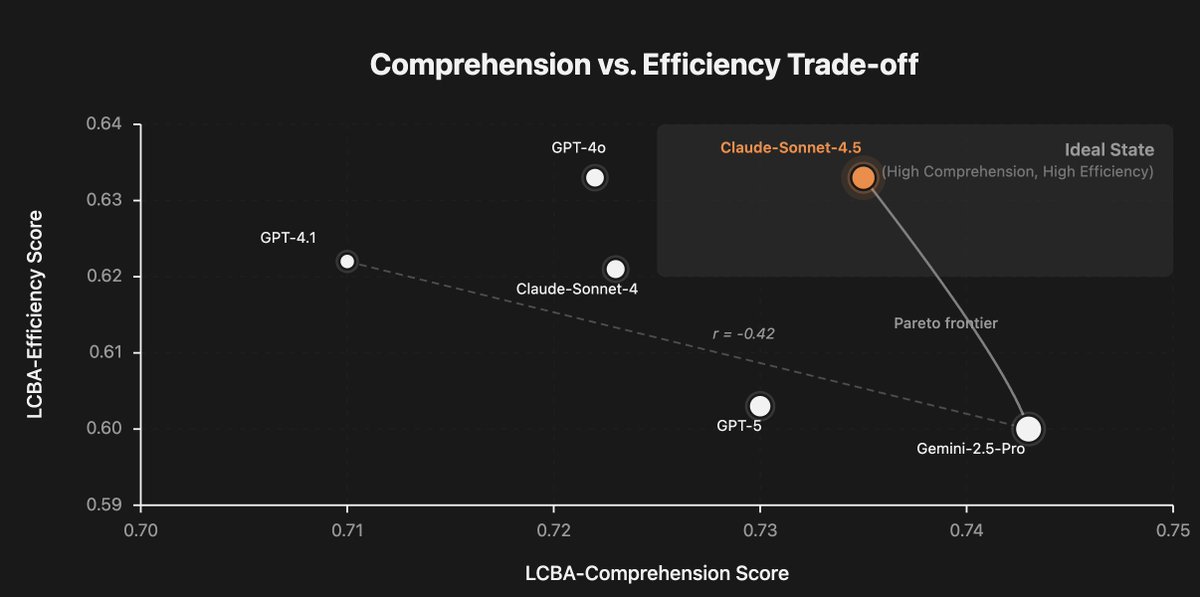
A few fun findings: Cursor-style agents with context management are surprisingly robust at 1M-token contexts, but there’s a hard trade-off between deep exploration vs. efficiency — no one frontier model sits in the “perfect” top-right corner yet. Anthropic Claude 4.5 and Google Gemini 2.5 pro are at the Pareto Frontier.
Everything is open source (agent, code, scenarios, traces, metrics) on @huggingface:
📄 Tech Report: arxiv.org/pdf/2509.09614
🤖 GitHub:github.com/SalesforceAIRe…
🤗 Dataset: huggingface.co/datasets/jason…
If you’re building coding agents, benchmarking your model against GPT/Claude/Gemini, or want to train your coding agents with RL in real coding environments, we’d love for you to try LCBA bench, and tell us your findings!
English