Aleix Conchillo Flaqué retweetledi

NVIDIA Nemotron 3 Super launches today! We've been building voice agents with Super's pre-release checkpoints and running all our various tests and benchmarks.
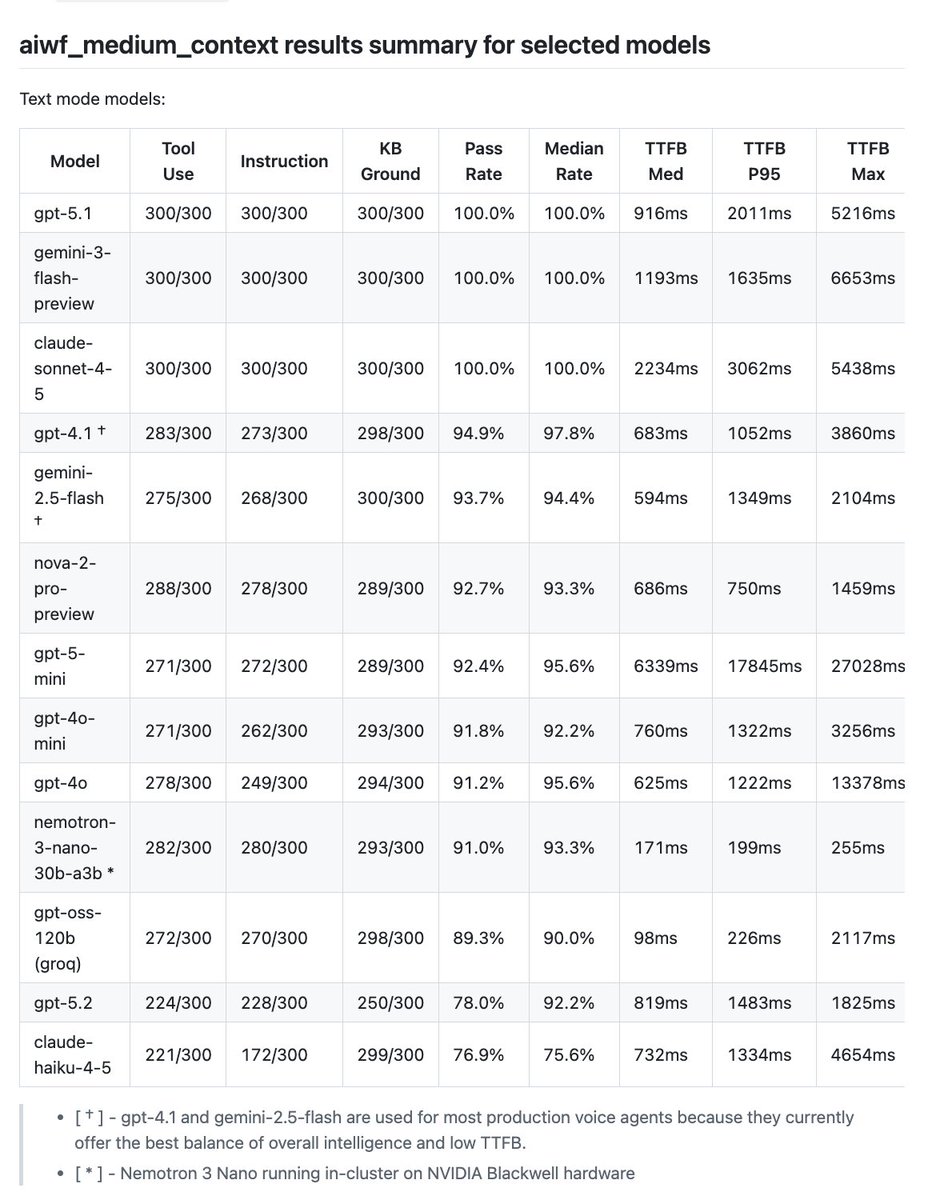
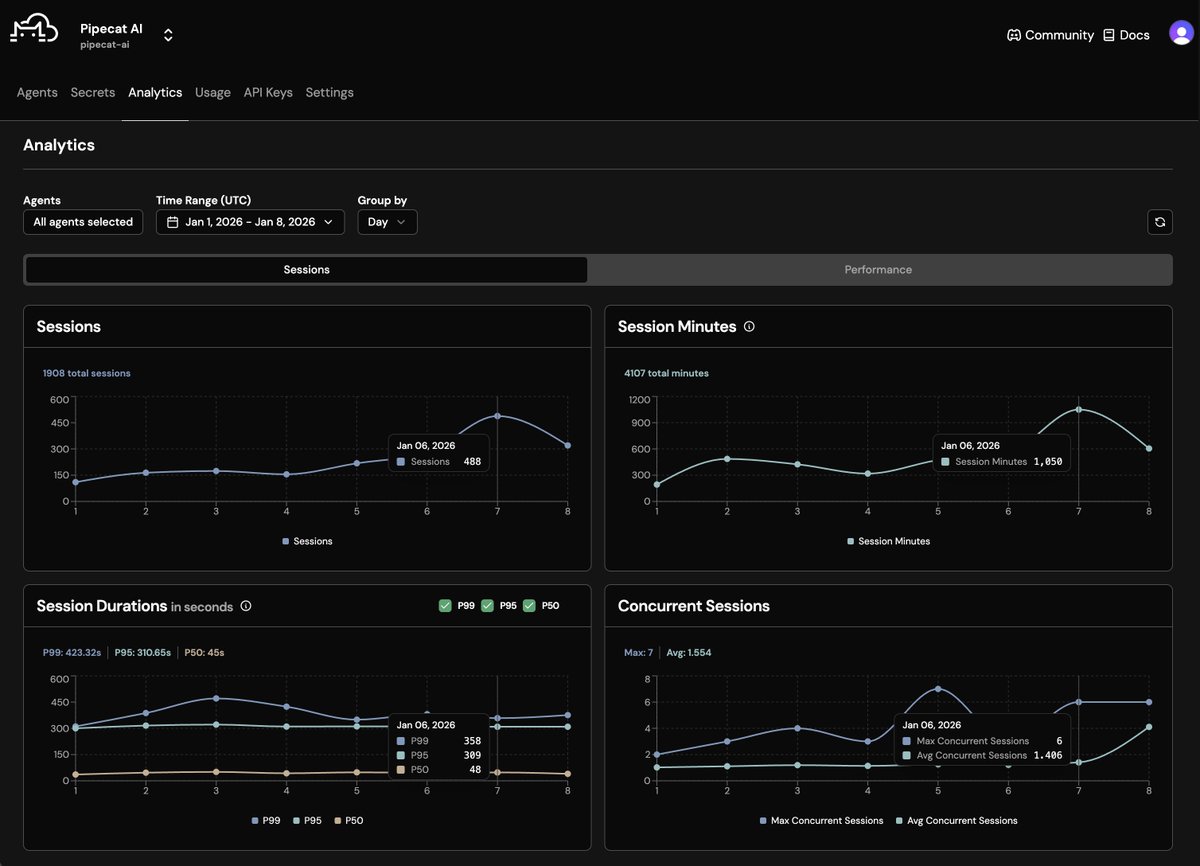
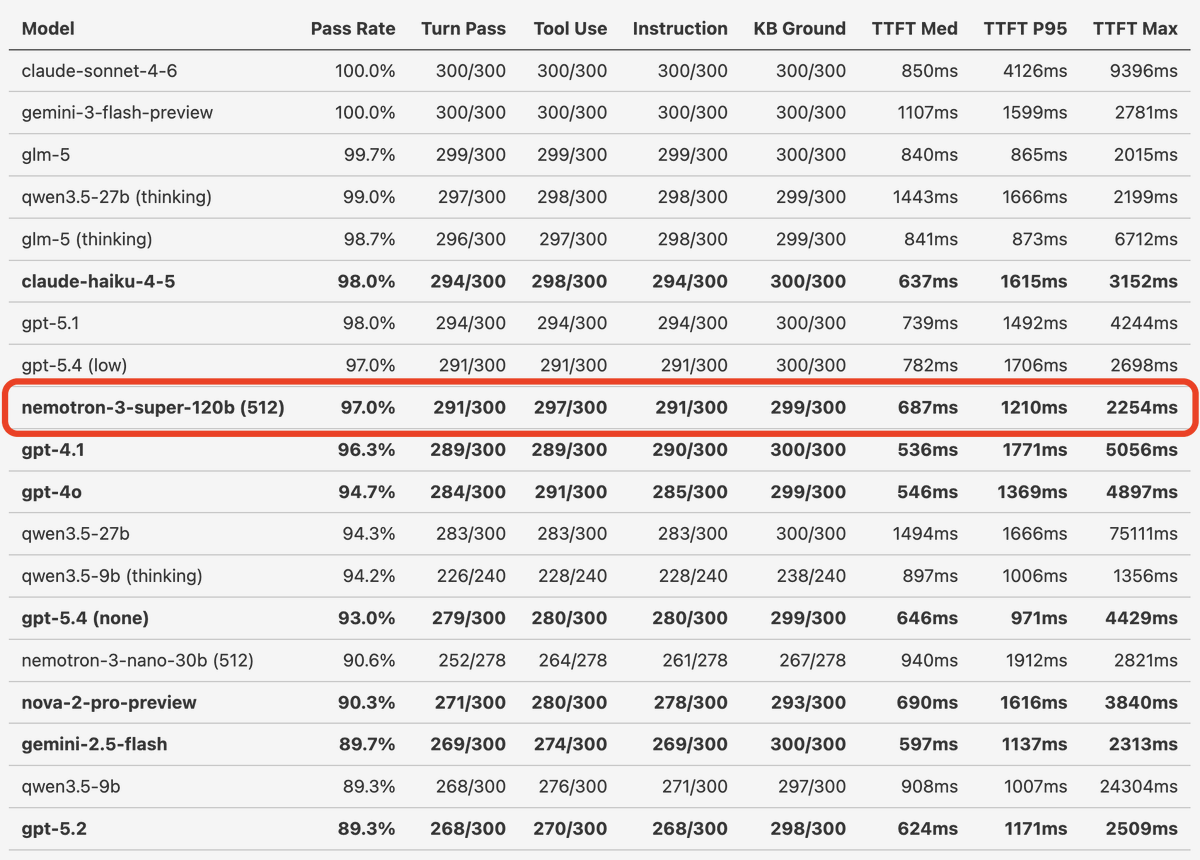
Nemotron 3 Super matches both GPT-5.4 and GPT-4.1 in tool calling and instruction following performance on our realtime conversation, long context, real-world benchmarks. GPT-4.1 is the most widely used LLM today for production voice agents. So an open model that performs as well as GPT-4.1 on hard, voice-specific benchmarks is a big deal.
(Side note: we don't think a benchmark "tells the story" about a model's voice agent performance unless it tests model correctness across at least 20 human/agent conversation turns.)
The Nemotron models are *fully* open: weights, data sets, training code, inference code.
Nemotron 3 Super is 120B params, with a hybrid Mamba-Transformer MoE architecture for efficient inference. You can run it on NVIDIA data center hardware or on a DGX Spark mini-desktop machine.
1M token context.
Blog post with full benchmarks, thinking budget notes, inference setup on @Modal, and where we think this goes next. 👇
English