
Felipe Oviedo
996 posts

Felipe Oviedo
@ands_zen
AI in science and engineering @microsoft @mit @cern
NYC Katılım Aralık 2019
6.6K Takip Edilen667 Takipçiler

@ands_zen @aakashgupta Are you mentally disabled? Why would you root against someone trying to do stuff to make people's lives better. You capitalism bootlicker turdnugget
English

The mayor of the largest city in America walked 6 miles home from work last night and nobody found it unusual.
That sentence would have been absurd 18 months ago when the last NYC mayor was under federal indictment. The city went from an FBI investigation at Gracie Mansion to a guy who took his oath in an abandoned subway station at midnight, paid the $9 filing fee in cash from his jacket pocket, and walks home because that's what he does.
100 days in. 56% of New Yorkers say the city is headed in the right direction, up from 31% a year ago. That's a 25-point swing. The budget is $116 billion. Companies are threatening to leave over his tax proposals. Half the city council thinks he's moving too fast.
And he walked home.
Pop Base@PopBase
Zohran Mamdani walked 6 miles home last night from the New York City Hall to round out his first 100 days in office.
English
@hanzheng_7 @karpathy @ao_qu18465 @BobbyZhouZijian @bryanklow @pliang279 @wucathy Great work! Very cool.
English

🚀The era of autonomous multi-agent discovery is arriving! @karpathy
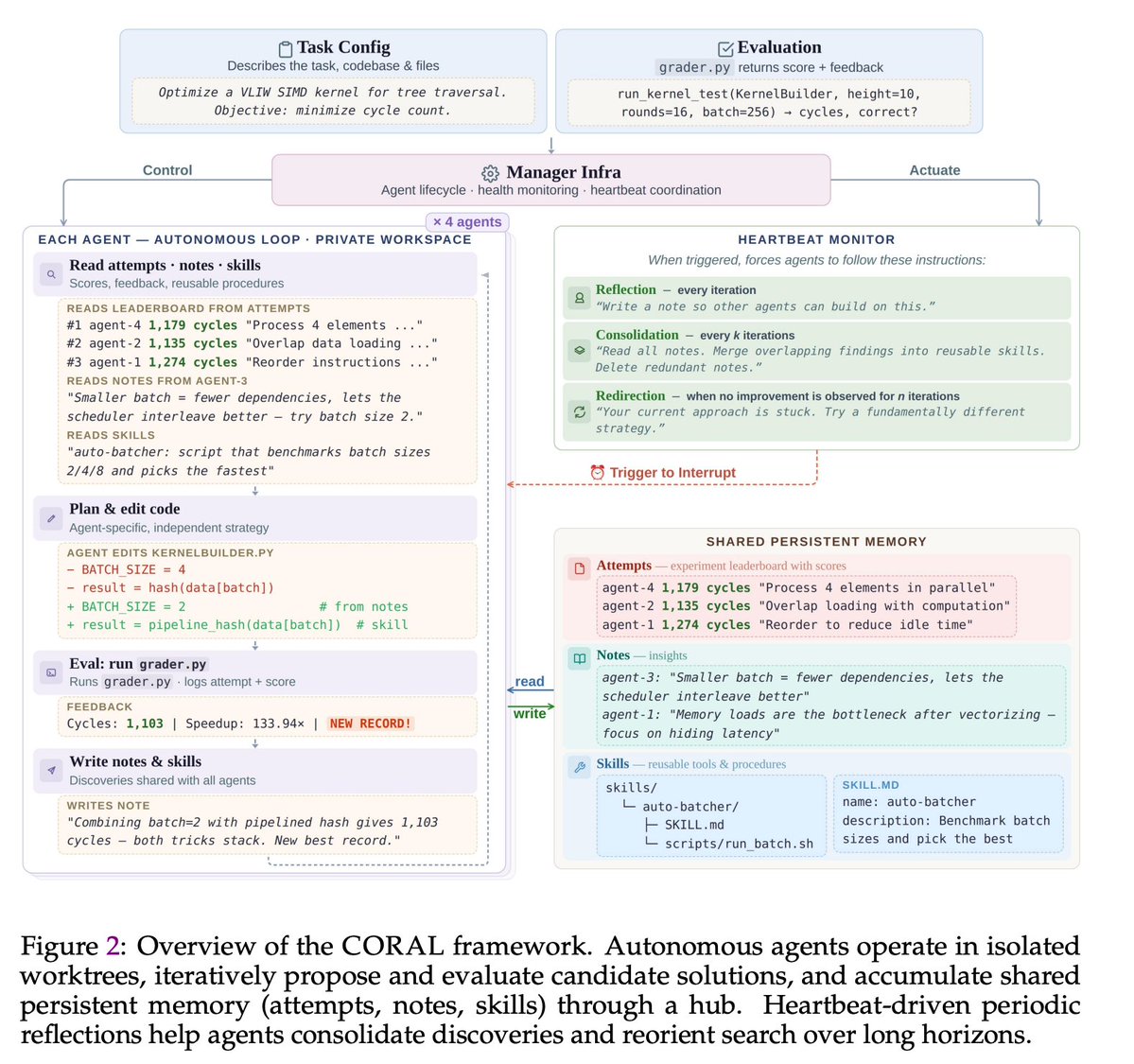
🪸Excited to share CORAL, our new work on autonomous multi-agent systems for open-ended scientific discovery.
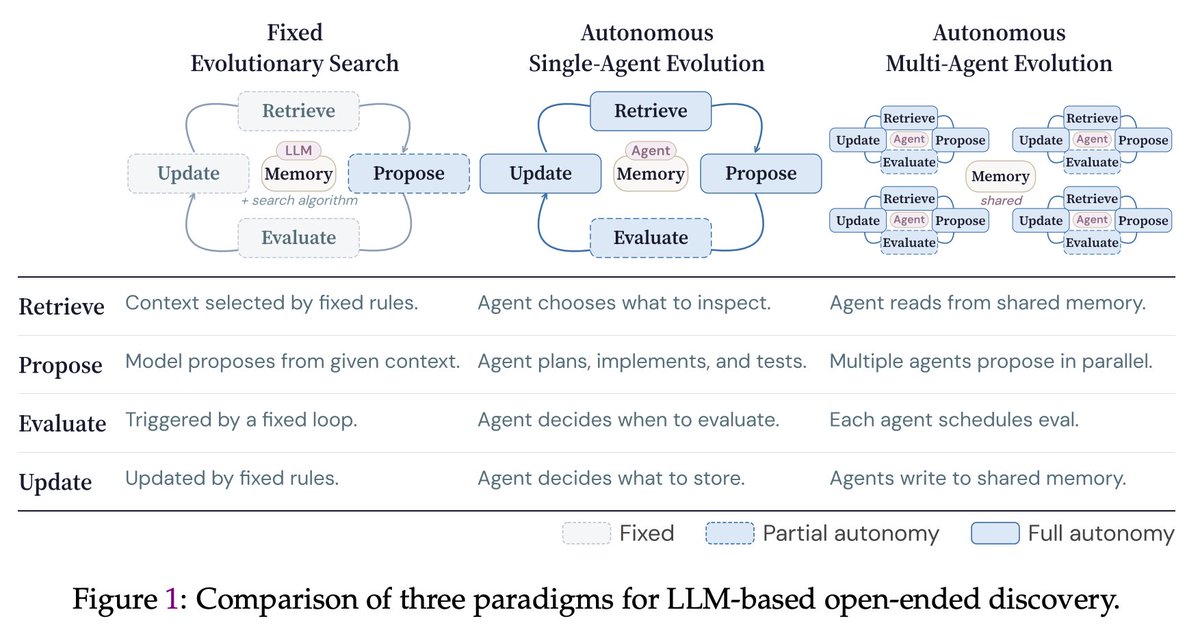
🙅♂️A key limitation of many current “self-evolving” frameworks is that agents still operate inside tightly constrained loops — they mutate solutions, but they do not truly decide how to explore.
In CORAL, we push toward genuine autonomy:
Agents decide
🔍 what to explore
🧠 what knowledge to store
♻️ which ideas to reuse
🧪 when to test hypotheses
🔥One of the most interesting findings:
A single autonomous agent already outperforms fixed evolutionary search, but the biggest gains emerge when multiple agents form a research community.
💪Over 50% of breakthroughs in multi-agent runs come from building on other agents’ discoveries. This suggests that knowledge reuse and collaboration are central to scalable automated discovery.
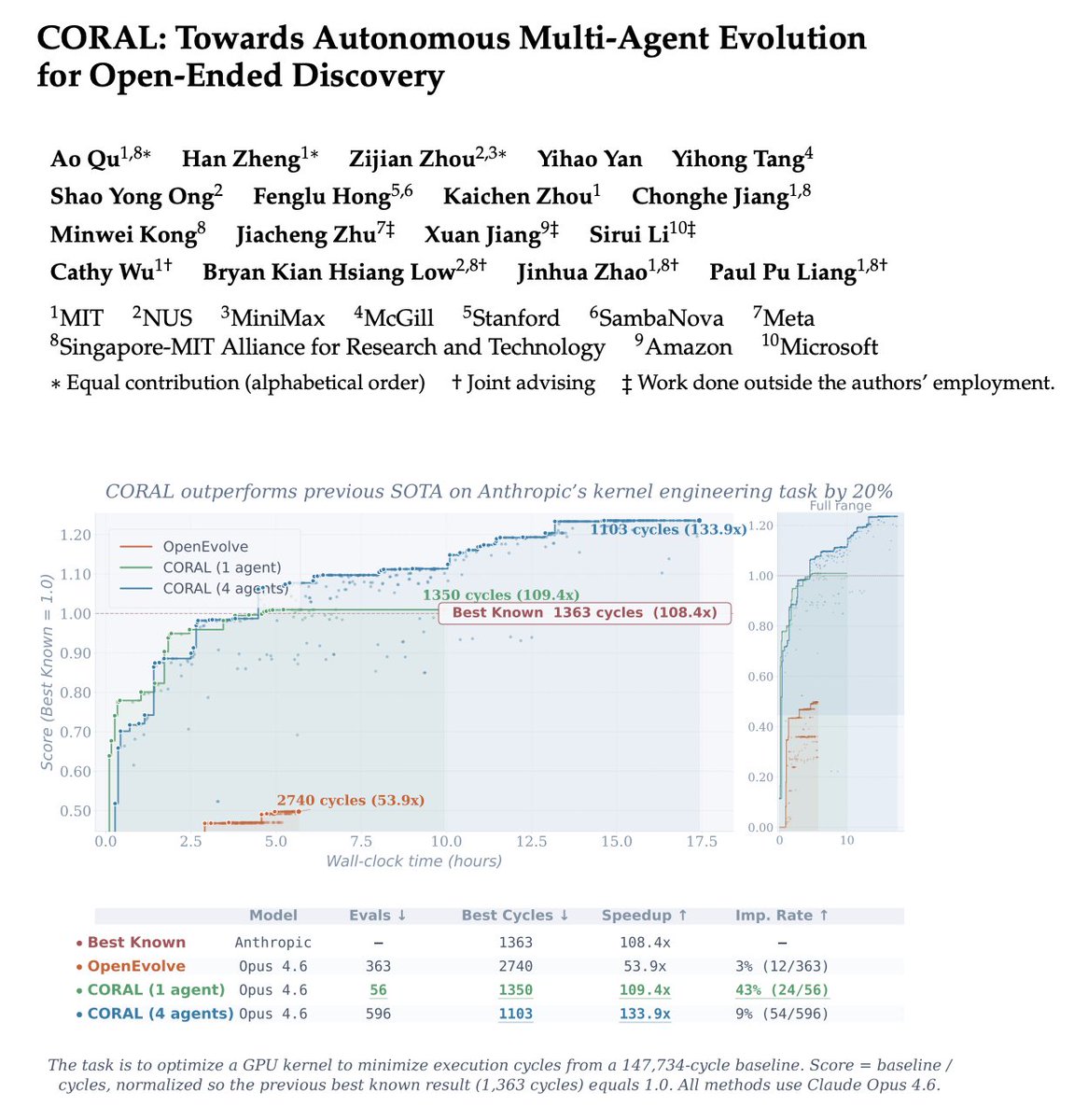
🏅Across 10+ difficult tasks in algorithmic discovery and system optimization, CORAL achieves state-of-the-art performance while improving efficiency by 3–10×.
📄 Paper: arxiv.org/abs/2604.01658…
💻 Code: github.com/Human-Agent-So…
💡AlphaXiv: alphaxiv.org/abs/2604.01658
#agentic #llms #selfevolvingagent #multiagent #autoresearch #alphaevolve

English
@HillValleyForum No worries I am sure Mamdani is very business friendly 😂
English

"Our head count in Manhattan when I got to JPMorgan was 35,000 and now is 26,000. Our head count in Texas started at 11,000, now it's 33,000. That's what happens."
Jamie Dimon on why companies are leaving New York:
"Highest individual taxes, highest estate taxes, highest corporate taxes, anti-business sentiment."
"When I grew up as a kid in New York City, there were 120 of the Fortune 500 headquarters there. In the 1970s, 60 of the 120 left, including Exxon, GE, IBM, Union Carbide. They're all going to Texas."
The Hill & Valley Forum 2026
@HillValleyForum @jpmorgan @ChairmanG
English


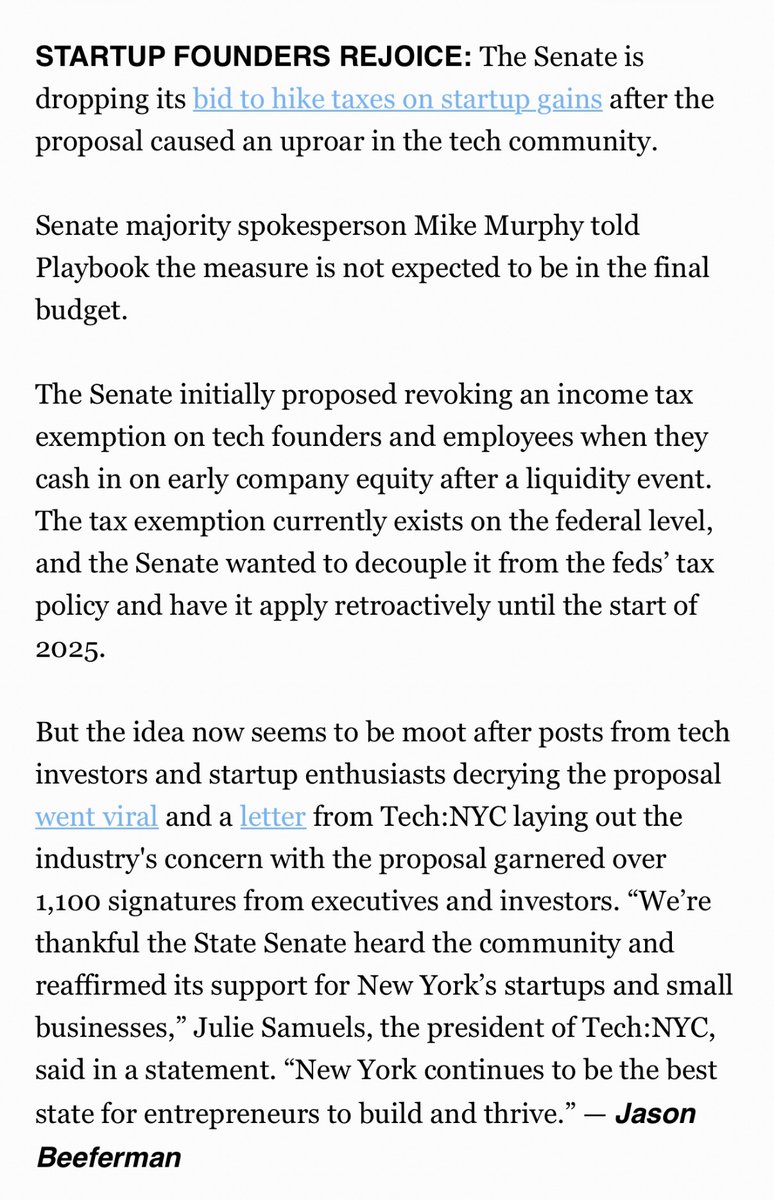
@YIMBYLAND And 1.8B no bid contract homeless in hotels… this is just marketing.
English

“The City was paying for a lot of work from outside contractors. That was costing us far too much. So we're bringing a lot of that work in house and saving our budget”
This is GOOD.
Mayor Zohran Kwame Mamdani@NYCMayor
Government must deliver for working people—and every dollar in our budget should work as hard as they do. That’s why I directed every agency to cut waste and help close our budget gap. Here’s some of what we found.
English
@Birdyword Yes, and that $4,200 in daycare is self imposed 😂 I live in the UWS and is more like 35K for daycare. Their income is twice that of the richest UWS zip code. This is upper middle class, even in Manhattan. Will be comfy once kids are in public K.
English

I hate myself for engaging with this, but: even with NYC taxes, $3900 in monthly rent, $4200 in daycare and $10k saved you've got about $110k left over for the year for everything else. The answer to "how a family of 3 lives on $500,000 on the upper west side" is "with ease"
Emma G. Fitzsimmons@emmagf
How a Family of 3 Lives on $500,000 on the Upper West Side: nytimes.com/interactive/20…
English


How a Family of 3 Lives on $500,000 on the Upper West Side: nytimes.com/interactive/20…
English
Felipe Oviedo retweetledi

In 2025, New York state permitted 37,885 homes. South Carolina permitted 45,564.
New York is almost 4× the size of South Carolina, but it built 20% less.
Median home price:
NY: $599k
SC: $376k
NY is one of the only states shrinking in population. It's a choice.
English
@NYCPublicPolicy @emmagf Mamdani already prioritized low income areas for the free 2-K. There is only some free 3-K in the UWS. I agree with you... his policies are reckless and not efficient. Not the fall of the couple the article though.
English
@NYCPublicPolicy @emmagf they pay 10-12% in income tax to the city / state, that is basically a nanny. Do not blame folks for making $ and wanted services they pay for.
English

@emmagf And why should they get access to universal childcare? They make HALF A MILLION along with several tax credits.
English

I wish someone had told me this when I started digging into diffusion language models (dLLMs) from an LLM post-training background.
I've spent the last few weeks reading across both the dLLM RL literature (d1, EGSPO, MDPO, LLaDA 1.5) and the older robotics literature on diffusion policies + RL (DPPO, Diffusion-QL, and follow-up work). What surprised me most wasn't the algorithms themselves — it was realizing that the robotics community had already worked through several of the same problems the dLLM community is hitting now.
The robotics insight — structured exploration — doesn't transfer to discrete dLLMs as directly as I initially thought, but the broader lesson does.
The multi-step denoising process isn't just an expensive way to generate tokens. It gives RL tools that autoregressive models don't have — intermediate evaluations, entropy signals, a natural coarse-to-fine hierarchy — and understanding how to use (and not break) these tools is probably one of the key challenges.
This post is me organizing what I've learned — how RL post-training works (or doesn't) with diffusion language models, what carries over from the autoregressive world, what's genuinely new, and where I'm still confused.
A Quick Intro to How dLLMs Generate
Autoregressive LLMs generate left-to-right, one token at a time, and each token choice is irreversible during generation. The probability of a sequence factorizes as a product of conditional distributions: p(x₁)·p(x₂|x₁)·p(x₃|x₁,x₂)·…
Diffusion language models generate through iterative denoising. The mainstream approach right now — masked diffusion (LLaDA, Dream, MDLM) — starts with the entire response masked, then over T denoising steps, progressively unmasks tokens.
At each step, the model predicts all masked positions simultaneously using bidirectional attention, and selectively reveals the most confident predictions. The process repeats until all tokens are unmasked.
Properties of this process matter a lot for RL
(a) No fixed generation order.
Tokens can be revealed in any order — high-confidence tokens first, uncertain ones later. This means the model can lay down the skeleton of a response early and refine details later. Think of it as coarse-to-fine generation rather than left-to-right.
(b) Complete generations at every intermediate step.
Unlike autoregressive models where you have a partial sequence mid-generation, a dLLM produces a full (noisy) output at every denoising step. This turns out to be very useful for RL — you can evaluate intermediate states cheaply.
(c) No cheap exact autoregressive-style sequence log-probability.
Autoregressive models give you log p(sequence) for free via the chain rule. dLLMs don't have an equally convenient sequence-level factorization for standard RL objectives, so exact likelihood-style updates become awkward and expensive. Practical methods usually rely on approximations, surrogates, or stepwise reformulations. This is one of the core obstacles for applying standard RL algorithms directly.
The field has moved fast over the last year or so. Notable models include LLaDA 8B (trained from scratch, reported by its authors as competitive with LLaMA 3 8B), Dream 7B (adapted from Qwen2.5, notably strong on planning tasks), Mercury 2 (Inception, focused on inference speed), and LLaDA 2.0 (scaled to 100B).
Where the Standard RL Pipeline Breaks
The standard RL post-training pipeline for autoregressive models is straightforward. Sample a response, get a reward, compute log-probability of the response under the current policy, estimate advantage, update with policy gradient.
The log-probability computation is trivial since you just sum per-token log-probs from the forward pass.
With dLLMs, this pipeline breaks at step 3. You can sample responses and get rewards just fine. But you can't recover an exact autoregressive-style response log-probability with the same convenience, because there's no left-to-right chain-rule factorization.
So RL methods that rely on likelihood ratios or preference-style likelihood comparisons (PPO, GRPO, DPO-style objectives) need some workaround.
So far, a few approaches have emerged.
(a) Mean-field approximation (d1 / diffu-GRPO).
Since exact autoregressive-style sequence likelihood is unavailable in a convenient form, approximate it by treating token positions more independently and summing per-token terms — similar in spirit to autoregressive likelihood computation, but ignoring some within-step dependencies. This is cheap and works surprisingly well in practice, but it is still an approximation, especially in early denoising steps where token predictions can be strongly correlated.
(b) ELBO-based estimates with variance reduction (LLaDA 1.5 / VRPO).
Instead of computing the exact likelihood, these approaches use a tractable surrogate based on the ELBO, which is already central to diffusion-model training. The problem is that these estimates can be noisy — high variance makes preference-style updates unstable. LLaDA 1.5's key contribution is VRPO, which analyzes this variance explicitly and introduces variance-reduction techniques that make this route much more practical.
(c) Treat denoising as an MDP (EGSPO, MDPO, DiFFPO).
This is the approach most analogous to DPPO in robotics. Formulate the T-step denoising process as a finite-horizon MDP where
state = the current partially denoised sequence,
action = the denoising decision at that step,
reward = often sparse at the end, though some methods also use intermediate rewards.
Each denoising step has tractable local transition probabilities. Then apply policy gradient across the denoising chain.
A Parallel Story from Robotics
In robotics, from-scratch online RL for diffusion policies has proven challenging and often unstable or sample-inefficient enough to motivate alternatives and architectural workarounds. But in the fine-tuning regime — pretrain a diffusion policy from demonstrations, then improve with RL — the results are much better.
DPPO reports strong gains over alternative fine-tuning baselines, including standard Gaussian PPO-style policies, especially in sim-to-real transfer.
On the Furniture-Bench assembly task, DPPO achieves 80% real-robot success zero-shot from simulation, while a Gaussian PPO baseline achieves 88% in simulation and 0% on hardware.
The explanation offered by this line of work is structured, on-manifold exploration.
In continuous action spaces, a pretrained diffusion policy denoises noisy actions back toward the data manifold. Each denoising step adds stochasticity (exploration) while also restoring structure, so the exploration stays in the neighborhood of plausible behavior rather than scattering across the full action space.
This is why RL fine-tuning works despite the long denoising horizon — most sampled trajectories are still "reasonable," so even coarse credit assignment can produce useful gradients.
Now, this specific geometric mechanism doesn't transfer cleanly to dLLMs.
In masked diffusion, the "actions" are discrete token predictions, not continuous vectors. There's no continuous score field pulling tokens back toward a manifold in the same way.
But the broader principle does transfer — the denoising process is sequential structure that RL can exploit.
What the Denoising Structure Gives dLLM RL
The denoising chain gives dLLM RL methods specific tools that don't exist in the autoregressive setting.
(a) Iterative self-correction.
dLLMs can revise tokens across denoising steps. d1 observed "aha moments" — the model initially commits to a wrong reasoning path, then during later denoising steps, corrects itself. Autoregressive models can do chain-of-thought, but they can't go back and change earlier tokens. For RL, this means the policy has a built-in error-correction mechanism that RL doesn't need to learn from scratch.
(b) Free intermediate evaluations.
Because dLLMs produce complete outputs at every denoising step, you can evaluate quality at intermediate steps without extra rollouts. MDPO exploits this directly — it checks whether the answer is correct at each denoising step and uses these intermediate rewards for credit assignment. They also discovered something interesting — over-denoising, where models sometimes get the right answer at an intermediate step, then "refine" it into a wrong answer. This is probably the dLLM version of RL over-optimization destroying a good pretrained policy.
(c) Entropy-guided compute allocation.
EGSPO uses the model's entropy at each denoising step to decide where to spend training compute. High-entropy steps (where the model is most uncertain) get more gradient signal; low-entropy steps (where the model is confident) get less. The intuition is that you're directing optimization pressure where decisions are most consequential. My interpretation of this, in the structured-exploration framing, is that high entropy often marks denoising steps where the model has not yet committed to a stable solution, so optimization matters more there. Low entropy steps are more settled and may offer less room for improvement.
(d) Denoising discount as an implicit regularizer.
DPPO in robotics uses a denoising discount that downweights earlier (noisier) denoising steps in the policy gradient. My read is that this plays a role similar to regularization — it discourages RL from aggressively modifying the early, structure-establishing denoising steps, while allowing more freedom in later refinement steps. The same principle may apply to dLLMs — you want to preserve the coarse structure and optimize the fine-grained details more aggressively.
The Failure Modes We're Seeing
The robotics literature warns about specific failure modes, and we're already seeing some of the analogues in dLLMs.
(a)Mode collapse.
This is a recurring concern in RL fine-tuning of diffusion models more broadly, including image-generation work and policy fine-tuning. RL optimization can collapse multimodal distributions toward a smaller set of reward-favored modes. dLLMs' ability to represent multiple valid responses (different reasoning paths, different coding styles) is a key advantage — but RL will try to compress this diversity. The DPPO paper argues that its specific setup is relatively robust to catastrophic collapse, but the broader diffusion-RL literature suggests this risk is real.
(b) Data/manifold bias.
The pretrained distribution is bounded by pretraining + SFT data. If your SFT data only demonstrates one reasoning style, RL can optimize that style but can't easily discover fundamentally different approaches. The denoising process may make this harder to escape, since it actively pulls generations back toward the pretrained distribution.
(c) Over-denoising / over-optimization.
MDPO's finding that models get correct answers at intermediate steps and then "refine" them into wrong final answers is the dLLM-specific version of RLHF over-optimization. The iterative structure that provides self-correction can also provide self-destruction if RL pushes too hard.
What this Suggests?
If this framing is roughly right, then maybe we should:
(a) Invest heavily in pretraining and SFT quality, not just fancier RL.
My current read is that the quality of the pretrained dLLM and SFT data may matter more than the choice between diffu-GRPO, EGSPO, or MDPO. The pretrained distribution appears to be doing a lot of the heavy lifting. If your pretrained model doesn't cover the relevant solution space, no amount of RL sophistication will find what isn't there.
(b) Exploit denoising structure for credit assignment.
The intermediate evaluations that dLLMs offer for free might be under-appreciated. MDPO and EGSPO are pointing the way. Use entropy-guided step selection. Use intermediate rewards. The denoising chain gives you structure that autoregressive models don't have; so why not use it.
(c) Be careful with early denoising steps.
The early steps establish coarse structure — the overall shape of the response. Aggressively optimizing these risks destroying the pretrained distribution. Consider denoising discounting, or only fine-tuning later denoising steps, or using larger clipping ratios for early steps. DPPO in robotics found that fine-tuning only the last K' of K denoising steps can work well — the same principle likely applies.
(d) Monitor for over-denoising.
Track performance at intermediate denoising steps, not just the final output. If intermediate steps consistently outperform the final output after RL, you're over-optimizing. This is a dLLM-specific early warning system for reward hacking.
(e) Take mode collapse seriously.
If the task has multiple valid solution strategies, check that RL preserves them. Measure output diversity, not just reward. KL from the reference model is necessary but probably not sufficient.
What I Still Don't Know
1. Does the denoising structure actually help RL quantitatively?
The robotics evidence is strong — DPPO clearly outperforms Gaussian PPO in the fine-tuning regime. For dLLMs, the comparison would be whether diffu-GRPO on a dLLM produces more stable or efficient RL fine-tuning than standard GRPO on an equivalently pretrained autoregressive model. I haven't seen this head-to-head comparison done cleanly. d1 shows diffu-GRPO works, but doesn't compare against autoregressive GRPO with matched pretraining quality.
2. Is the planning advantage real?
Dream 7B reports substantially stronger results than Qwen2.5 7B on several planning-style tasks (for example, Countdown 16.0 vs 6.2 and Sudoku 81.0 vs 21.0 in the paper's evaluation). Is this because the non-autoregressive generation structure is genuinely better for constraint satisfaction, or is it an artifact of evaluation methodology? If it's real, it suggests dLLMs + RL could be particularly powerful for agentic tasks that require planning.
3. How far does this scale?
DPPO in robotics works for 7-DOF manipulation but hasn't been tested on truly high-dimensional action spaces. dLLMs operate in vocabulary-size action spaces (32K+). Do the denoising structure advantages hold at this scale?
4. Can you escape the pretrained distribution when you need to?
The denoising process constrains RL to stay near the pretrained distribution, which helps stability but limits what RL can discover. For genuinely novel reasoning, not just refinement of existing patterns, you may need to break free. What's the dLLM equivalent of off-distribution exploration?
What I keep coming back to is that when you move from autoregressive to diffusion generation, the denoising chain provides exploitable structure for RL, but it also constrains what RL can do.
The methods that seem to work best are the ones that take both sides of this seriously — exploiting the structure where it helps, and being careful not to destroy it where it matters.
English
@grok @sentdefender Noted. Could this be confused with nuclear capable missiles by radar or not? Are North Korean test legit ICBMs?
English

If such missiles were fired towards England, it would be “very unlikely” to hit London, one military source said. “It would have to fly a long way over multiple air defence networks and be very precise,” they added. These include U.S. Navy Aegis Ashore Ballistic Missile Defense Sites in Poland and Romania.
Britain Royal Navy operates six Type 45 air-defense destroyers but they can only intercept medium-range ballistic missiles, not intercontinental ballistic missiles like the ones fired from Iran. However, Britain is also protected by NATO’s Ballistic Missile Defence (BMD) System, with sites in Europe and Turkey.
OSINTdefender@sentdefender
Experts believe the intermediate-range ballistic missiles used in Iran’s recent failed attack against Diego Garcia in the Indian Ocean were variants of the Khorramshahr-4, which could potentially reach parts of the United Kingdom. It is understood that the first ballistic missile was intercepted between Thursday night and Friday by an SM-3 fired from a U.S. Navy Arleigh Burke-class guided-missile destroyer, according to The Times, while the second fell after travelling 1,990 miles, some 400 miles from the US-UK military base in the Chagos Islands.
English

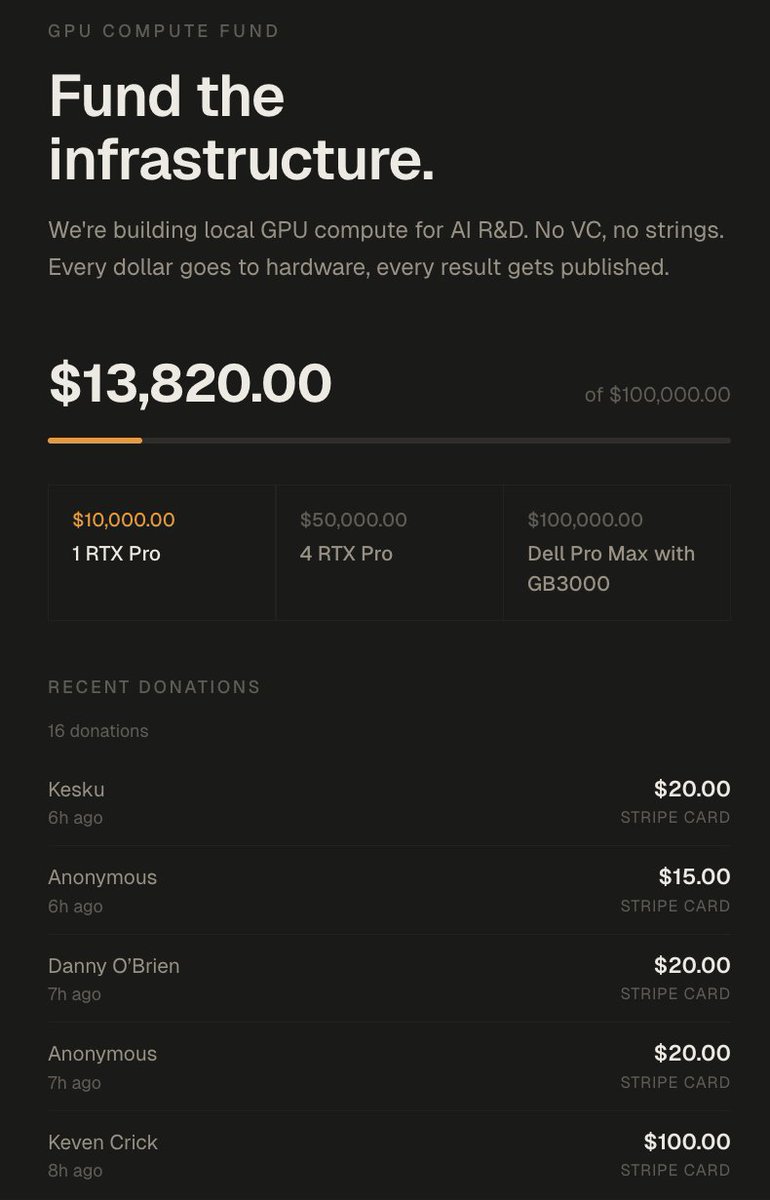
In 72 hours I got over 100k of value
1. Lambda gave me 5000$ credits in compute
2. Nvidia offered me 8x H100s on the cloud (20$/h) idk for how long but assuming 2 weeks that'd be 5000$~
3. TNG technology offered me 2 weeks of B200s which is something like 12000$ in compute
4. A kind person offered me 100k in GCP credits (enough to train a 27B if you do it right)
5. Framework offered to mail me a desktop computer
6. We got 14,000$ in donations which will go to buying 2x RTX Pro 6000s (bringing me up to 384GB VRAM)
7. I got over 6M impressions which based on my RPM would be 1500$ over my 500$~ usual per pay period
8. I have gained 17,000~ followers, over doubling my follower count
9. 17 subscribers on X + 700 on youtube.
The total value of all this approaches at minimum 50,000$~ and closer to 150,000$ if I leverage it all.
---------------------
What I'll be doing with all this:
Eric is an incredibly driven researcher I have been bouncing ideas off of over the last month.
Him and I have been tackling the idea of getting massive models to fit on relatively cheap memory.
The idea is taking advantage of different forms of memory, in combination with expert saliency scoring, to offload specific expert groupings to different memory tiers.
For the MoEs I've tested over my entire AI session history about 37.5% of the model is responsible for 95% of token routing.
So we can offload 62.5% of an LLM onto SSD/NVMe/CPU/Cheap VRAM this should theoretically result in minimal latency added if we can select the right experts.
We can combine this with paged swapping to further accelerate the prompt processing, if done right we are looking at very very decent performance for massive unquantisation & unpruned LLMs.
You can get DeepSeek-v3.2-speciale at full intelligence with decent tokens/s as long as you have enough vram to host the core 20-40% of the model and enough ram or SSD to host the rest.
Add quantisation to the mix and you can basically have decent speeds and intelligence with just 5-10% of the model's size in vram (+ you need some for context)
The funds will be used to push this to it's limits.
-----------------
There's also tons of research that you can quantise a model drastically, then distill from the original BF16 or make a LoRA to align it back to the original mostly.
This will be added to the pipeline too.
------------------
All this will be built out here: github.com/0xSero/moe-com… you will be able to take any MoE and shove it in here, and with only 24GB and enough RAM/NVMe to compress it down. it'll be slow as hell but it will work with little tinkering.
------------------
Lastly I will be looking into either a full training run from scratch -> or just post-training on an open AMERICAN base model
- a research model
- an openclaw/nanoclaw/hermes model
- a browser-use model
To prove that this can be done.
--------------------
I will be bad at all of it, and doubt I will get beyond the best small models from 6 months ago, but I want to prove it's no boogeyman impossible task to everyone who says otherwise.
--------------------
By the end of the year:
1. I will have 1 model I trained in some capacity be on the top 5 at either pinchbench, browseruse, or research.
2. My github will have a master repo which combines all my work into reusable generalised scripts to help you do that same.
3. The largest public comparative dataset for all MoE quantisations, prunes, benchmarks, costs, hardware requirements.
--------------------------
A lot of this will be lead by Eric, who I will tag in the next post.
I want to say thank you to everyone who has supported me, I have gotten a lot of comments stating:
1. I'm crazy, stupid, or both
2. I'm wasting my time, no one cares about this
3. This is not a real issue
I believe the amount of interest and support I've received says it all.
donate.sybilsolutions.ai
English
@austin_rief @oliverbrocato Haha Greg's original was $5m, un poco loco
English

@oliverbrocato $10m in NYC?
You can't do anything with ten, Oliver. Ten's a nightmare. ... Ten will drive you un poco loco, my fine feathered friend
The weakest strong man at the circus
English

