
@paulg Bullet points are great. They naturally provide logical breaks. I don't think optimising for whitespace provides any benefits.
English
Ankit Khandelwal
1.6K posts
@ankk98
AI x Robotics x Data • Founder https://t.co/TSPpuQCR5P • Ex-Founder @jiitodc • Writing at https://t.co/KeCSVzC46r




Introducing **Kriya-Egocentric-100K**: Action100M-style, fully automatic video action annotations for a 5-video preview of Build AI’s Egocentric-100K dataset on Hugging Face. First-person manual-labor videos (head-mounted fisheye camera) with hierarchical temporal segments + LLM-generated captions & GPT summaries. Super promising for video understanding, robotics, world models & physical AI! huggingface.co/datasets/ankk9… #EgocentricVision #ActionRecognition #VideoAI #LLM #HuggingFace #PhysicalAI #Robotics
Introducing **Kriya-Egocentric-100K**: Action100M-style, fully automatic video action annotations for a 5-video preview of Build AI’s Egocentric-100K dataset on Hugging Face. First-person manual-labor videos (head-mounted fisheye camera) with hierarchical temporal segments + LLM-generated captions & GPT summaries. Super promising for video understanding, robotics, world models & physical AI! huggingface.co/datasets/ankk9… #EgocentricVision #ActionRecognition #VideoAI #LLM #HuggingFace #PhysicalAI #Robotics

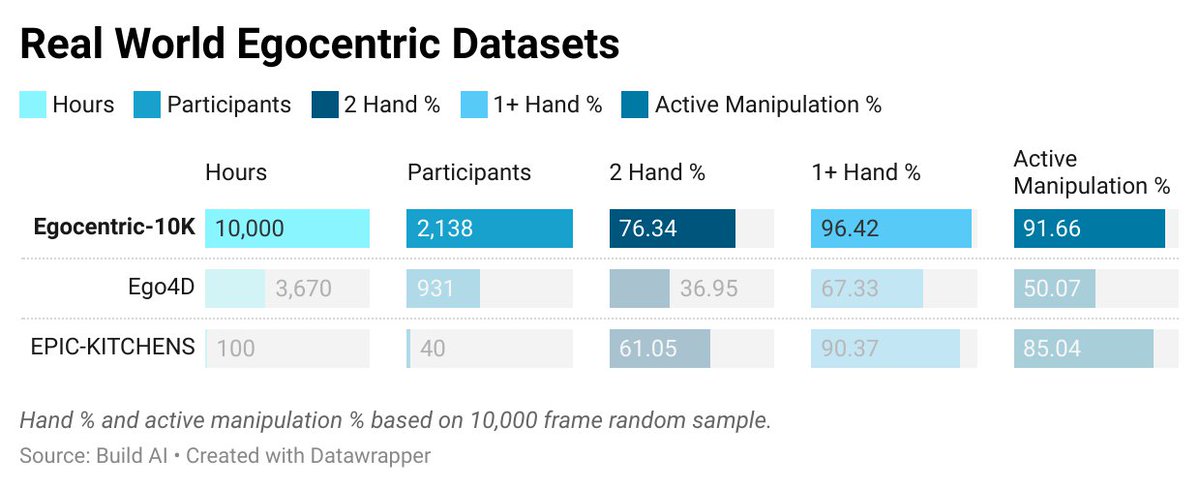
today, we’re open sourcing the largest egocentric dataset in history. - 10,000 hours - 2,153 factory workers - 1,080,000,000 frames the era of data scaling in robotics is here. (thread)
Introducing **Kriya-Egocentric-100K**: Action100M-style, fully automatic video action annotations for a 5-video preview of Build AI’s Egocentric-100K dataset on Hugging Face. First-person manual-labor videos (head-mounted fisheye camera) with hierarchical temporal segments + LLM-generated captions & GPT summaries. Super promising for video understanding, robotics, world models & physical AI! huggingface.co/datasets/ankk9… #EgocentricVision #ActionRecognition #VideoAI #LLM #HuggingFace #PhysicalAI #Robotics





Introducing V-JEPA 2, a new world model with state-of-the-art performance in visual understanding and prediction. V-JEPA 2 can enable zero-shot planning in robots—allowing them to plan and execute tasks in unfamiliar environments. Download V-JEPA 2 and read our research paper ➡️ ai.meta.com/vjepa/






