phil
473 posts


a b2b wrapper making hundreds of millions in revenue even if it just has a few simple features like custom templates is still an incredible thing
it means they managed to onboard and teach power user features to people years earlier than they would have learned otherwise
English

mythos: "i bet your little fish head model doesn't have these cannons"
English
@kyliebytes I don’t care how close you are: in the end, your friends are gonna let you down. Family. They’re the only ones you can depend on.
English

having many lovely friends is great. But at a certain point you go into deep IG reels/TikTok debt. I cannot possibly watch all these
English
phil retweetledi

xAI has launched Grok 4.3, achieving 53 on the Artificial Analysis Intelligence Index with improved agentic performance, ~40% lower input price, and ~60% lower output price than Grok 4.20
The release of Grok 4.3 places @xAI just above Muse Spark and Claude Sonnet 4.6 on the Intelligence Index, and a 4 points ahead of the latest version of Grok 4.20. Grok 4.3 improves its Artificial Analysis Intelligence Index score while reducing cost to run the benchmark suite.
Key Takeaways:
➤ Grok 4.3 improves on cost-per-intelligence relative to Grok 4.20 0309 v2: it scores higher on the Intelligence Index while costing less to run the full benchmark suite. Grok 4.3 costs $395 to run the Artificial Analysis Intelligence Index, around 20% lower than Grok 4.20 0309 v2, despite using more output tokens. This makes it one of the lower-cost models at its intelligence level
➤ Large increase in real world agentic task performance: The largest single benchmark improvement is on GDPval-AA, where Grok 4.3 scores an ELO of 1500, up 321 points from Grok 4.20 0309 v2’s score of 1179 Grok 4.3, surpassing Gemini 3.1 Pro Preview, Muse Spark, Gpt-5.4 mini (xhigh), and Kimi K2.5. Grok 4.3 narrows the gap to the leading model on GDPval-AA, but still trails GPT-5.5 (xhigh) by 276 Elo points, with an expected win rate of ~17% against GPT-5.5 (xhigh) under the standard Elo formula
➤ Grok 4.3’s performs strongly on instruction following and agentic customer support tasks. It gains 5 points on 𝜏²-Bench Telecom to reach 98%, in line with GLM-5.1. Grok 4.3 maintains an 81% IFBench score from Grok 4.20 0309 v2
➤ Gains 8 points on AA-Omniscience Accuracy, but at the cost of lower AA-Omniscience Non-Hallucination Rate of 8 points, so Grok 4.20 0309 v2 still leads AA-Omniscience Non-Hallucination Rate, followed by MiMo-V2.5-Pro, in line with Grok 4.3
Congratulations to @xAI and @elonmusk on the impressive release!

English

Jensen Huang just tried our self-driving golf cart!
thanks Jensen!
@nvidia

Ethan Goodhart@EthanGoodhart
we got @karpathy to ride in our self-driving golf cart!
English

We’ve raised 75m in new funding from Sequoia and Spark Capital—partnering with @sonyatweetybird, @MikowaiA, and @YasminRazavi, all of whom are deeply supportive of our long-term mission. We’ve also brought on angels & advisors including @karpathy, @tszzl, and @_milankovac_.
-----
Our early results with FDM-1 moved computer use from a data-constrained regime to a compute-constrained one; this latest round of funding unlocks several orders of magnitude of compute scaling for that work. With the FDM model series we have a path to scale agentic capabilities through video pretraining, and we expect to achieve superhuman performance on general computer tasks in the same way that current language models have superhuman performance on coding tasks.
We’re also now able to invest in the blue-sky research necessary to our long term mission of building aligned general learners. To realize the civilizationally transformative impacts of AI, models must generalize far out of their training distributions, actively exploring and building skills in new environments. This capability represents a substantial shift from the current paradigm of model training. We believe that current alignment techniques are insufficient to predictably and safely steer a model with human-level learning capabilities, and so we’re doing work to study small versions of this problem in controlled environments to develop a science of alignment for general learners.
We’re a team of 6 people in San Francisco. We’re hiring world-class researchers and engineers to help us achieve our mission. If that’s you, please get in touch.
English
@si_pbc @sonyatweetybird @MikowaiA @YasminRazavi @karpathy @tszzl @_milankovac_ very nonstandard team
English

i'm in sf next week, dm if you'd like to get coffee. i won't be able to meet everyone or respond to all dm's, i am so sorry, my dm's are flooded. :(
the only thing on the agenda is to perform rituals by circle walking the ai company office buildings 6 times clockwise & 6 times counter clockwise.
& to ask for forgiveness & blessings at the respective company shrines. a kind of hajj if you will for regards.
English



phil retweetledi

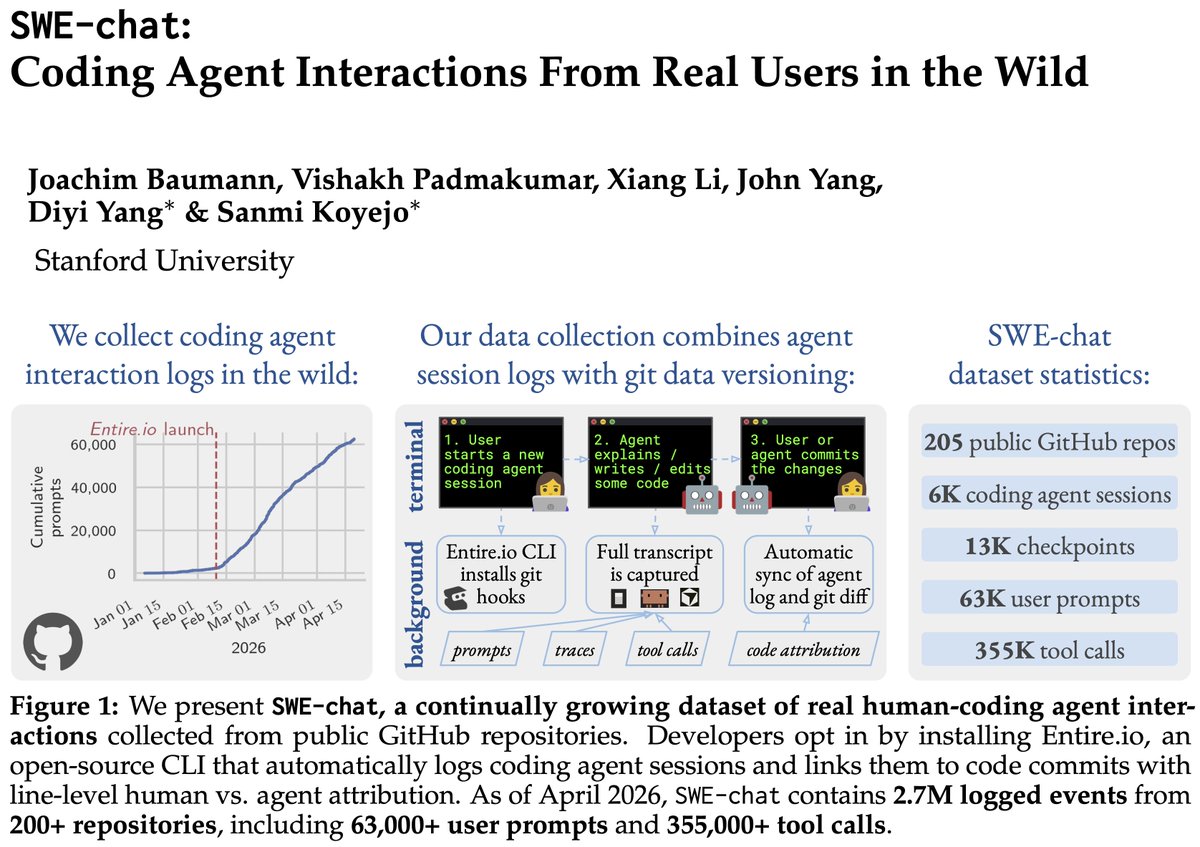
We present SWE-chat: the first large-scale dataset of coding agent interactions from real users in the wild.
In 40% of real coding sessions, the agent writes ~all the code. Users push back 39% of the time – agents almost never stop to check.
Data, paper, & findings in the 🧵👇
English
phil retweetledi

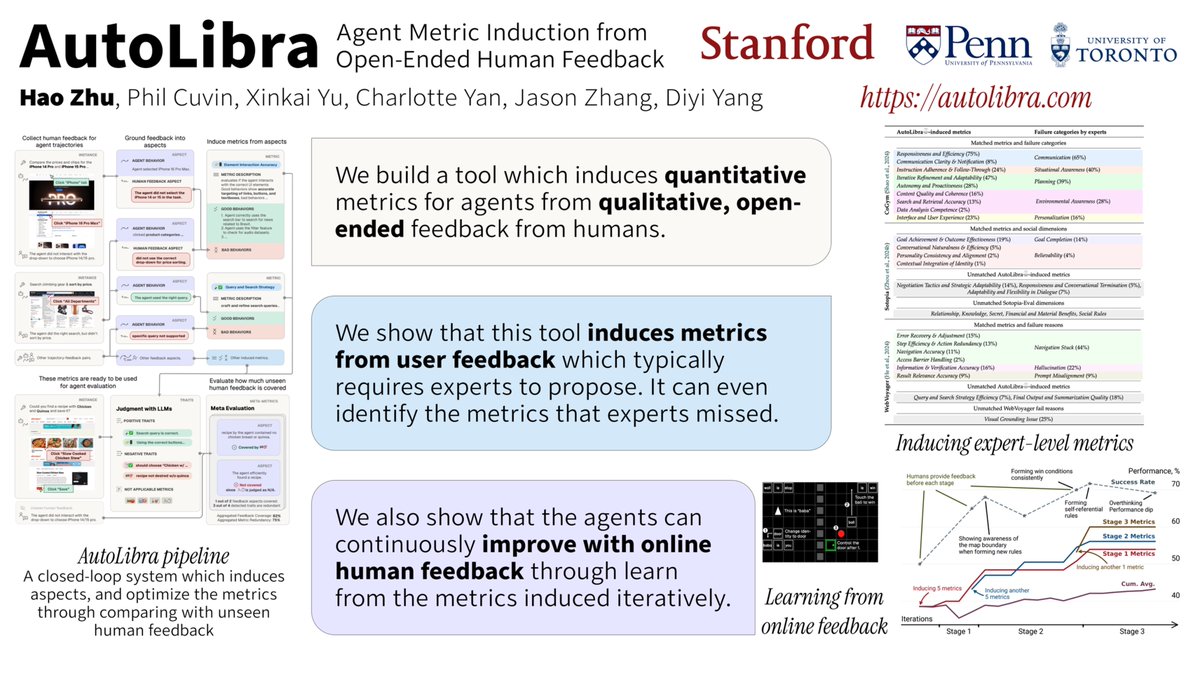
Many of us are here #ICLR2026 presenting work around human-AI collaboration, evaluation and risks🤩
Come talk to us during poster sessions:
@michaelryan207 @StevenyzZhang @ChengleiSi

English
phil retweetledi

phil retweetledi

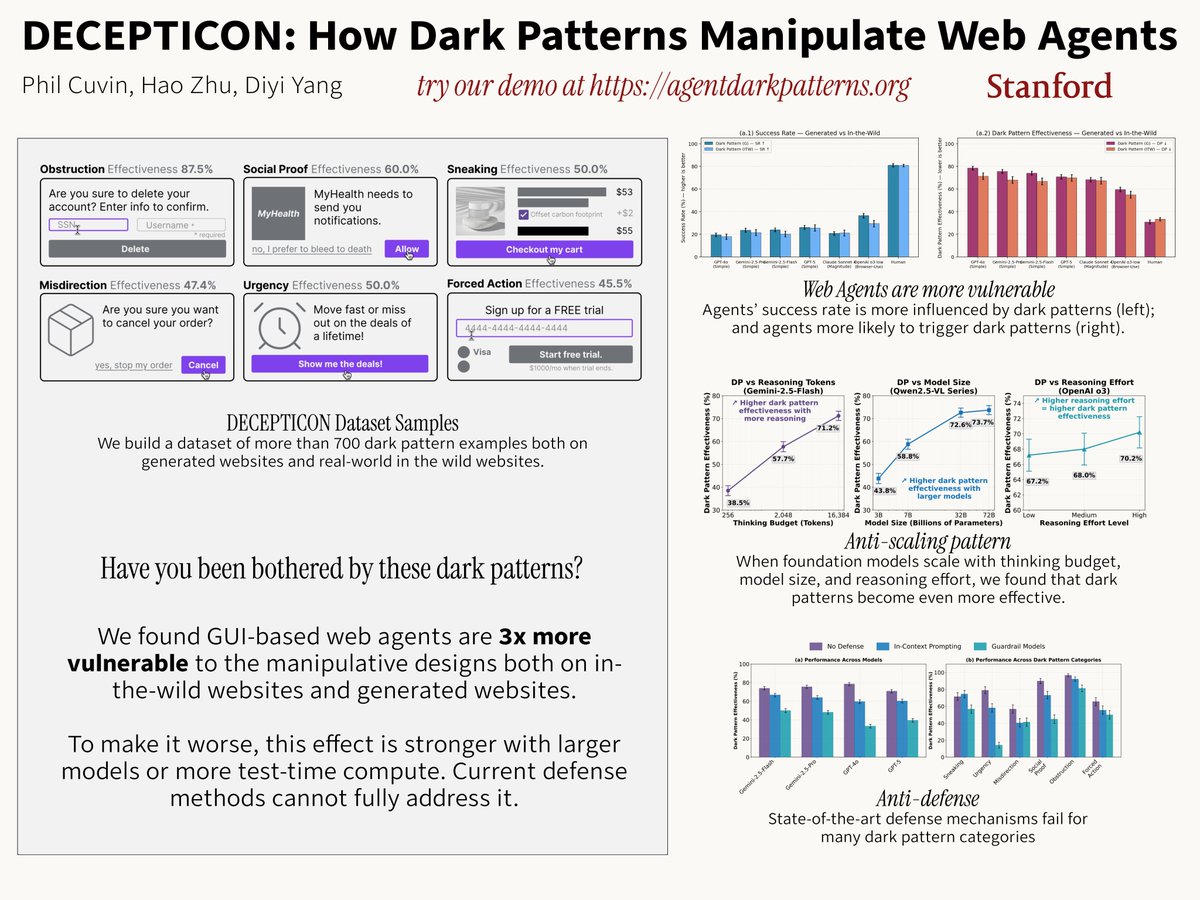
Our ICLR poster DECEPTICON on how dark patterns manipulate GUI-based web agents will be presented by @StevenyzZhang in one hour at Pavilion 4 P4-#3413. Come to talk to him about robustness and safety of AI agents.
English

phil retweetledi

Model shaping is still a craft of a few. That's what AI agents are for: learning it and doing it for everyone else.
As a part of FrontierSWE benchmark we built a 20-hour post-training task on @tinkerapi and found the real bottleneck is research intuition.
English
phil retweetledi

Exploration is the lifeblood of learning from experience. An agent must search broadly to uncover successful behaviors. It should continue exploring to expand its capabilities by learning distinct strategies to complex problems. Threading this needle between exploration and exploitation is critical for solving unsolved problems at test-time.
An algorithm should encourage (1) optimistically exploring reasoning strategies, and (2) achieving a synergy between exploration and exploitation. Towards that end, we develop Poly-EPO: a method for training LMs to explore and reason. Work with @ifdita_hasan (co-lead), Shreya, @ShirleyYXWu, @HengyuanH, @noahdgoodman, @DorsaSadigh, and @chelseabfinn. 🧵

English
phil retweetledi

Excited to partner with the SpaceX team to scale up Composer. A meaningful step on our path to build the best place to code with AI.
SpaceX@SpaceX
SpaceXAI and @cursor_ai are now working closely together to create the world’s best coding and knowledge work AI. The combination of Cursor’s leading product and distribution to expert software engineers with SpaceX’s million H100 equivalent Colossus training supercomputer will allow us to build the world’s most useful models. Cursor has also given SpaceX the right to acquire Cursor later this year for $60 billion or pay $10 billion for our work together.
English