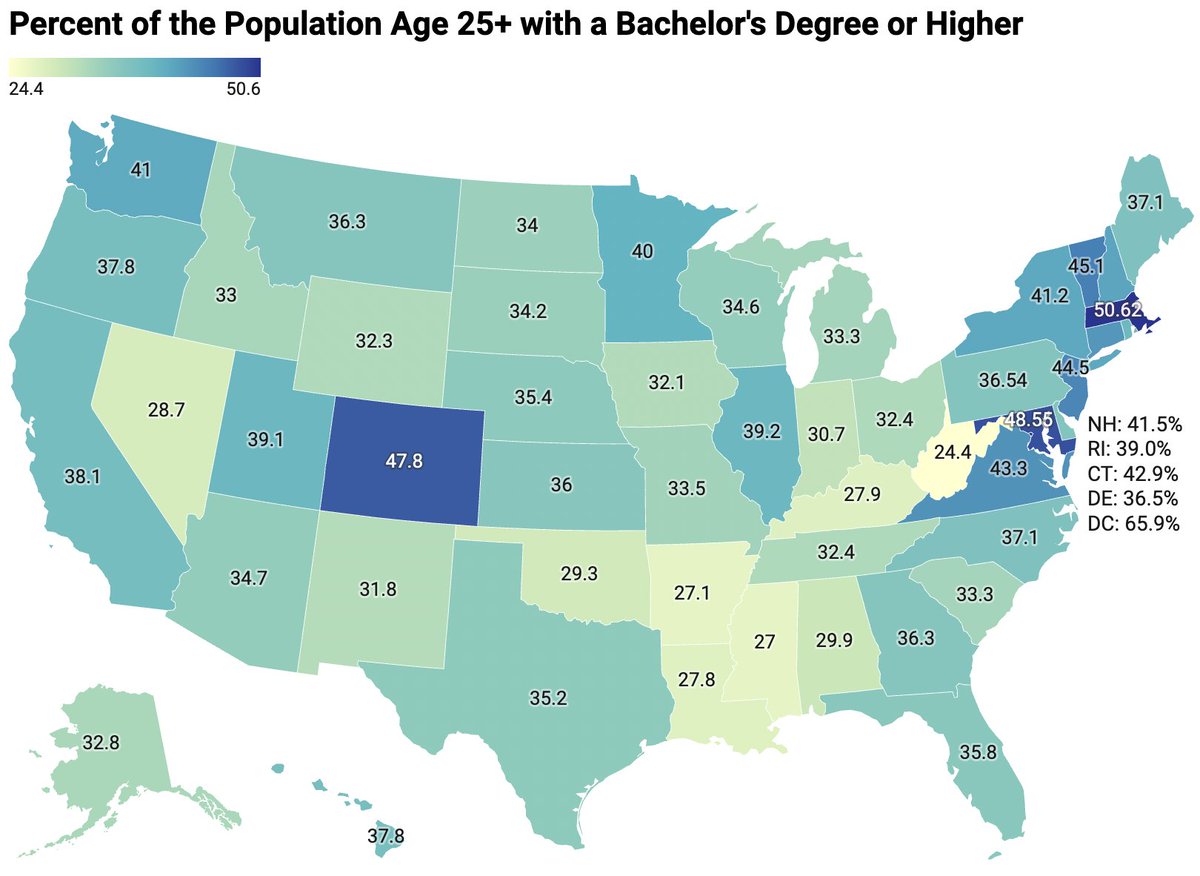
@JDKromkowski @StatisticUrban i think that's pretty important to think about. i think historically degrees were there to differentiate. if there is no longer a differentiation (or a good symbol for it), what's the degree actually worth?
English
cfarm
8.6K posts

@cfarm54
Love building things people use. @tenjinio. HI born and raised


Kids in Lower Merion school district in Pennsylvania get iPads starting in kindergarten, switch to Chromebooks in second grade and get their own MacBooks in eighth grade. Hundreds of parents signed a petition asking to preserve their ability to opt their children out of using digital devices during the school day. The school district has pushed back, saying it’s not feasible to let hundreds of students opt out of technology that is essential to the curriculum.



Not everyone. Just the disserved students at worn-out legacy institutions where professors have already rolled over and given their calling up to credentialism and techno-pandering, which they did almost without a whimper because they admitted long ago that they couldn’t see any reason to continue in the old and noble practice of shaping souls to love what is high and fine through great texts. But it is still entirely possible to carry on that practice because, contrary to fashionable opinion, human beings still feel their hearts leap up when confronted with the excellent achievements of their ancestors and spurred to realization of their own potential. All you have to do is insist to them firmly that yes, you are more than a bot or a brute, yes, we will recite poems we memorize and write essays by hand, yes, you will put away your screens in class and look with your own eyes at paper books containing the words of the old masters, and yes we will enter solemnly into conversation with them. You will love it, I promise. We do it @uaustinorg all the time.











We’re partnering with @Amazon to accelerate AI innovation for enterprises, startups, and end consumers around the world. openai.com/index/amazon-p…



And there it is: Jane Street was behind the 2022 crypto winter, destroying Terraform by first depegging the token and destroying the ecosystem, then pretending it would rescue Terra, while effectively it was soaking up what little value remained.