7 roots orbit in ℂ. Perturb the degree-7 polynomial's coefficients with Gaussian noise: isolated roots stay sharp, clustered ones smear into a cloud. These are the polynomial's ε-pseudozeros: Wilkinson conditioning made visible.
#Pseudospectra#MathArt
@MickRhythm russia is not a state, it’s a gang holding hostages; but, yes, any state is indeed illegitimate, as well as any politician or religious leader is a criminal.
There's a mathematical proof that says no algorithm — no matter how clever, how sophisticated, or how well-designed — can outperform random guessing when averaged across all possible problems. Not A*, not neural networks, not even humans in the loop.
Every advantage on one class of problems is paid for, dollar for dollar, somewhere else. It sounds like it should be false. It isn't.
Please review the article: the theorem is sound. So you can't just dismiss it.
Welcome to the "No Free Lunch Theorem".
This raises an interesting question: how can humans be universal learners if this theorem says universal learns are impossible?
Make your best arguments here. I hint at one possible resolution to this problem.
mindfiretechnology.com/blog/archive/t…
We put the paper online that provides further details (beyond my ICLR keynote) on the role of spontaneous symmetry breaking and Goldstone modes in deep learning. Enjoy! (w/ Nabil Iqbal, Thomas Andy Keller, Takeru Miyato and Yue Song.) arxiv.org/abs/2605.14685
At one point my son and his friend kept looking for shortcuts to getting rich. Over and over I told them the way to do it is just to make something people want. If this is what I tell my own kids about getting rich, why won't politicians believe this is how a lot of people do it?
@McFaul@GUkrainska I wish all those involved in politics and religion dead or retired. Stop pretending you guys can do any good to our biological species. You are decease. May you all be damned.
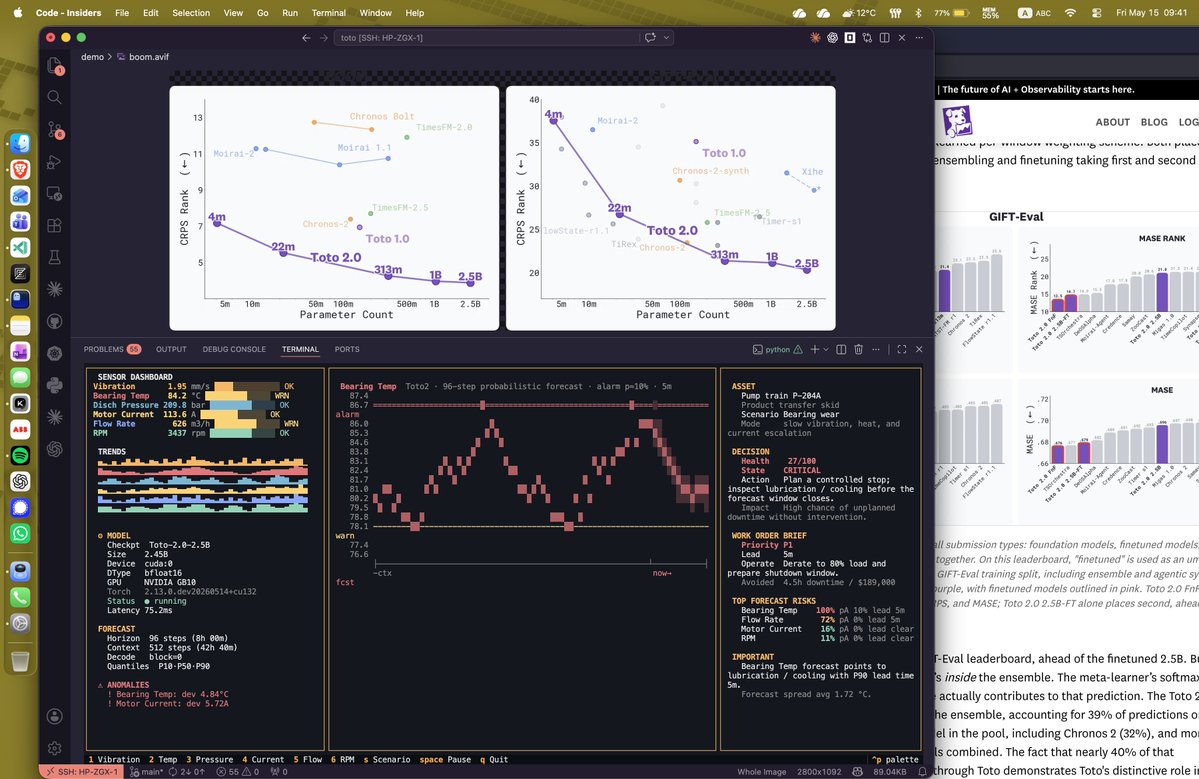
Datadog Toto 2.0: 4M→2.5B open time-series models. Forecasting gets its foundation model era
Not another chatbot in a suit.
Just a model reading production noise: "Your latency is about to ruin your weekend."
Useful AI.
May your CRPS be low!
May your incidents be forecasted!
With NormaCore Station, your robot's full operational life is the dataset.
✅Continuous capture at max hardware speed.
❌ No downsampling.
❌No "start/stop" recording.
It’s all automatically compressed, encrypted, and stored.
When you need a dataset, just pull it. No scripts. No pipelines. Just data. 🎯
Attention @arxiv authors: Our Code of Conduct states that by signing your name as an author of a paper, each author takes full responsibility for all its contents, irrespective of how the contents were generated. 1/
Today we’re releasing Toto 2.0: a family of open-weights time series foundation models spanning 4M to 2.5B parameters.
The question we set out to answer was simple (yet previously open): Do time series foundation models get reliably better as they scale?
Our answer: yes! 🧵
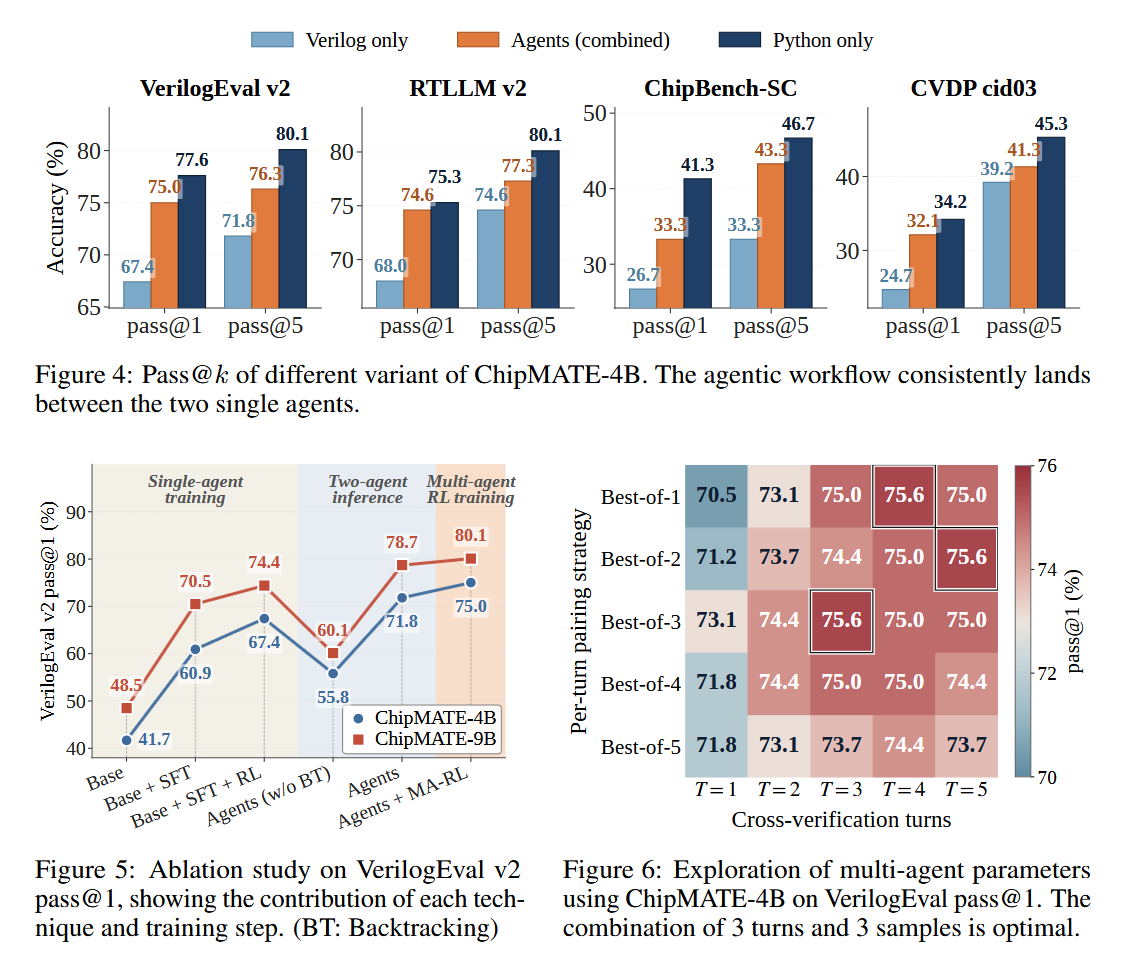
ChipMATE achieves 75.0% and 80.1% pass@1 on VerilogEval V2 with 4B and 9B base models, outperforming all existing self-trained models and even DeepSeek V4 with 1600B parameters.
🚨 BREAKING: NVIDIA proved back-propagation isn't the only way to build an AI.
Billion-parameter models were trained without a single gradient. No calculus, no exploding memory, no massive GPU clusters.
The culprit? A long-dismissed technique called Evolution Strategies.
NVIDIA and Oxford just made it scalable with EGGROLL, which replaces bloated mutation matrices with two tiny ones, enabling hundreds of thousands of parallel mutations at inference-level speed.
They're pretraining models from scratch using only simple integers. No backprop. No decimals.
We assumed the future of AI required endless precision hardware. Evolution had other plans.