
David Pilato 🇺🇦🇪🇺🇫🇷
30.9K posts

David Pilato 🇺🇦🇪🇺🇫🇷
@dadoonet
developer | evangelist @elastic 📧 DM opened. DJ 4 times a year, just for fun! 🎧 https://t.co/Wv6Ne8oML2
France Katılım Haziran 2009
1.9K Takip Edilen5.6K Takipçiler

David Pilato 🇺🇦🇪🇺🇫🇷 retweetledi

HNSW is fast. But it is also memory-hungry.
DiskBBQ is the alternative.
Here's how it works:
1. Hierarchical K-means partitions all vectors into clusters, each with a representative centroid
2. The centroids are arranged into a tree and loaded into memory. The vectors themselves stay on disk
3. At query time, the centroid tree is searched first to find the most promising clusters. Only those get fetched and fully explored.
4. BBQ (Better Binary Quantization) compresses each vector to 1 bit per dimension, so bulk cluster scoring stays fast with minimal memory and disk overhead
5. SOAR (Spilling with Orthogonality-Amplified Residuals) assigns border vectors to multiple clusters, which reduces the recall penalty of hard cluster boundaries
Use HNSW when you need maximum recall and have plenty of memory.
Use DiskBBQ when you're cost-sensitive and can live with slightly lower recall.
English

I was I believe 8 or 9 when I discovered the harmonic functions in BASIC doing a FOR loop and plotting x = sin(k*a) and y = cos(k*b). Transformative experience.
Math Lady Hazel 🇦🇷@mathladyhazel
Lissajous curve table. Best geometry gif ever.
English
David Pilato 🇺🇦🇪🇺🇫🇷 retweetledi

Ca alors, une étude @Arcep qui vient remettre l’église au centre du village en matière d'empreinte environnementale du numérique.
Au total, 575 000 m3 d’eau ont été prélevés par les #DataCenters en 🇫🇷 (soit 0,02% de l'agricole)
#c41418" target="_blank" rel="nofollow noopener">arcep.fr/cartes-et-donn…
Français
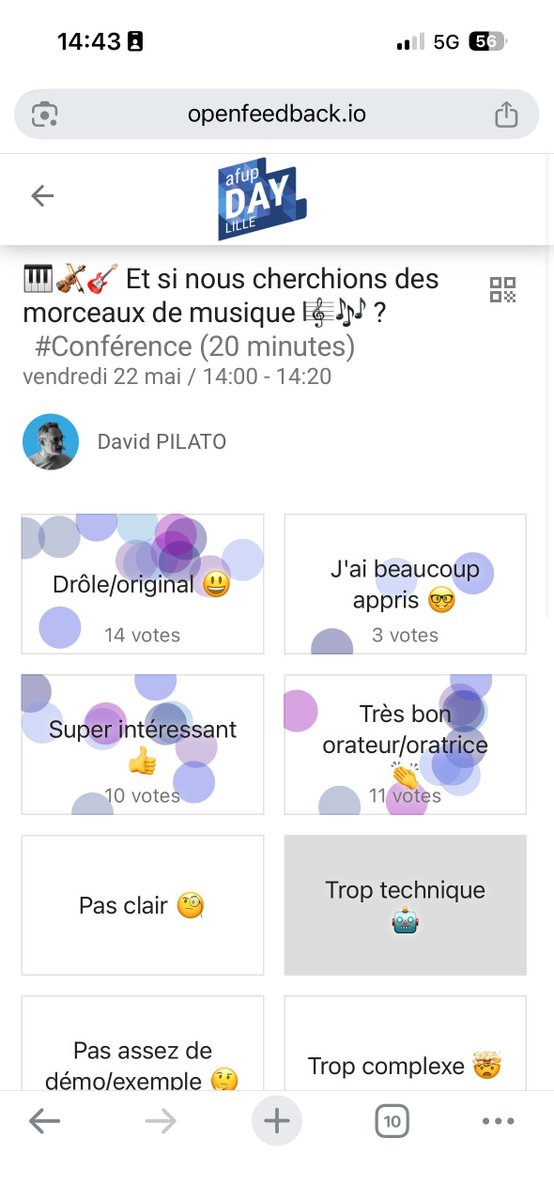
Merci chers participant(e)s de l'@AFUP pour votre participation et vos retours. La présentation est disponible sur : david.pilato.fr/afupdaylille26. #elkie est aussi contente d'avoir retrouvé ses ami(e)s ! 😍



Français

The AI will replace all programmers!
Now every person is able to vibe code!
The prompt:

English
David Pilato 🇺🇦🇪🇺🇫🇷 retweetledi

David Pilato 🇺🇦🇪🇺🇫🇷 retweetledi

Première mondiale ! Un robot a travaillé 200h non-stop, et trié plus de 249 000 colis à lui seul. Pas une seule panne, pas une seule pause et tout a été diffusé en live pour le prouver.
À la base c'était un défi de 8h. Le robot a tellement bien tourné qu'ils ne l'ont jamais coupé. 200 heures plus tard il tournait encore.
Le truc de fou, c'est qu'il y a quelques jours un stagiaire a fait un duel contre le robot sur un shift de 10h. Le gars a gagné. De justesse, 2.79 secondes par colis contre 2.83 pour la machine. Sauf que le stagiaire a fini avec l'avant-bras en vrac. Le robot lui il a continué 190 heures de plus sans broncher.
Et c'est là que je comprends pas. On a littéralement un robot humanoïde qui fait un boulot d'entrepôt en continu, sans supervision, tout est géré par son IA embarquée. Si le robot bug, il se reset tout seul et reprend. Si il a un souci hardware, il sort de la ligne et un autre prend le relais automatiquement.
Malgré tout ça, la majorité des gens ne voient pas ce qui arrive. On scrolle, on passe, on se dit "c'est cool" et on oublie. Mais c'est pas "cool". C'est un changement de civilisation. Les tâches physiques répétitives vont être automatisées.
La robotique humanoïde c'est le sujet dont personne ne parle assez. On commence à peine à parler d'IA avec bien du retard, sauf qu'il faut comprendre que l'étape d'après c'est l'IA incarnée, cad, les robots.
Brett Adcock@adcock_brett
We just wrapped what began as an 8-hour challenge - and it ran for 200 hours without a failure Shoutout to the team for the hardcore engineering behind F.03 and the robust Helix models powering it
Français
David Pilato 🇺🇦🇪🇺🇫🇷 retweetledi
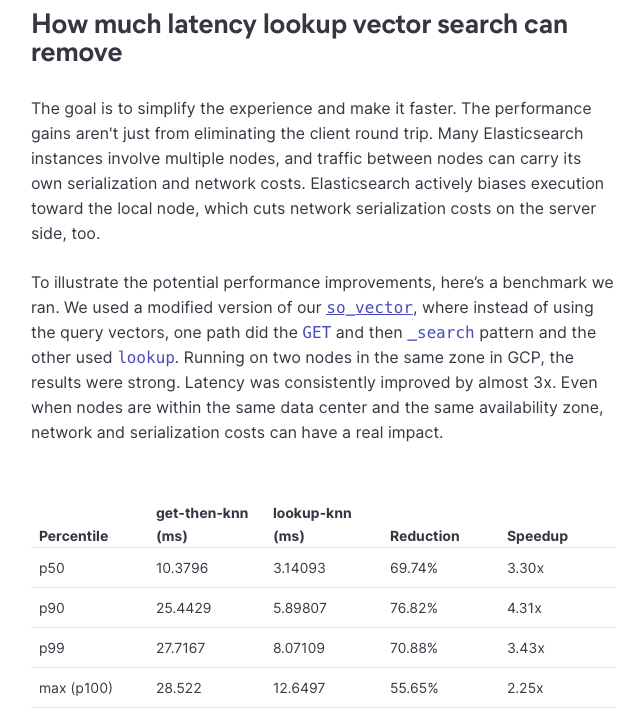
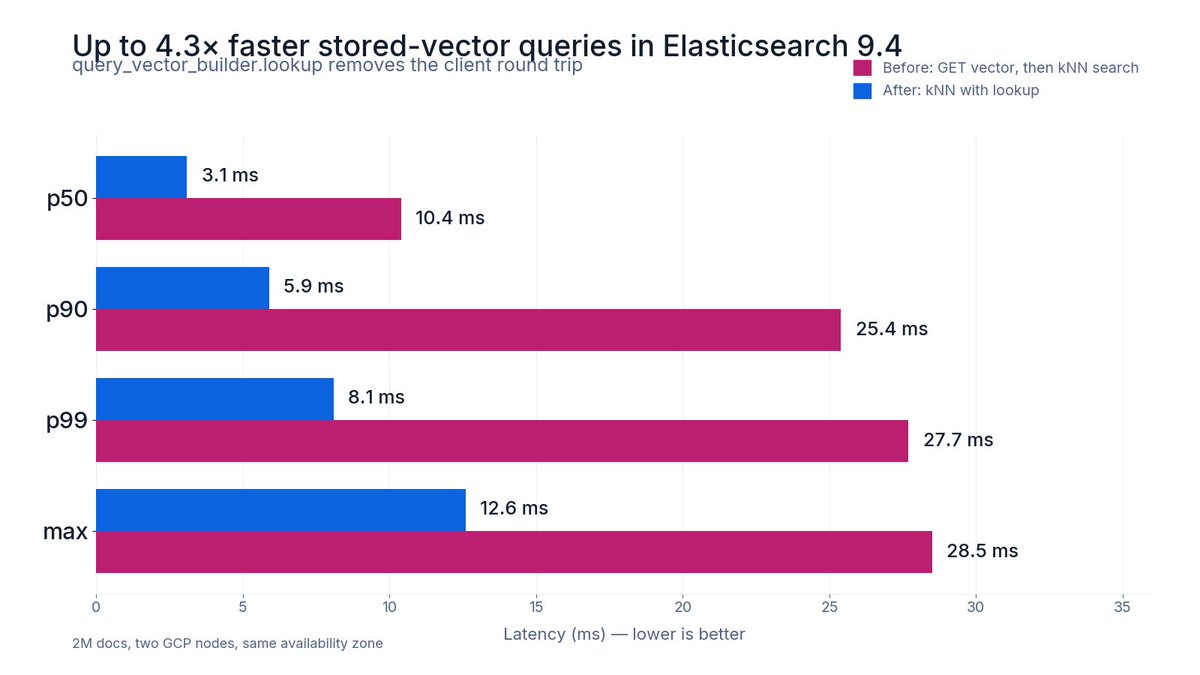
Up to 3.3x faster stored-vector queries in Elasticsearch, and the fix is removing a round trip.
query_vector_builder.lookup in 9.4 lets you reference a vector already in the index. No GET, no serialization back to the client, no second request. The vector stays server-side.
Benchmarked on 2M docs across two GCP nodes: p50 dropped 10.4ms to 3.1ms. At p90, it was 4.3x faster, from 25.4ms to 5.9ms. Even within the same availability zone, network and serialization costs added up.
English
David Pilato 🇺🇦🇪🇺🇫🇷 retweetledi

Je serai demain à l'@AFUP Day 2026 à Lille pour vous parler de recherche de musique. Nous allons utiliser les principes de la recherche vectorielle pour trouver des morceaux de musique 🎶 ressemblant (peut-être) à d'autres.
A demain !
#5471" target="_blank" rel="nofollow noopener">event.afup.org/afup-day-2026/…
Français
David Pilato 🇺🇦🇪🇺🇫🇷 retweetledi

📢 Nous recherchons aux @restosducoeur des ordinateurs portables fonctionnels pour aider nos équipes au quotidien (administratif, accompagnement, communication…).
Si vous avez des laptops qui prennent la poussière dans votre entreprise, donnez lui une seconde vie solidaire💕
Français
English
It feels great to be surrounded by awesomely smart people :-D
I can be blamed this way xD
English
David Pilato 🇺🇦🇪🇺🇫🇷 retweetledi
David Pilato 🇺🇦🇪🇺🇫🇷 retweetledi

When turboquant came out, it got a lot of justified excitement. We took it for a Spin, and our year long work on Elasticsearch BBQ (better binary quantization) holds up better, especially in the abundant world of CPUs.
* also, we need to get Thom an upgrade from M2 ;)
Elastic@elastic
🧵 Our BBQ at 1-bit/doc beats TurboQuant at 4-bit/doc on shifted data on ranking accuracy. At 1/5 the storage. We center on the segment centroid before quantization, so the bits go where they are actually needed for ranking. TurboQuant's Hadamard rotation can't exploit that structure.
English
David Pilato 🇺🇦🇪🇺🇫🇷 retweetledi
Exact kNN on 1M vectors: ~10 QPS
HNSW on the same dataset: ~1000 QPS
This is because HNSW builds a layered graph:
shortcuts at the top, all vectors at the bottom.
A query enters at the top layer, finds the closest node, uses it as the entry point for the layer below, and repeats until it reaches a tight local search at layer 0.
It also let you tune your indexing speed vs query speed vs recall, so you can get the index that suits your needs.
English
David Pilato 🇺🇦🇪🇺🇫🇷 retweetledi

Agent adoption is moving faster than most enterprise telemetry stacks were designed for.
Developers are running agents locally. Security teams need visibility. IT teams need a clean path to operationalize what they see.
That’s why we’re excited to announce @elastic support for @asymptotelabs Beacon.
Beacon can now forward local agent activity into @elastic, giving teams a familiar place to search, investigate, and correlate endpoint agent telemetry alongside the rest of their security data.
This is designed for how modern enterprises already work: keep collection close to the endpoint, route events into the systems teams trust, and make agent activity visible without forcing a new workflow.
For security and IT leaders thinking about how to secure agent activity in the enterprise, visibility is the first step.
We’d love to hear what you need: SIEM requirements, deployment constraints, telemetry use cases, or gaps you’re seeing as agents roll out across your organization.
Github link in the comments below!

English
David Pilato 🇺🇦🇪🇺🇫🇷 retweetledi

Agentic Design Patterns, implemented in #java with @langchain4j.dev and #ADK for #Java
glaforge.dev/talks/2026/05/…
I'm talking about different design patterns, like progressive disclosure, feedback and coding agent loops, goal oriented action planning, LLM-as-Judge!
Lots to cover!
English