AK@_akhaliq
Unity presents IPAdapter-Instruct
Resolving Ambiguity in Image-based Conditioning using Instruct Prompts
discuss: huggingface.co/papers/2408.03…
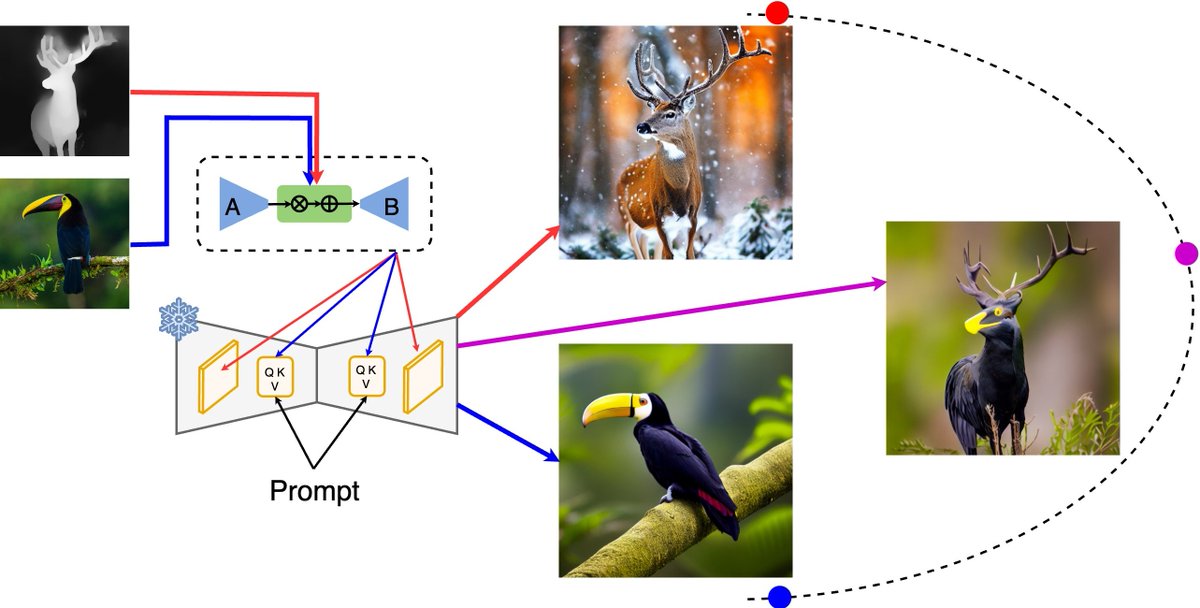
Diffusion models continuously push the boundary of state-of-the-art image generation, but the process is hard to control with any nuance: practice proves that textual prompts are inadequate for accurately describing image style or fine structural details (such as faces). ControlNet and IPAdapter address this shortcoming by conditioning the generative process on imagery instead, but each individual instance is limited to modeling a single conditional posterior: for practical use-cases, where multiple different posteriors are desired within the same workflow, training and using multiple adapters is cumbersome. We propose IPAdapter-Instruct, which combines natural-image conditioning with ``Instruct'' prompts to swap between interpretations for the same conditioning image: style transfer, object extraction, both, or something else still? IPAdapterInstruct efficiently learns multiple tasks with minimal loss in quality compared to dedicated per-task models.