Sabitlenmiş Tweet
Dirk Loss
6.5K posts

Dirk Loss retweetledi

During the last week I executed very long autonomous sessions of Claude Code Opus 4.6 and Codex GPT 5.4 (both at max thinking budget), in cloned directories (refreshed every time one was behind). I burned a lot of (flat rate, my OSS free account + my PRO account) of tokens...
English
Dirk Loss retweetledi

Another example of the changing landscape, following statement from the Linux kernel folks
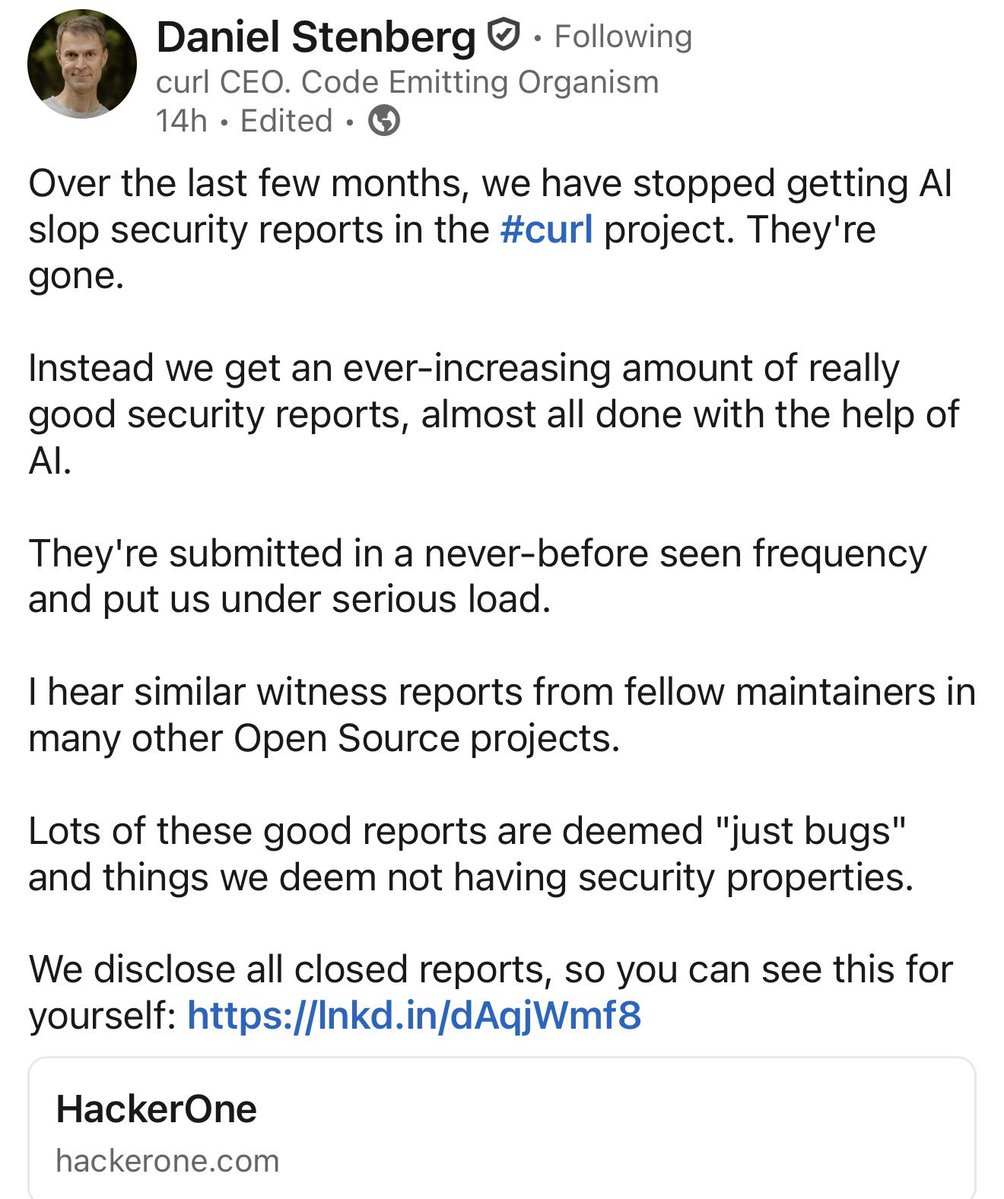
English
Dirk Loss retweetledi

"Using coding agents well is taking every inch of my 25 years of experience as a software engineer, and it is mentally exhausting.
I can fire up four agents in parallel and have them work on four different problems, and by 11am I am wiped out for the day.
There is a limit on human cognition. Even if you're not reviewing everything they're doing, how much you can hold in your head at one time. There's a sort of personal skill that we have to learn, which is finding our new limits. What is a responsible way for us to not burn out, and for us to use the time that we have?" @simonw
Lenny Rachitsky@lennysan
"Using coding agents well is taking every inch of my 25 years of experience as a software engineer." Simon Willison (@simonw) is one of the most prolific independent software engineers and most trusted voices on how AI is changing the craft of building software. He co-created Django, coined the term "prompt injection," and popularized the terms "agentic engineering" and "AI slop." In our in-depth conversation, we discuss: 🔸 Why November 2025 was an inflection point 🔸 The "dark factory" pattern 🔸 Why mid-career engineers (not juniors) are the most at risk right now 🔸 Three agentic engineering patterns he uses daily: red/green TDD, thin templates, hoarding 🔸 Why he writes 95% of his code from his phone while walking the dog 🔸 Why he thinks we're headed for an AI Challenger disaster 🔸 How a pelican riding a bicycle became the unofficial benchmark for AI model quality Listen now 👇 youtu.be/wc8FBhQtdsA
English
Dirk Loss retweetledi

Introducing Gemma 4, our series of open weight (Apache 2.0 licensed) models, which are byte for byte the most capable open models in the world!
Gemma 4 is build to run on your hardware: phones, laptops, and desktops.
Frontier intelligence with a 26B MOE and a 31B Dense model!

English
Dirk Loss retweetledi
At [un]prompted, the illusion that vulnerability research won’t be automated away has passed. Specifically, it was Nicholas Carlini’s talk, a last second entry, that hammered it in.
A short thread + talk video

English
Dirk Loss retweetledi

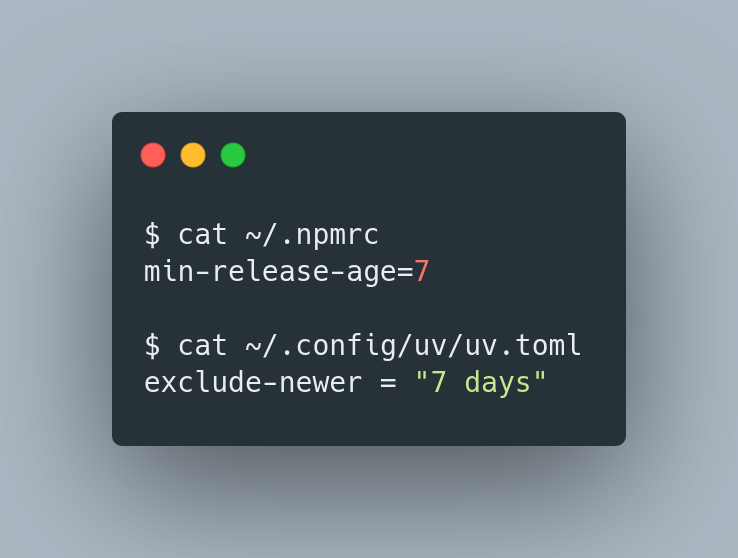
Dirk Loss retweetledi

I think the consensus is that Qwen3.5 is a step change so atm I would recommend explore that, given that it covers a range of sizes suitable for all devices.
Note that the main issues that people currently unknowingly face with local models mostly revolve around the harness and some intricacies around model chat templates and prompt construction. Sometimes there are even pure inference bugs. From typing the task in the client to the actual result, there is a long chain of components that atm are not only fragile - are also developed by different parties. So it's difficult to consolidate the entire stack and you have to keep in mind that what you are currently observing is with very high probability still broken in some subtle way along that chain.
But things are improving on all levels and everything will become better across the board soon.
Best way to evaluate things IMO:
- Start with full quality models that you fit on your hardware
- Make sure you know what your harness actually does. F.ex. don't expect to hook Claude Code or Codex to some local model and the magic to happen. The developers of CC don't care (yet) if it is compatible with Qwen3.5. Best is to write your own harness so you know what happens every step of the way. Or use llama-server's webui (we now have MCP support out of the box)
- When things start to click, look for optimizations to make it faster. Here is where you can start quantizing for speed or looks for some advice in the community for optimal parameters
So I can just say that on the low-level inference side, we will ship the right solution for sure. We still need to make the user-facing stack work better with local models - I'm hoping this will happen, though I feel less capable to control that.
And to answer your question more straightforward, I've experimented with the following models and have found useful applications (mostly around chat, MCP and coding) with all of them:
- gpt-oss-120b
- Qwen3-Coder-30B
- GLM-4.7-Flash
- MiniMax-M2.5
- Qwen3.5-35B-A3B
With the exception of gpt-oss-120b and MiniMax-M2.5, I've used Q8_0 variants to keep most of the original quality.
Unfortunately, I am not familiar with tool calling benchmarks specifically, so I cannot recommend. From my PoV, as long as we make sure the fundamental inference computation is correct, tool calling efficiency will depend just on:
- Model intelligence (something we do not control)
- Chat template parsing (something we are still actively improving on our end in llama.cpp)
English
Dirk Loss retweetledi

Latest open artifacts (#20): New orgs! New types of models! With Nemotron Super, Sarvam, Cohere Transcribe, & others
The top end of the market was quiet, but "industry-scale tinkering" just got very loud. We're seeing a massive shift: specialized, cheap open models are now the crucial tools complementing closed agents.
Analysis & breakdowns of:
- @NVIDIAAI Nemotron-3-Super-120B: 1M context + NVFP4.
- @cohere Transcribe
- @SarvamAI -105B
- @MistralAI -Small-4-119B
Massive coverage of new artifacts from:
- Coding & Logic: @zeddotdev @Meituan_LongCat & Goedel-LM
- Multimodal/OCR: @Microsoft @YuanAI_Lab @BaiduAI & @xiaohongshu (RedNote)
- RAG & Search: @trychroma @LightOnIO & @miromind_ai
- Robotics/Agents: @Reka_AI @hcompany_ai & @ServiceNowRSRCH
- Creative & Audio: @bfl_ml @hume_ai & GAIR
- Data & Infra: @allen_ai @IBM @markov__ai @StepFun_ai
By @natolambert & @xeophon
interconnects.ai/p/latest-open-…
English
Dirk Loss retweetledi
Ladies and gentlemen, the moment you’ve been waiting for: [un]prompted videos are out!
We still need to upload 9 more talks, but we didn’t want to keep people waiting any longer.
Enjoy!
youtube.com/playlist?list=…
English
Dirk Loss retweetledi

I will say that almost all the LLM agentic code I have seen, and that includes my own, does not pass my bar. But my bar is lowering because the expectations on throughput are increasing.
Mario Zechner@badlogicgames
I'm usually not one to write thought pieces without much technical depth. But here we go. Slow the fuck down. mariozechner.at/posts/2026-03-…
English
Dirk Loss retweetledi

Software horror: litellm PyPI supply chain attack.
Simple `pip install litellm` was enough to exfiltrate SSH keys, AWS/GCP/Azure creds, Kubernetes configs, git credentials, env vars (all your API keys), shell history, crypto wallets, SSL private keys, CI/CD secrets, database passwords.
LiteLLM itself has 97 million downloads per month which is already terrible, but much worse, the contagion spreads to any project that depends on litellm. For example, if you did `pip install dspy` (which depended on litellm>=1.64.0), you'd also be pwnd. Same for any other large project that depended on litellm.
Afaict the poisoned version was up for only less than ~1 hour. The attack had a bug which led to its discovery - Callum McMahon was using an MCP plugin inside Cursor that pulled in litellm as a transitive dependency. When litellm 1.82.8 installed, their machine ran out of RAM and crashed. So if the attacker didn't vibe code this attack it could have been undetected for many days or weeks.
Supply chain attacks like this are basically the scariest thing imaginable in modern software. Every time you install any depedency you could be pulling in a poisoned package anywhere deep inside its entire depedency tree. This is especially risky with large projects that might have lots and lots of dependencies. The credentials that do get stolen in each attack can then be used to take over more accounts and compromise more packages.
Classical software engineering would have you believe that dependencies are good (we're building pyramids from bricks), but imo this has to be re-evaluated, and it's why I've been so growingly averse to them, preferring to use LLMs to "yoink" functionality when it's simple enough and possible.
Daniel Hnyk@hnykda
LiteLLM HAS BEEN COMPROMISED, DO NOT UPDATE. We just discovered that LiteLLM pypi release 1.82.8. It has been compromised, it contains litellm_init.pth with base64 encoded instructions to send all the credentials it can find to remote server + self-replicate. link below
English
Dirk Loss retweetledi

I'm usually not one to write thought pieces without much technical depth. But here we go.
Slow the fuck down.
mariozechner.at/posts/2026-03-…
English
Dirk Loss retweetledi
So let's start from this post to tell you about my journey with the LLMs and the new Redis data structure I'm implementing right now. Vector Sets were hand-coded, this time I decided to use Claude/Codex as a helpers, and guess what? The work I had to do was huge. Thread:
Mario Zechner@badlogicgames
I'm usually not one to write thought pieces without much technical depth. But here we go. Slow the fuck down. mariozechner.at/posts/2026-03-…
English
Dirk Loss retweetledi

Now available on Hugging Face: hf-mount 🧑🚀
The team really cooked, still wrapping my head everything possible but you can do things like:
- mount a 5TB dataset as a local folder and query only the parts you need with DuckDB (✅ works)
- browse any model repo with ls/cat like it's a USB drive
- use a shared read-write bucket as a team drive for ML artifacts
- drop the init container that downloads models in your k8s pods
- point llama.cpp at a mounted GGUF and run inference (infinite storage??)

English
Dirk Loss retweetledi

Dirk Loss retweetledi
“If someone 50 years ago planted a row of oaks or a chestnut tree on your plot of land, you have something that no amount of money or effort can replicate. The only way is to wait.” lucumr.pocoo.org/2026/3/20/some…
English
Dirk Loss retweetledi

Most people today are living with chronically tight trapezius muscles. There is no stretch or massage that can fix this. This is because the traps are involved in breathing, gait, and will respond to stress from the external and internal environment. In my new article I dive into the intricacies of this often overlooked muscle and what can be done to improve its function and as a result, your life.

English

Watching this unfolding energy debacle with Iran thinking the same forces that’ve killed our march toward non-petro energy resilience also act to guarantee its inevitability.
Reality eats simple leaders for lunch.
English
Dirk Loss retweetledi

.@nodejs has always been about I/O. Streams, buffers, sockets, files. But there's a gap that has bugged me for years: you can't virtualize the filesystem.
You can't import a module that only exists in memory. You can't bundle assets into a Single Executable without patching half the standard library.
That changes now 👇
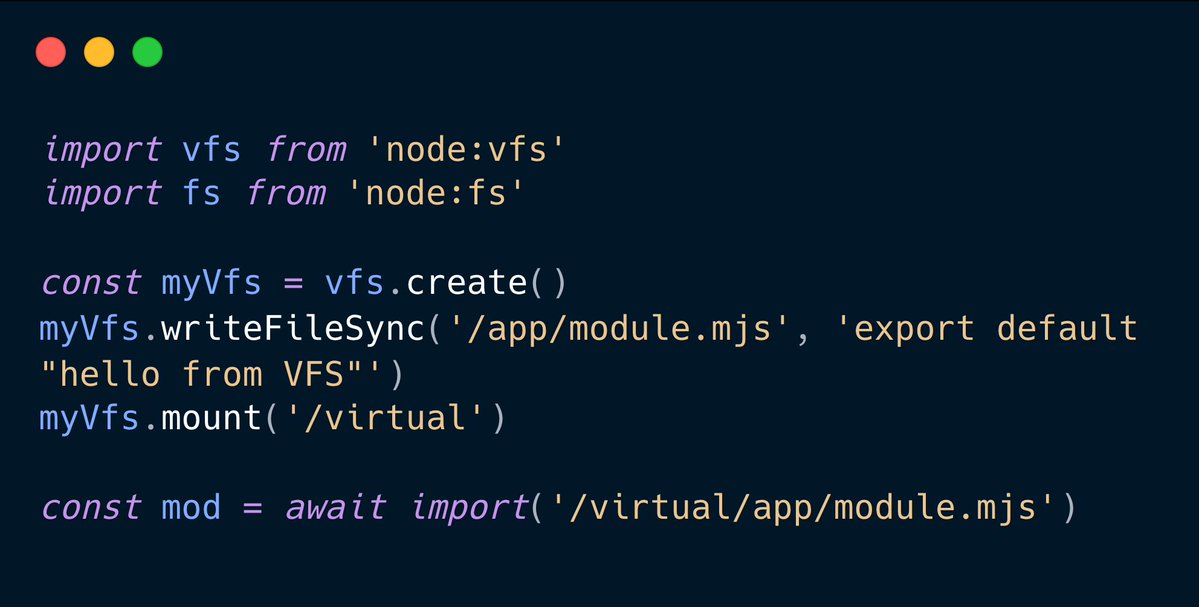
English
Dirk Loss retweetledi

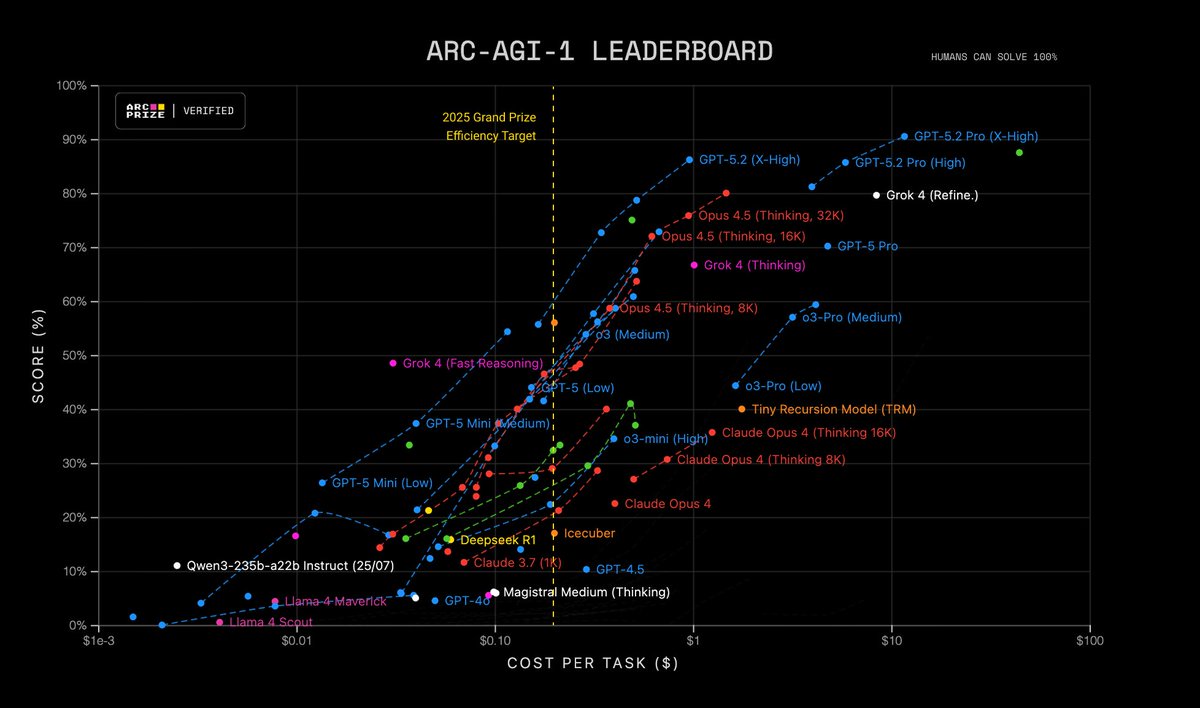
A year ago, we verified a preview of an unreleased version of @OpenAI o3 (High) that scored 88% on ARC-AGI-1 at est. $4.5k/task
Today, we’ve verified a new GPT-5.2 Pro (X-High) SOTA score of 90.5% at $11.64/task
This represents a ~390X efficiency improvement in one year
English