lesetong
131 posts



@zeddotdev @maroffo same on linux.just opened a MD file and it used all my ram
English







If >50% of people press the blue button, everyone survives
Red button pressers always survive, but they’ll get a “red button presser” badge on their Twitter profile.
What do you press?
English

鲸鱼兄弟们好,我是做 DeepSeek-TUI 的那个美国佬。
说真的,特别想跟国内的鲸鱼兄弟们一起混——但我的翻墙技能仅限于写代码,微信到现在都没搞定,属实有点丢人。
求各位大佬帮个忙:
1)帮忙转发扩散一下,让这个开源终端工具翻过高墙被兄弟们看到
2)顺手帮我验证个微信号,我想建个群,大家一起聊 DeepSeek、聊开源、聊怎么把 agent 做得更好
作为交换,我发誓死守 cargo install 这条安装路径,绝不让任何一个兄弟受 npm 的苦。
顺带一提,这段话是 DeepSeek 帮我润色的——感谢鲸鱼赐我流利中文 🙏
github.com/Hmbown/DeepSee…
中文

Ling 2.6-1T just dropped and it is...interesting.
Technically, its better than nothing.
Practically, it's quite delightful to use. It seems to have great reasoning. Good clear written output, and excellent instruction following.
Once again, benchmarks are worthless.

English


New stealth model: Owl Alpha!
Owl is a high-performance foundation model designed for agentic workloads. Powerful tool use capabilities and a 1M context window, ready for use in all your favorite productivity apps.
Try it now and share feedback to improve the model!

English



@AI_Whisper_X 这人完全搞错了一件事:AI可以通过联网搜索知道公开信息,而完全没必要什么都往DNA里刻。而且,人类有意义的信息量哪里有9T这么大?这数据扯出来就不像是专业人士的样子。🤣
中文

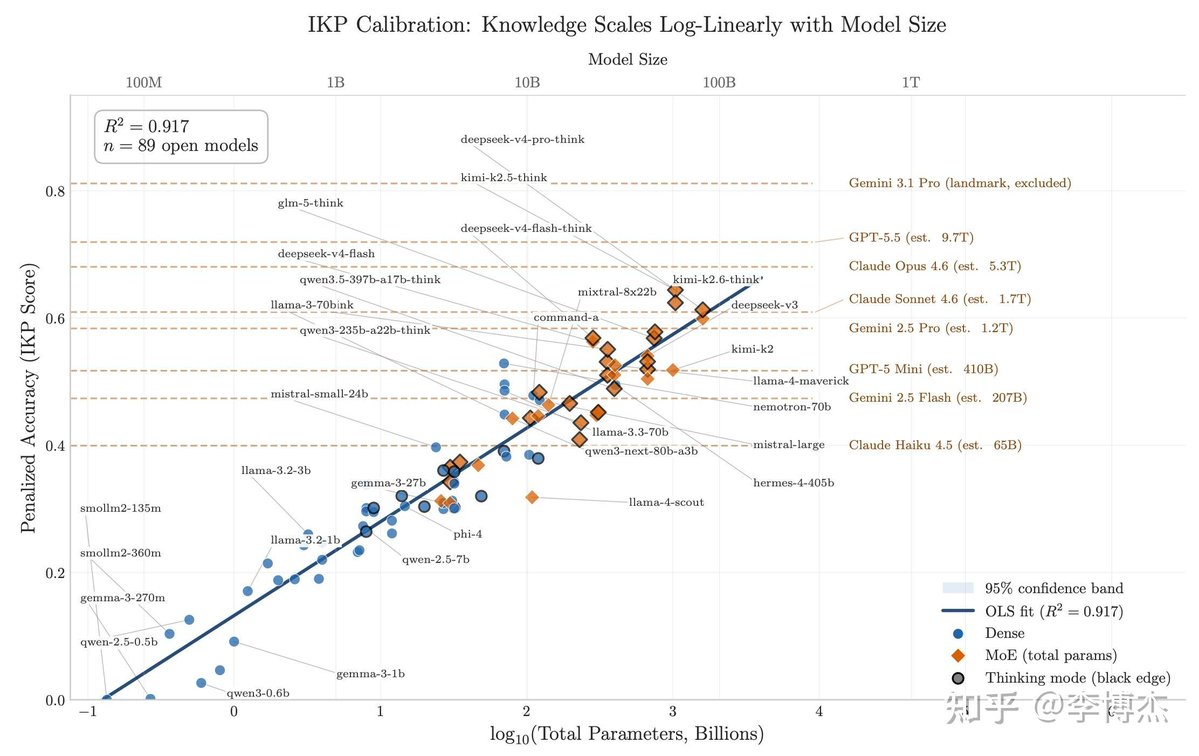
挺有意思的研究。
闭源实验室都对模型规模讳莫如深,但他们其实藏不住模型"知道什么"。而模型知道什么,恰恰就是参数量的指标。
核心逻辑:推理能力可以靠蒸馏压缩到小模型里,事实知识不行。一个模型记得多少冷门事实,直接跟它的参数量挂钩。
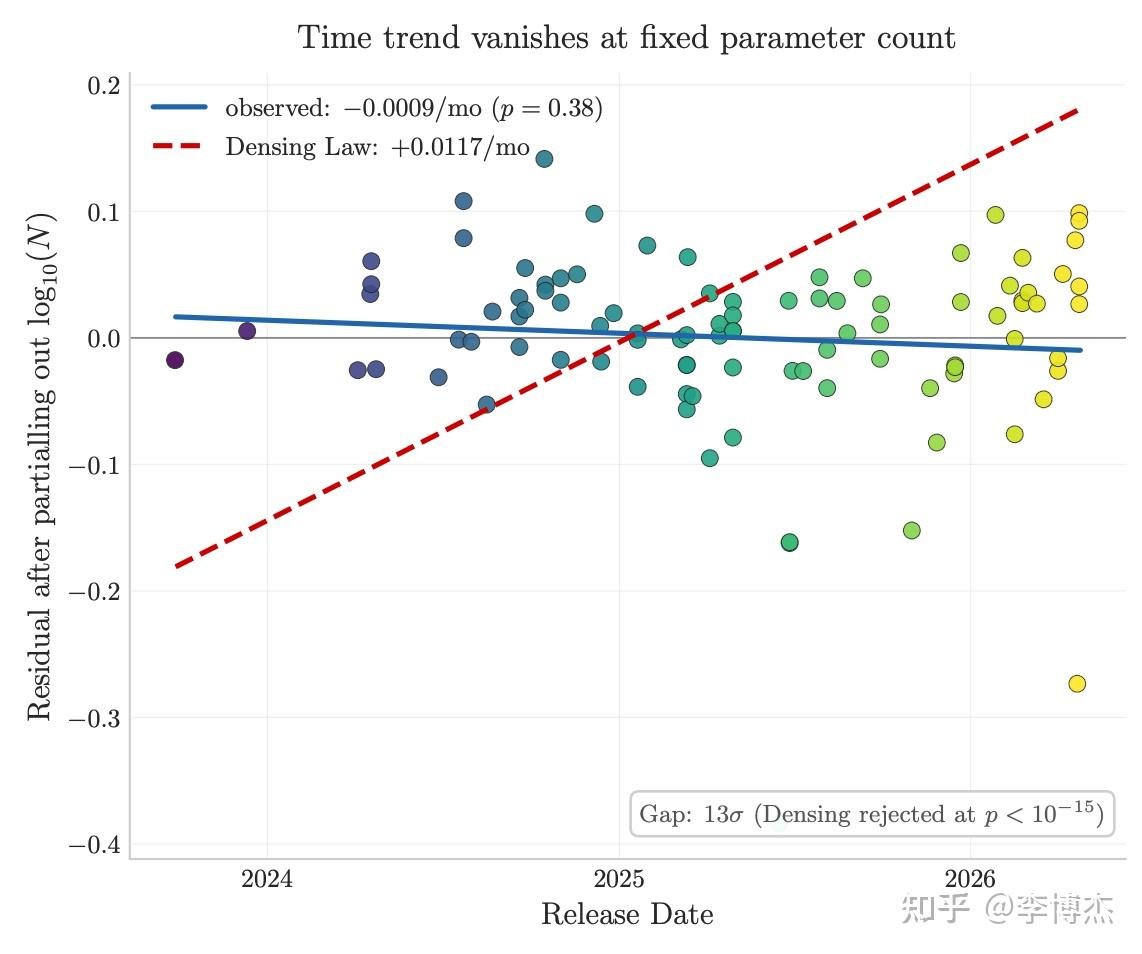
知乎博主李博杰为这个写了一篇小论文,构建了一套叫 IKP(不可压缩知识探针)的数据集:1400 个问题、7 层稀有度,扔到 27 家厂商的 188 个模型上跑了一遍,只看事实准确率。
结果在 89 个公开参数的开源模型上,准确率 vs log(参数量) 的拟合 R²=0.917,基本是一条直线。把闭源模型投影上去,规模就估出来了:
GPT-5.5 ≈ 9T
Claude Opus 4.7 ≈ 4T
GPT-5.4 ≈ 2.2T
Claude Sonnet 4.6 ≈ 1.7T
Gemini 2.5 Pro ≈ 1.2T
(90% 置信区间:0.3-3 倍规模)
另外两个发现也挺反直觉:
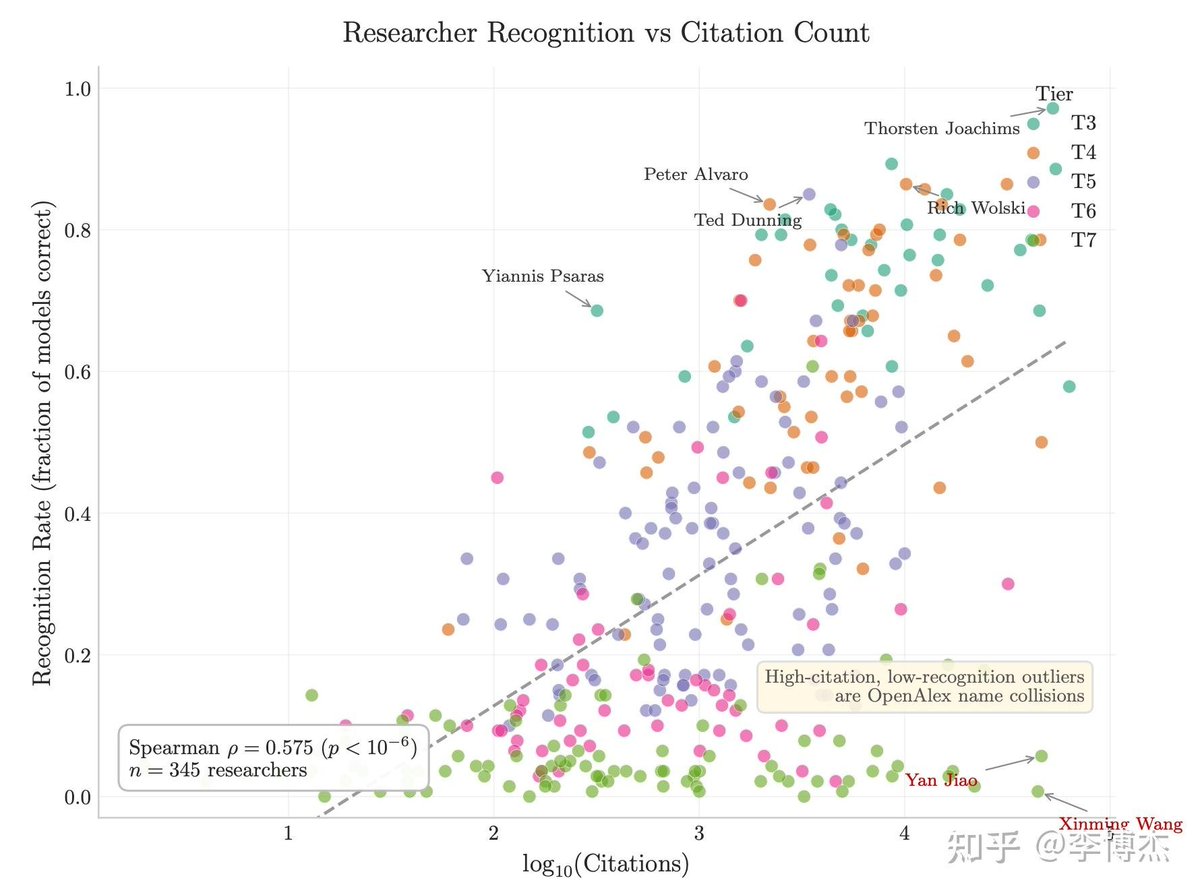
一是引用数和 h-index 不能预测一个研究者是否被前沿模型认识。两个引用数相近的人,模型给的回答可能完全不一样。它记的是有影响力的工作,不是论文数量。
二是事实容量不会被时间压缩。跨 3 年的 96 个开源模型,IKP 时间系数统计上为零(p<10⁻¹⁵),直接拒绝了 Densing Law 预测的 +0.0117/月衰减。benchmark 在饱和,但事实容量还在随参数继续扩张。
来源:知乎博主 李博杰
侵权联系删
arxiv.org/pdf/2604.24827
中文


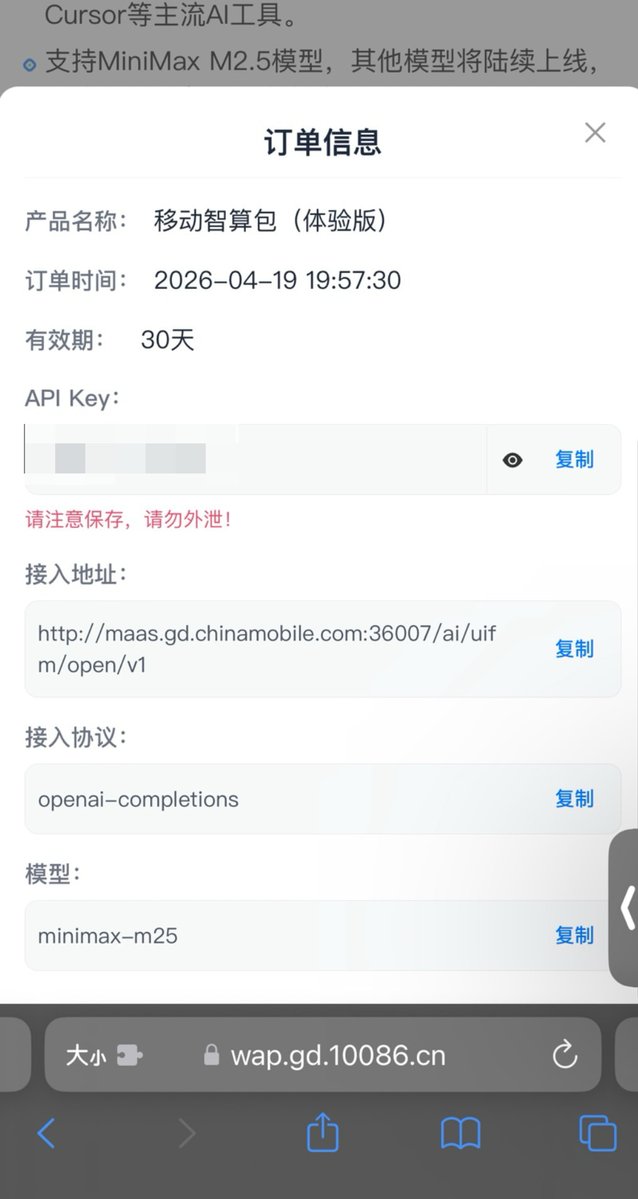
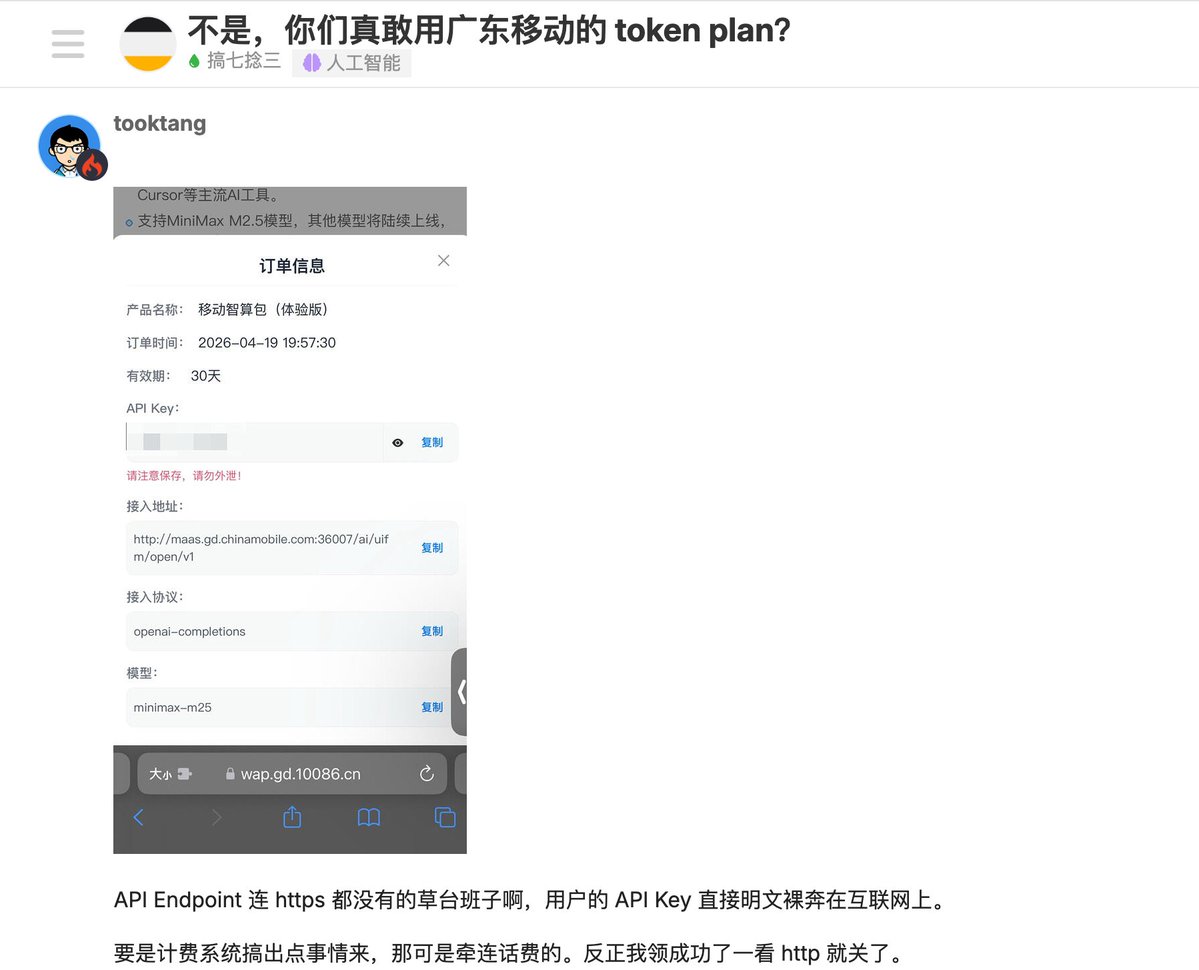




Claude got dumb. I dug really deep to figure out why. I feel like I became a conspiracy theorist while filming this...
English