dario vaquilema retweetledi

You're feeling bored because you're not doing side quests. Life isn't just work and lying
in bed doing nothing.
Here are 50 side quests every man should accomplish:


English
dario vaquilema
959 posts













🚨 Mientras hospitales reportan carencias y falta de medicamentos, la vicepresidenta y ministra encargada de @Salud_Ec, @mjpintoec, aparece en TikTok con una canción de Pamela Cortés. 😡 La crisis sanitaria sigue, pero las prioridades parecen ir por otro lado. 🏥📉














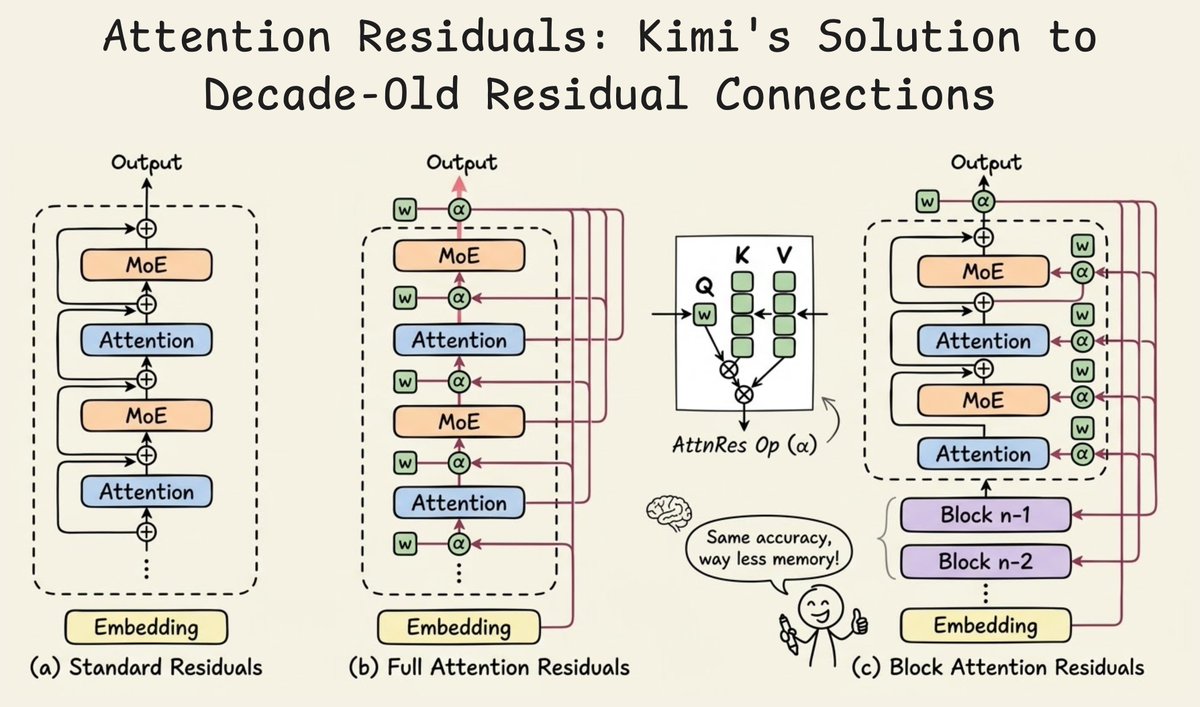
Introducing 𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔: Rethinking depth-wise aggregation. Residual connections have long relied on fixed, uniform accumulation. Inspired by the duality of time and depth, we introduce Attention Residuals, replacing standard depth-wise recurrence with learned, input-dependent attention over preceding layers. 🔹 Enables networks to selectively retrieve past representations, naturally mitigating dilution and hidden-state growth. 🔹 Introduces Block AttnRes, partitioning layers into compressed blocks to make cross-layer attention practical at scale. 🔹 Serves as an efficient drop-in replacement, demonstrating a 1.25x compute advantage with negligible (<2%) inference latency overhead. 🔹 Validated on the Kimi Linear architecture (48B total, 3B activated parameters), delivering consistent downstream performance gains. 🔗Full report: github.com/MoonshotAI/Att…