Sabitlenmiş Tweet
Laurian Gridinoc
67.9K posts

Laurian Gridinoc
@gridinoc
Full Stack Computational Linguist ※ Mozilla OpenNews Fellow ※ Virtual Production ※ Filmmaker ※ AI accelerationist
1 AU Katılım Nisan 2007
5.1K Takip Edilen3K Takipçiler


Laurian Gridinoc retweetledi

The old bad SWE productivity metric: lines of code written.
The new bad SWE productivity metric: tokens consumed.
English
Laurian Gridinoc retweetledi


Laurian Gridinoc retweetledi

For those interested in getting into local AI this is my most important video.
youtu.be/Adliwsf2oPE

YouTube
English
Laurian Gridinoc retweetledi

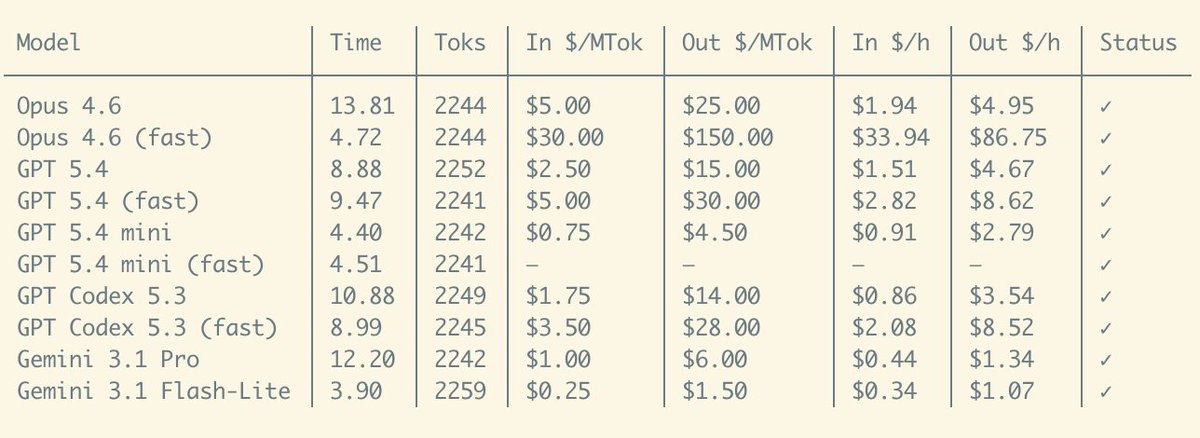
Sorry for posting this again, I'm still processing it:
It'd cost >>> $743k per year <<< to run Opus-4.6 fast-mode nonstop
Literally my company cannot afford a single person using it for daily coding. And that's a shame because the experience is truly magical. I've spent the last 2 days using it on Pi (nearly $500 gone 💀), and it was the first time I kinda got into the flow state while using an agent, because the feedback is just so fast. This is not something I ever experienced before, definitely not with GPT 5.4's own fast mode.
I can't wait for this kind of super fast, super high intelligence to be available for a reasonable cost...
English
Laurian Gridinoc retweetledi

@pmarca Werner Herzog, the OG hater of psychoanalysts, said it best: when you illuminate every last corner of a house, the house becomes uninhabitable youtu.be/G_7Ta_4coy4

YouTube
English
Laurian Gridinoc retweetledi

people are discovering the "rewrite everything in fast language with codex" life hack
Rach@rachpradhan
We replaced urllib3 inside boto3 with a Zig HTTP client. One import line. Same API. Upto 115x faster with TurboAPI. import faster_boto3 as boto3 Here's what happened..
English
Laurian Gridinoc retweetledi

Laurian Gridinoc retweetledi

Qwen3.5-4B searched 20+ websites, cited its sources, and found the best answer! 🔥
Try this locally with just 4GB RAM via Unsloth Studio.
The 4B model did this by executing tool calls + web search directly during its thinking trace.
English

Lotta people been asking for something like this
Alex Doda 🇦🇶@alexdoda
Meet Ankh.md for Hermes Agent Ankh.md helps you craft & use multiple Hermes Agents locally on your computer scoped to folders, projects, or specialized use cases. Each AI Agent gets its own skills, tools, prompt, and other Hermes Agent features using your local file system and a simple pass-through .yaml config file. Visit Ankh.md for the video tutorial, cinematic trailer in 2K quality, features, and to try it out. Link in the reply. 100% Free, MIT License, Open Source @NousResearch Hackathon Entry
English
Laurian Gridinoc retweetledi

Introducing LiteParse - the best model-free document parsing tool for AI agents 💫
✅ It’s completely open-source and free.
✅ No GPU required, will process ~500 pages in 2 seconds on commodity hardware
✅ More accurate than PyPDF, PyMuPDF, Markdown. Also way more readable - see below for how we parse tables!!
✅ Supports 50+ file formats, from PDFs to Office docs to images
✅ Is designed to plug and play with Claude Code, OpenClaw, and any other AI agent with a one-line skills install. Supports native screenshotting capabilities.
We spent years building up LlamaParse by orchestrating state-of-the-art VLMs over the most complex documents. Along the way we realized that you could get quite far on most docs through fast and cheap text parsing.
Take a look at the video below. For really complex tables within PDFs, we output them in a spatial grid that’s both AI and human-interpretable. Any other free/light parser light PyPDF will destroy the representation of this table and output a sequential list.
This is not a replacement for a VLM-based OCR tool (it requires 0 GPUs and doesn’t use models), but it is shocking how good it is to parse most documents.
Huge shoutout to @LoganMarkewich and @itsclelia for all the work here.
Come check it out: llamaindex.ai/blog/liteparse…
Repo: github.com/run-llama/lite…
LlamaIndex 🦙@llama_index
We've spent years building LlamaParse into the most accurate document parser for production AI. Along the way, we learned a lot about what fast, lightweight parsing actually looks like under the hood. Today, we're open-sourcing a light-weight core of that tech as LiteParse 🦙 It's a CLI + TS-native library for layout-aware text parsing from PDFs, Office docs, and images. Local, zero Python dependencies, and built specifically for agents and LLM pipelines. Think of it as our way of giving the community a solid starting point for document parsing: npm i -g @llamaindex/liteparse lit parse anything.pdf - preserves spatial layout (columns, tables, alignment) - built-in local OCR, or bring your own server - screenshots for multimodal LLMs - handles PDFs, office docs, images Blog: llamaindex.ai/blog/liteparse… Repo: github.com/run-llama/lite…
English
Laurian Gridinoc retweetledi

There's an old joke in systems biology called "How Biologists Fix a Radio."
A biologist, tasked with figuring out why a radio doesn't work, removes components one by one and catalogs the result.
Remove this transistor: the radio makes a horrible screeching sound.
Conclusion: this is the "horrible screeching transistor."
Remove another component: the radio goes silent.
Conclusion: this is the "silence transistor."
This is essentially what we do with genomics.
We see which genes are mutated in cancer and assume they must be "cancer genes."
We see which genes are differentially expressed and assume they must be "important."
But correlation is not causation, and a parts list is not a circuit diagram.
You can have a complete inventory of every resistor, capacitor, and transistor in a radio and still have no idea how it plays music.

English
Laurian Gridinoc retweetledi

The highest leverage thing you can do to de-slopify AI writing is to delete at least half of it
Seriously any email, post etc try to delete 50%
English
Laurian Gridinoc retweetledi

Laurian Gridinoc retweetledi

🧠 Key innovation: Layout-as-Thought
End-to-end OCR models lose explicit layout analysis, something pipeline systems handle natively.
Qianfan-OCR solves this with an optional thinking phase via tokens: the model generates bounding boxes, element types, and reading order before producing its final output.
The result is pipeline-level layout analysis from an end-to-end model.

English
Laurian Gridinoc retweetledi

Laurian Gridinoc retweetledi

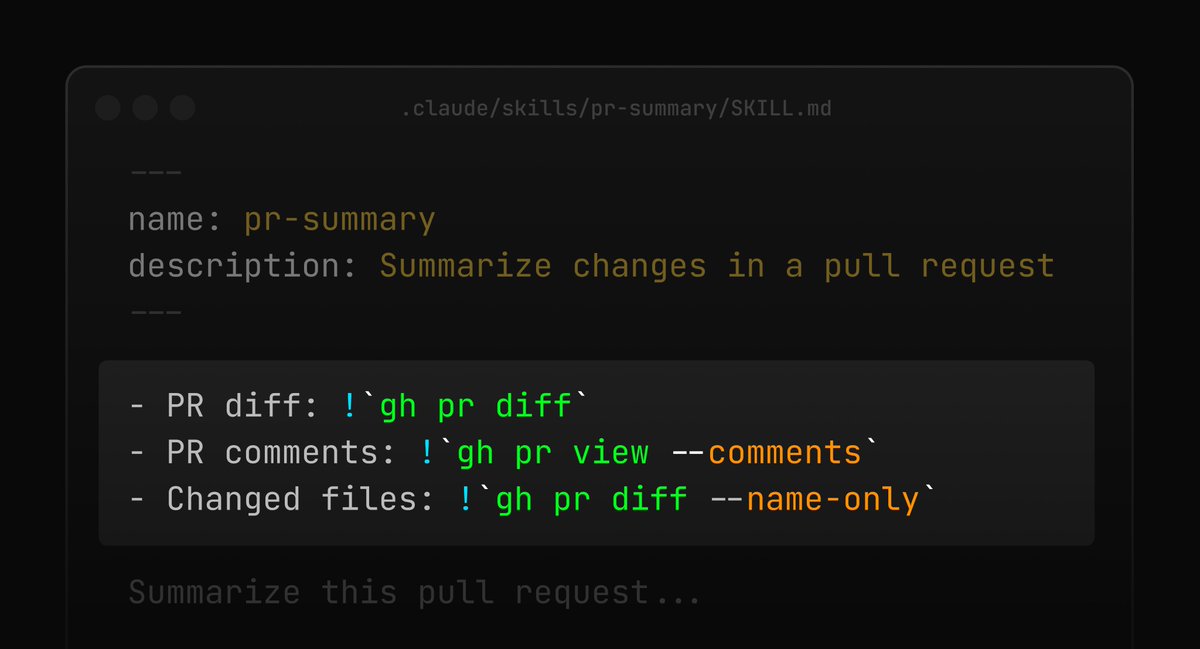
if your skill depends on dynamic content, you can embed !`command` in your SKILL.md to inject shell output directly into the prompt
Claude Code runs it when the skill is invoked and swaps the placeholder inline, the model only sees the result!
English
Laurian Gridinoc retweetledi

The recurring themes: better small model support, Docker-ready setup, persistent memory that survives restarts, and a team (@Teknium) that merges community bug fixes the same day.
@sudoingX @Zeneca @LottoLabs @rodmarkun @WeXBT have all been building and benchmarking publicly.
If you run local models or want to self-host your own agent stack — read the full breakdown to see if the switch is for you 👇theopensourcepress.com/hermes-agent-v…
English
Laurian Gridinoc retweetledi

Laurian Gridinoc retweetledi
