Sabitlenmiş Tweet
Jeff S
5.2K posts


Jeff S
@gsogol
Building Generative AI Apps / Agentic Workflows
Boca Raton, FL Katılım Mart 2009
273 Takip Edilen698 Takipçiler
@GitMaxd @FireworksAI_HQ @LangChain How are you not getting rate limited unless this is not production/realistic work loads
English

Switched out Sonnet 4.6 for GLM 5.1 through @FireworksAI_HQ while doing some tests with @LangChain Fleet Agents
Went from $0.19 per run with Sonnet to $0.07 with GLM 5.1
You can also drop Kimi K2.6 and get the same response for $.05
Opus 4.7 cost $.045 - for the same result 👀
English
@DeepInfra Wish you weren't so rate limited without requiring dedicated endpoints
English

Price drop alert on DeepInfra:
• GLM-5.1 → $1.05 / $3.50 / $0.205
• GLM-5 → $0.60 / $2.08 / $0.12
• MiniMax-M2.5 → $0.15 / $1.15 / $0.03
• Gemma-4-26B-A4B-it → $0.07 / $0.34
(in / out / cached, per 1M)
deepinfra.com/models
English
@pierreeliottlal Curious, can you DM one's connections in LinkedIn? Do you do it via partner program or 3rd party?
English

Today we just released our self-learning AI GTM Brain powered by Claude.
Every time you launch an outbound campaign, you usually start from scratch. That’s over now.
Our GTM Brain learns from every campaign and compounds what works over time:
Auto-creates lead lists based on real buying intent
Auto-optimizes your campaigns in real time
Auto-refines your ICP as more data comes in
No more reset. Just compounding performance.
2–5x more replies and demos compared to traditional outreach.
Welcome to the future.
English




Currently in Public Preview.
Try it now!
⚡️ wandb.me/LoraLaunch
English
NEW: You bring the LoRA, we bring the @CoreWeave GPUs 🤝
Introducing Serverless LoRA Inference on W&B!
Upload, version, and serve custom LoRAs instantly on the only @SemiAnalysis_ platinum grade AI cloud.
This is totally not an AI generated infographic to help you get started.

English
@BenjDicken What kind of queue gets OOM? Are the messages not durable? For certain workloads, messages cannot be lost. Queuing infrastructure should be able to store them until the subscriber catches up. Others have a business TTL. Don't even know what a technical TTL even means.
English

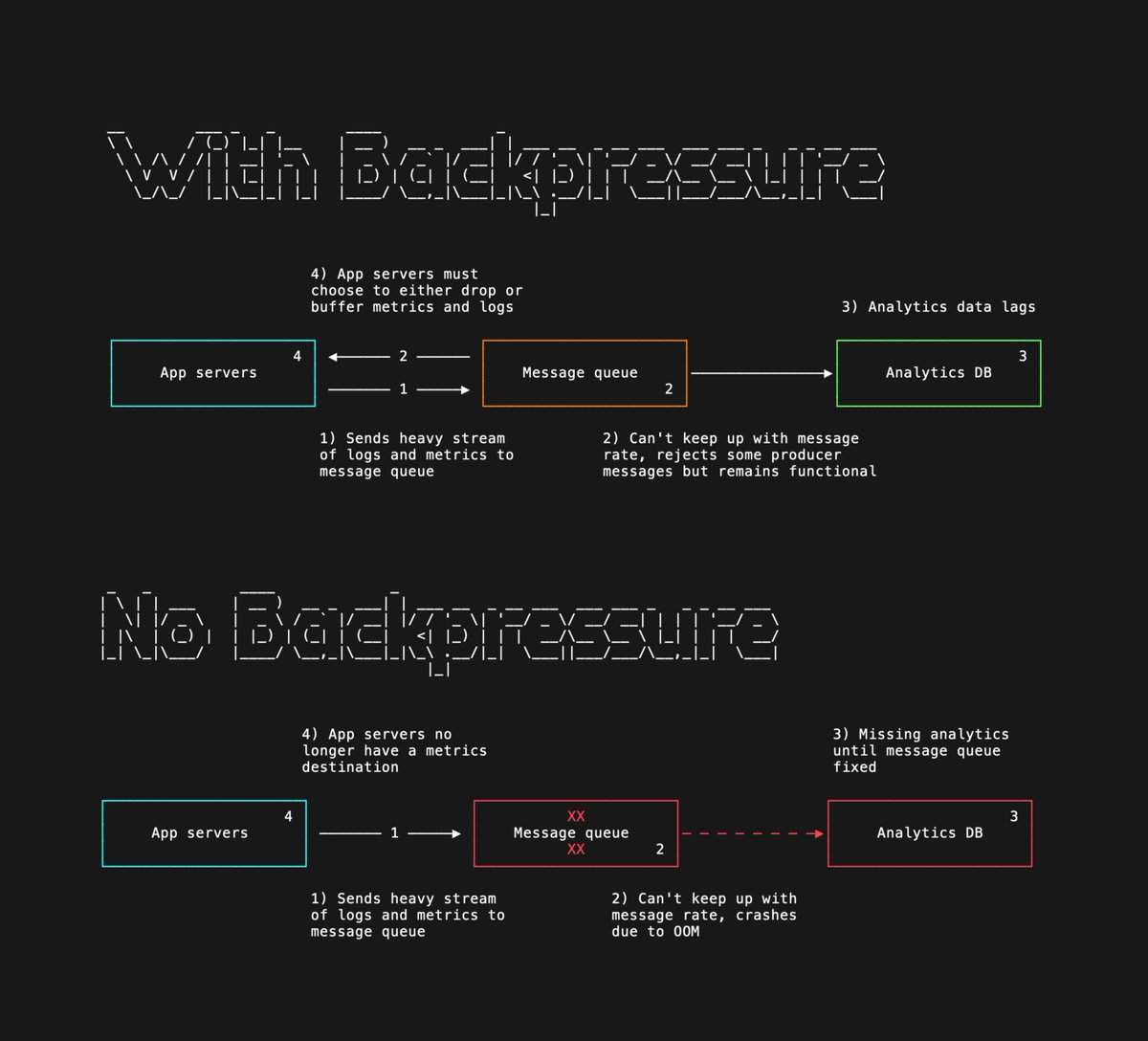
Backpressure is key for well-behaved infrastructure.
When databases, message queues, connection poolers, or other systems get overloaded, how do they deal with the pressure?
Some software responds by allowing their resources to exhaust and end up in a crash / failure state (OOM, etc). This behavior is simple from an implementation perspective, but causes cascading issues that can lead to total system failure and even data loss. Not good!
A better approach: each component applies backpressure to its clients. Backpressure is the idea that, when a software service detects it is at or nearing capacity (max connections, using all available memory buffers, etc) it communicates this back to clients either via explicit messages or connection rejections. In other words, it protects its own health at the cost of declined or slow service to some clients.
When backends are designed to respect backpressure signals, unexpected load spikes cause degraded performance, rather than taking the whole system offline.
English
@MarcJBrooker @VKazulkin Fix the limitations that have 99% of the impact, not the 1% use cases
English

Can adding an index bring down the cost of that SQL query from $0.00000208 to $0.00000018? And how would you know?
Aurora DSQL's new EXPLAIN ANALYZE VERBOSE feature tells you exactly how much a SQL query costs to run, so you can see exactly how tuning efforts affect your cost.
English
@marcusjihansson @ayushswrites @rankintweets Email me jeff at mabbly dotcom. We have a position that you may be interested in.
English

@ayushswrites @rankintweets @ayushswrites I am an AI engineer you are looking for.
Tech stack:
Python: data analysis, FastAPI, MCP
AI: LoRa fine tuning, PyTorch, Tensorflow, Transformers, DSPy, Langchain, AgnoAGI
Go: Server, Client, CLI, TUI
SQL: I have used both PostgreSQL and GraphQL
Docker: yes
English

if you’re an exceptional engineer, i will trade my corner office with you if you come join us at warp
we’re hiring like crazy. send dm to me or @rankintweets
Ayush S@ayushswrites
Finally finished my new office at warp hq
English

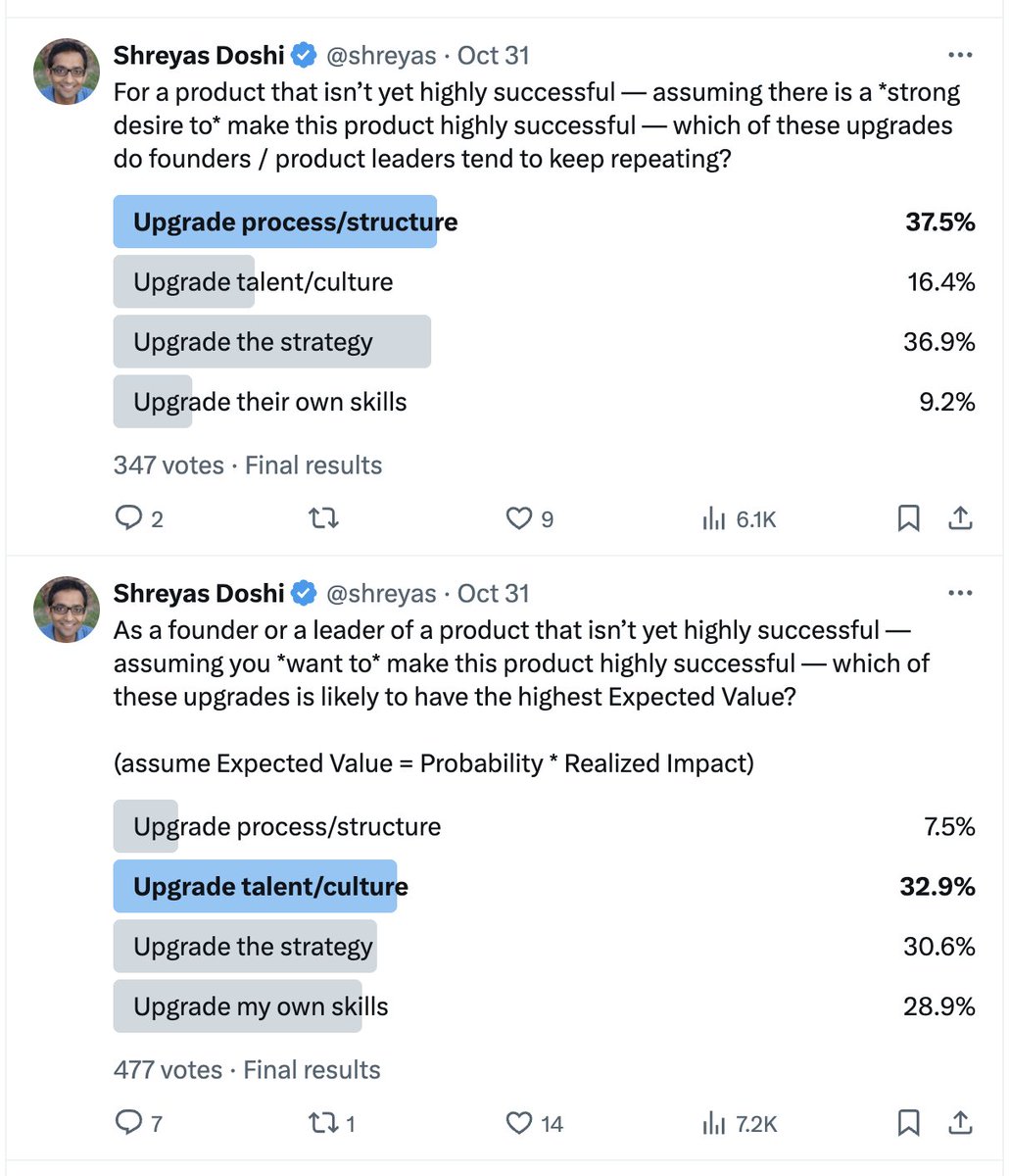
For folks who want to think more deeply and correctly through such questions (because that matters a lot in your day to day job as a founder or product leader), this Claude chat might be a useful read:
claude.ai/share/71122ed1…
English
Take a minute to observe these results (after noting that the question isn’t about an already successful product—it’s about a product that isn’t yet highly successful). Optionally, share how the 2 polls explain why so many products are unsuccessful in practice, in the real world.
English

@Shashikant86 @PromptEngConf @DSPyOSS Would love some material on GEPA/RAG and if any eval was done.
English


YouTube
English
🎥Video: My talk from @PromptEngConf London🇬🇧 is now live! (Not really video but audio with slides)
🎤 “Beyond Handcrafted Prompts: The Era of Prompt Optimization.” which covered
🧠 DSPy → @DSPyOSS turns prompts into programmable modules
🧬 GEPA → evolves prompts through reflection and mutation
🌐 Context Engineering → because context is the new compute
🤖 Agent Optimization → You need optimize everything in Agentic system like RAG, MCP Tools, Memory not just prompts.
Special mention to @hammer_mt at the end for his amazing talk on DSPy + GEPA in London Agentic AI Meetup. Amazing discussion with @JacquesVerre from @Cometml on end to end Agent Optimization with industry standard optimizers! Amazing conference indeed.
📹 Link to the Talk 👇
#DSPy #GEPA #PromptOptimization #ContextEngineering.

English


Embarrassed to say I missed this awesome addition to #GEPA!
An Adapter letting devs use GEPA to optimize RAG systems across the entire vector dB ecosystem in an integrated way regardless of the preferred vector store. Adapters for the core dBs built-in 👍 github.com/gepa-ai/gepa/b…
English

Anyone got a success story they can share about fine-tuning an LLM?
I'm looking for examples that produced commercial value beyond what could be achieved by prompting an existing hosted model - or waiting a month for the next generation of hosted models to solve the same problem
English
@CShorten30 Would have been great to explain from a business perspective when use what. Would help sell the product as well
English

Open-sourcing retrieve-dspy! 💻🚀
While developing Search Mode for Weaviate's Query Agent, we dove into the literature. It was amazing, and overwhelming, to see how many different takes on Compound Retrieval Systems there are! 📚
From perspectives on Reranking, such as to reason, or not to reason with Cross Encoders, Sliding Window Listwise Rankers, Top-Down Partitioning, Pairwise Ranking Policies, .... to Query Expansion, such as HyDE, LameR, ThinkQE, ..., Query Decomposition, Multi-Hop Retrieval, Adaptive Retrieval, and more...
There are endless design decisions for building Compound Retrieval Systems!! 🛠️
Inspired by the work on LangProbe from @ShangyinT et al., retrieve-dspy is a collection of DSPy programs from the IR literature. I hope this work will help us better compare these systems such as HyDE vs. ThinkQE, or Cross Encoders vs. Sliding Window Listwise Reranking, and understand the impact of DSPy's optimizers! 🧩🔥
The first step of many, repo linked below!

English
@lateinteraction @a1zhang I wonder how this could help RAG but through prompts and getting to the right context at different points but not sure if I'm thinking about this right
English


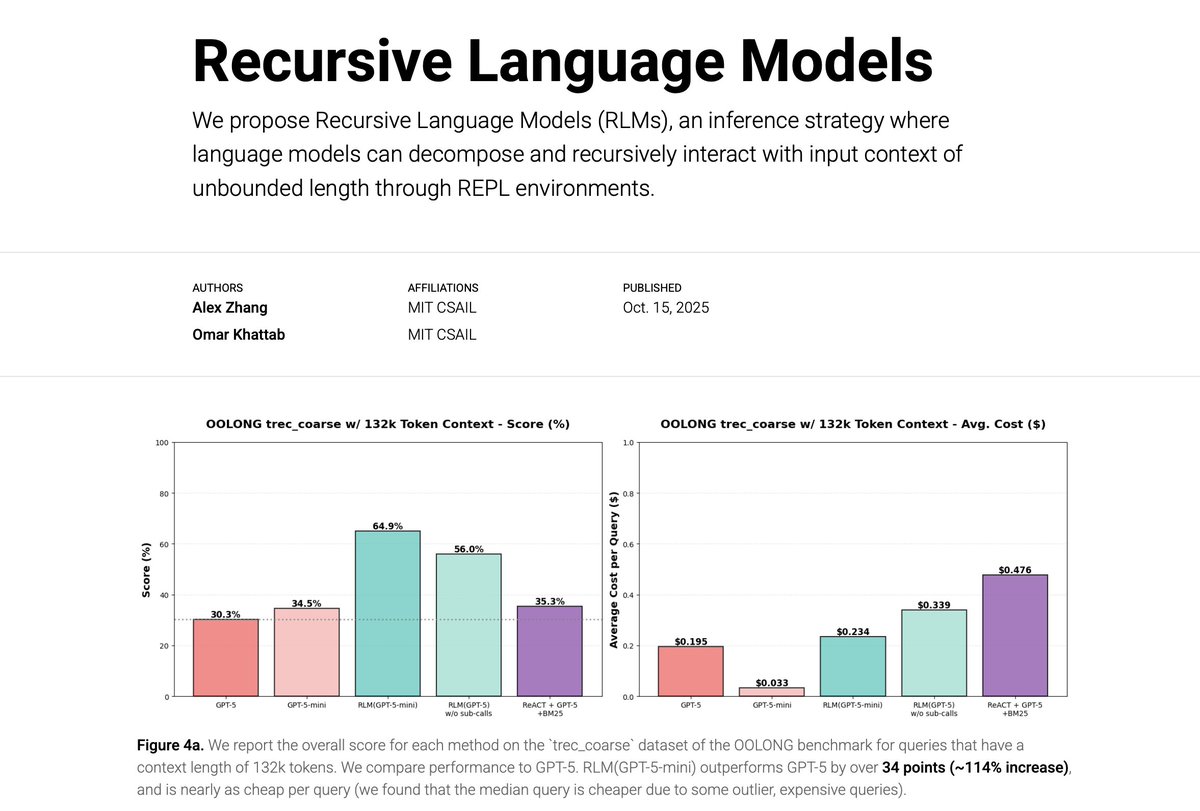
What if scaling the context windows of frontier LLMs is much easier than it sounds?
We’re excited to share our work on Recursive Language Models (RLMs). A new inference strategy where LLMs can decompose and recursively interact with input prompts of seemingly unbounded length, as a REPL environment.
On the OOLONG benchmark, RLMs with GPT-5-mini outperforms GPT-5 by over 110% gains (more than double!) on 132k-token sequences and is cheaper to query on average.
On the BrowseComp-Plus benchmark, RLMs with GPT-5 can take in 10M+ tokens as their “prompt” and answer highly compositional queries without degradation and even better than explicit indexing/retrieval.
We link our blogpost, (still very early!) experiments, and discussion below.
English

Most developers confuse RAG with memory.
They’re NOT the same thing. And using RAG as a substitute for memory is why agents keep forgetting important context.
Let’s break this down:

English