
Hammerhead Research
143 posts

@hammerhead_res @WaterworldCapi1 Is this a good business? Expedia’s is OK. They announce many partners but majority of the growth here is Amex Card program. Look at how many metal cards Amex has added and the ADRs come in at 3-4x.
English
@4drant @WaterworldCapi1 Seems like the current guide is a bit sandbagged, and the stock might pop on the dividend instatement (for some reason, European investors seem to care about stuff like that).
If it hits >8x P/E, it's a short IMO. I think bed bank take rates will normalize at <5% long term
English


@WaterworldCapi1 In B2B, OTAs have right to win vs bed banks (eg HBX or WebBeds)
Vastly superior tech stack, benefits from last-min bookings & agentic commerce
Lots of synergies between B2C & B2B -> lower effective CAC + cost to serve
Rate parity tracking & enforcement (see EXPE/Marriott)
2/2
English
@WaterworldCapi1 EXPE's B2B biz is a ~third of its revenue, and their solutions (Rapid API, TAAP, etc) were uncontested #1.
Over L2Y, BKNG has finally begun to push hard in B2B. Cleveland says it's ~12% of rev. now and growing fast. BKNG Mgmt is pretty tight lipped about their B2B plans
1/2
English
@henryF015 @WaterworldCapi1 BKNG is the best R/R within traveltech:
1. Geo mix matters for disintermediation risk - Euro hotel mkt is far more fragmented & less tech savvy than US
2. Genius program is a major differentiator. Best managed loyalty program by far
3. Untapped top-line levers - B2B, ads, etc
English
Hammerhead Research retweetledi

Seems there is a surprising amount of confusion / nonsense on my timeline about "Mythos vs. open models" even among people who are usually sensible (+usual twitter toxoplasma of rage). I like the work of both @AnthropicAI and @Aisle_Inc, so here are some takes:
1. Anthropic is not a household name yet, but is a big brand with a lot of visibility among people who broadly follow tech and AI. This has the effect that even if there is prior work doing something similar / comparably impressive, it usually has way less exposure. Often 10-100x more people learn about something when Anthropic publishes their version. In a variant of the Matthew effect, non-experts often assign most or all credit to Anthropic, by virtue of not being aware of prior work. And are more surprised.
Seen this multiple times in research just in the past few months: persona selection model, emotion vectors, now: impressive/scary cyber capabilities.
It is usually at least moderately annoying from the perspective of niche experts who are also impressed, but often not impressed by the same things.
2. Mythos is clearly a very impressive model with scary capabilities. "Huge discontinuity in cyber-risk" needs more subtlety in what the comparison is. If old models + minimal harness, there is a large gap. If SOTA harness/scaffolded system like what AISLE does, the difference between "raw Mythos" vs. "SOTA scaffolding + other models" can be moderate, small (or even non-existent).
I don't know, and possibly no one does right now: Anthropic likely does not have SOTA harnesses for bug finding; startups who work on this likely do not have access to Mythos.
Some evidence comes from the fact AISLE was finding & fixing hundreds of 0-day vulnerabilities in a similar weight category as what Anthropic published, often in major parts of internet infrastructure like OpenSSL or curl, and in decades-old code, all before Mythos. (And maybe ~99% of people who see Anthropic + Mythos as a step change haven't noticed this, including various highly visible pundits.)
3. My overall take is this matches the general intuition where a great harness often buys you ~up to one generation of model capability on tasks which are not really optimised during model training.
Anthropic seems to aim for RSI and the actually optimised tasks seem to be coding and ML, not vulnerability discovery. I would guess where Mythos is actually a bigger jump is automated exploit construction.
4. AISLE wrote a blog showing small models can often notice the same things, and arguing for the importance of the harness. These results are in my view interesting, although obviously the question is sensitivity AND specificity, and to what extent you can automatically eliminate false positives with further tooling. (AISLEs prior successes show you can, they are a few people + automated pipeline, not some labour-intense bug hunting)
5. The post got noticed on twitter. Various fundamentally unserious people like @ylecun took it as an opportunity to dunk on Anthropic, claiming it's all BS, hype, etc. (This is nonsense)
6. The counter-reaction was to point out limits of the AISLE blogpost, mostly based on the correct claim that finding the relevant part of the code is a large part of the problem. Toxoplasma of rage amplifying reactions and over-reactions to the most bizarre Mythos-denialism nonsense.
7. In some people's minds this grew out of proportion, taking the fact that AISLE provided the specific part of code as some sort of killer argument making AISLE's findings worthless. (Anthropic's @mooncat_is: "We took the needle the model found, isolated the relevant handful of the haystack, and then gave it to a small child, who found the needle as well.")
In fact this does not settle the question. As the AISLE original post explains, the inference cost difference is large enough that you can run the small model on every such code chunk individually. So the right comparison may be needles/$. Also: Anthropic did also split the heap into smaller chunks, running the analysis per file.
The deeper question is actually similar to some classical question about HCH: if you have a large number of people working each for 30 minutes, how does that compare to one human working for 10 hours? If you have a large number of IQ 130 humans working for long time, how does that compare to one IQ 150 human?
Where current cyber capabilities fall is ultimately an empirical question. As @boazbarak noted, people from the harness company tell you the harness is important, people from the model company tell you the model is important. I'm somewhat in between - both are important now, harnesses can compensate for ˜1 generation; yes, in the limit the models will likely just build their own scaffolding.
Also: if "cheap quantity can't compete with superior concentration of intelligence" were generally true, it would be actually very scary for AI safety: "scaling oversight" plans fundamentally depend on weaker intelligences overseeing stronger ones, compensating through effort, quantity, and orchestration.
English
@deanwball Yep. The cope is so insane and some commentary verges on bad faith
English

It’s crazy that some are just straight up in denial about mythos having the capabilities anthropic says it does. Usually the in-denial-about-AI community is able to cloak their views in at least *some* intellectual garb, but this time it’s just, “it’s not real.” Wild. Also sad.
English

#Jukan_on_China
Competition among Chinese robotics companies right now is beyond intense.
Yu Hao, the founder and CEO of Dreame, reportedly said that they should bring in Unitree’s chief scientist even if it costs RMB 200 million, or about $30 million, and instructed his team to poach all of the competitor’s customers, bidding projects, and even employees.
He even wrote in an internal chat that anyone who took a screenshot and leaked it externally would be fired immediately, yet someone still leaked it anyway. 🤣
English
@lurker123470654 @RayFernando1337 red.anthropic.com/2026/mythos-pr…
Anthropic included detailed descriptions of the process & results on here.
For each bug, Anthropic committed the SHA-3 hash and will reveal in <6mo. after the bugs have been patched. Seems highly unlikely that they are lying or exaggerating
English



Project Glasswing FAQ:
Q: Why only 12 companies?
A: They're the ones who can afford us.
Q: What about open-source maintainers?
A: We found bugs in their code. You're welcome.
Q: Will you release the tool publicly?
A: We said "cybersecurity is the security of our society." We didn't say which society.
Anthropic@AnthropicAI
Introducing Project Glasswing: an urgent initiative to help secure the world’s most critical software. It’s powered by our newest frontier model, Claude Mythos Preview, which can find software vulnerabilities better than all but the most skilled humans. anthropic.com/glasswing
English
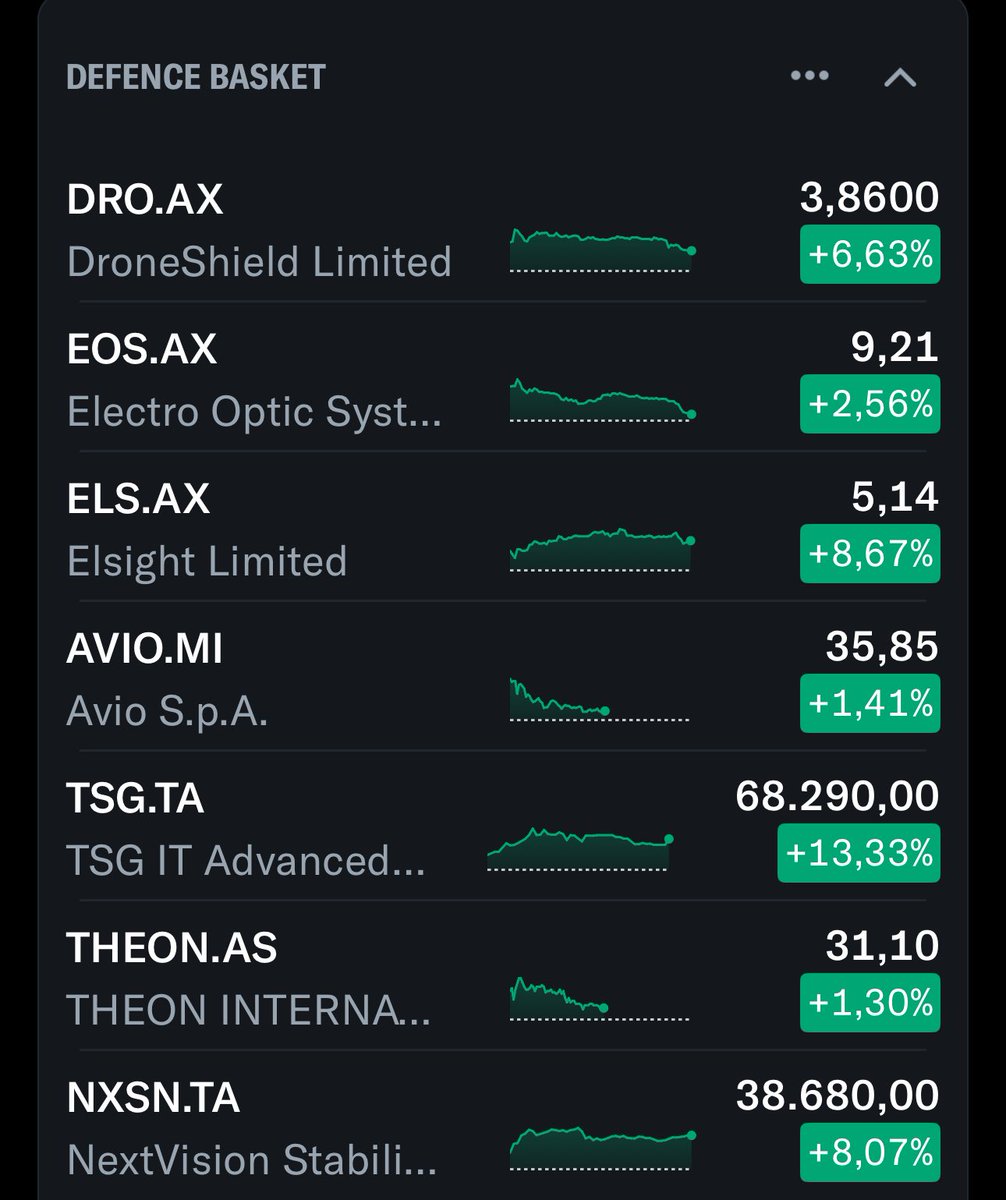
@finphysnerd @SimeonResearch_ Agree with the sentiment, but it's hard to short in any meaningful size. DRO.AX has lost share to Dedrone & mgmt. is shady, but defense spending tailwind is huge. German retail interest is quite high too
English

@SimeonResearch_ One of these things is not like the other. (It's $DRO.ax, complete shitco)
English

QME

Short $ATEC after 4Q'25. Sales growth should decel in FY'26 as competitor products reach parity and salespeople churn from the roll-back of high commissions. TAM within spine is also ~42% smaller than bulls think.
Overall reminds me of $INSP setup although less of a smoking gun
English
@Camvas_ai @PrefShares Hi - I am unable to DM but would love to try this out / chat further!
English

@PrefShares Works just like an analyst. You upload case studies, patterns, investment criteria on whatever you are looking for. And its a continuous, persistent research tool. Custom tech stack.
English

Legitimate question — I’ve heard some investors/funds say that they are “deploying agents.”
What does this mean? I feel like I’m pretty on top of this stuff & I have dozens of skills in Claude code and Claude.ai that I use both in code and in Excel (model automation, summarization, exporting, etc.). My primary workstation is Claude Code & Claude for Excel.
None of these are autonomous agents though? Are people actually building fully autonomous agents, or is this just marketing speak?
English

Good news $TH
investors.targethospitality.com/news/news-deta…
English

Maybe we should make our full report available for free on here and our website. It answers plenty of questions posed in the comment section. If $MTN was not burdened by debt as well as a dividend then it would likely reinvest heavily in the experience across its network. Selling Park City to a dedicated owner still benefits from the Epic Pass Netwok will accelerate much needed improvements at PCMR and the rest of the mountains in the $MTN portfolio.
@jason@Jason
.@vailmtn is the worst run company in America We need to get @eastdakota on the board and start a turnaround Safety, food, value, staffing, snow production and crowds — all disgraziad!! Who’s with me?
English
@WaterworldCapi1 $MH on Inclusive Access growth. Best execution in the college textbook space, long runway for continued transition to IA, clear path to delever & eventually return capital
English