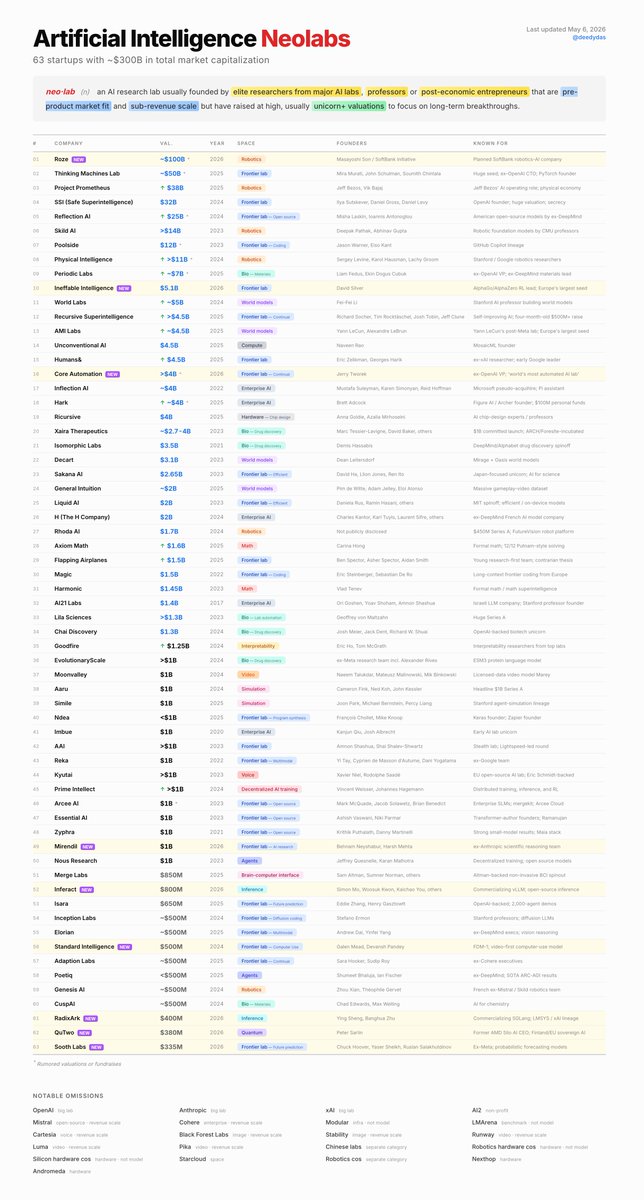
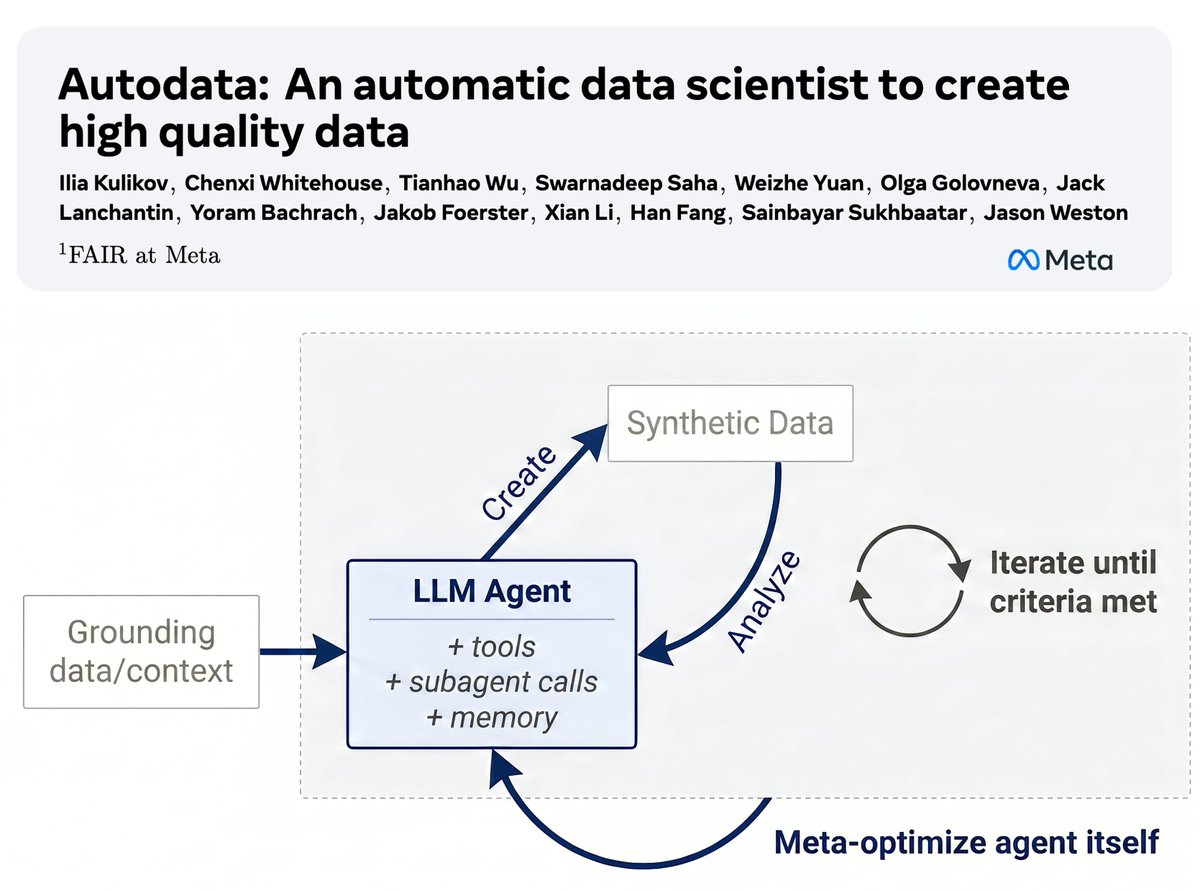
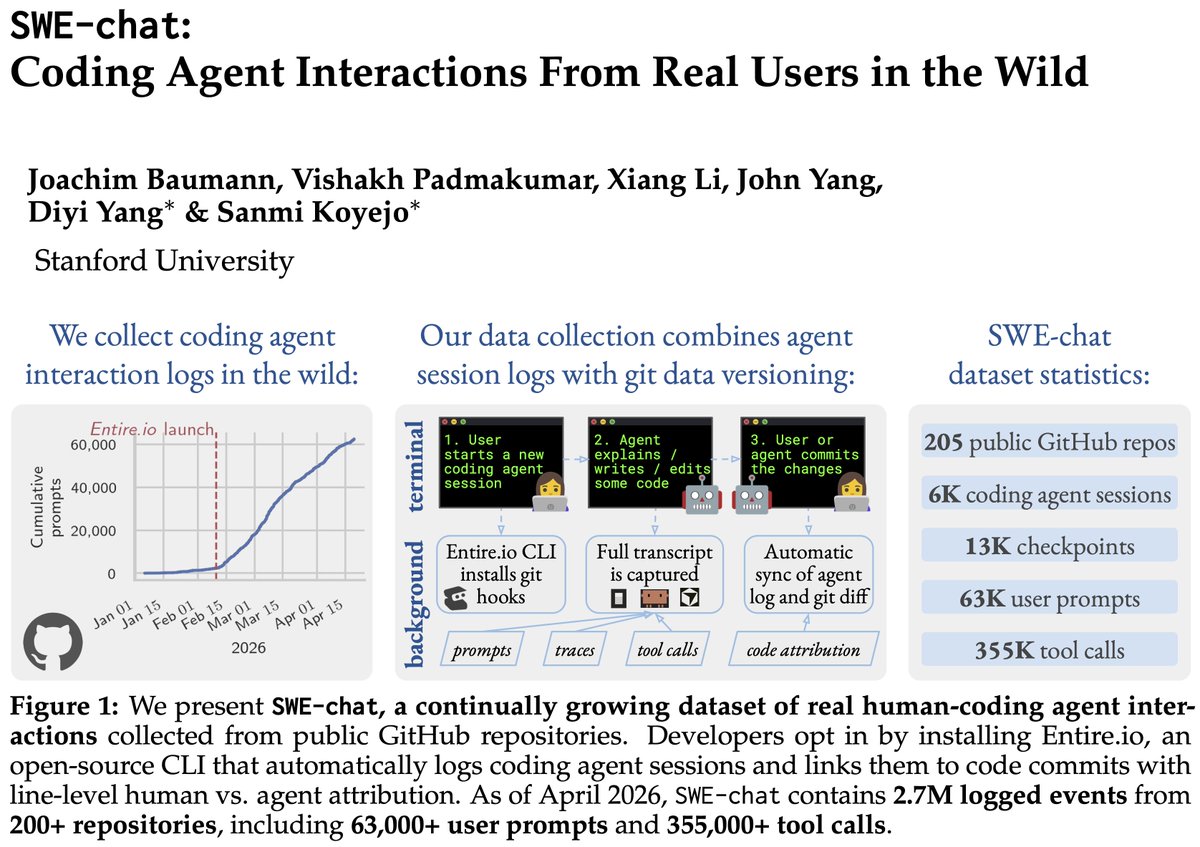
RadixArk@radixark
Today, we are thrilled to officially launch RadixArk with $100M in Seed funding at a $400M valuation. The round was led by @Accel and co-led by @sparkcapital.
RadixArk exists to make frontier AI infrastructure open and accessible to everyone. Today, the systems behind the most capable AI models are concentrated in a small number of companies. As a result, most AI teams are forced to rebuild training and inference stacks from scratch, duplicating the same infrastructure work instead of focusing on new models, products, and ideas.
RadixArk was founded to change that. We are building an AI platform that makes it easier for teams to train and serve the best models at scale.
RadixArk comes from the open-source community. We started with SGLang, where many of us are core developers and maintainers, and expanded our work to Miles for large-scale RL and post-training. We will continue contributing to both projects and working with the community to make them the strongest open-source infrastructure foundations for frontier AI.
We would like to thank our long-term partners, contributors, and the broader SGLang community for believing in this mission. We're also grateful to @Accel and @sparkcapital, NVentures (Venture capital arm of @nvidia), Salience Capital, A&E Investment, @HOFCapital, @walden_catalyst, @AMD, LDVP, WTT Fubon Family, @MediaTek, Vocal Ventures, @Sky9Capital and our angel investors @ibab, @LipBuTan1, Hock Tan, @johnschulman2, @soumithchintala, @lilianweng, @oliveur, @Thom_Wolf, @LiamFedus, @robertnishihara, @ericzelikman, @OfficialLoganK, and @multiply_matrix among others.
Thanks for the exclusive interview with @MeghanBobrowsky at @WSJ about our vision.