Narutatsu Ri retweetledi

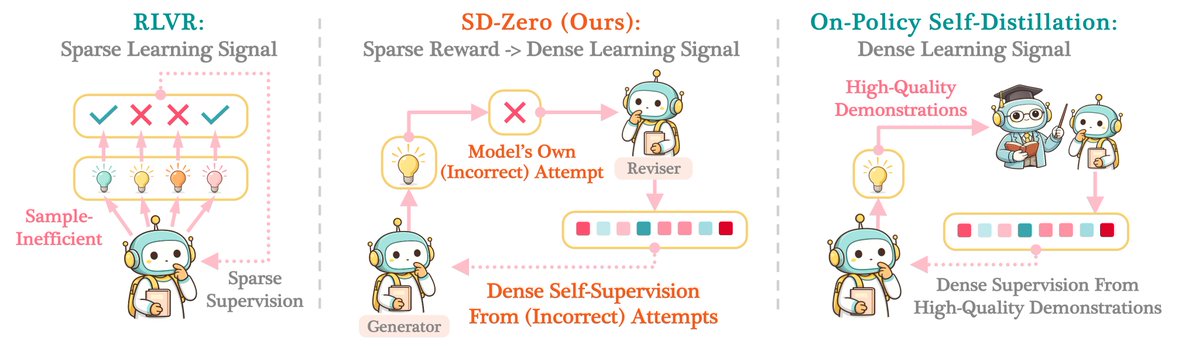
RLVR gives sparse supervision; On-Policy Self-Distillation often requires high-quality demonstrations. Our new method, ✨SD-Zero✨, gets the best of both worlds – we use model’s self-revision to turn binary rewards into dense token-level supervision. No external teacher. No curated demonstrations.
🚨 Introducing Self-Distillation Zero (SD-Zero), which trains one model to play two roles: (1) “Generator” that makes attempts, and (2) “Reviser” that conditions on the generator’s failed/successful attempt + binary reward to produce a better answer. ‼️Even WRONG attempts can become the training signal.‼️
🔗Paper: arxiv.org/abs/2604.12002
🏆 SD-Zero brings 10%+ improvement over base models (Qwen3,4B; Olmo3,7B) on math & code reasoning, beating GRPO and vanilla On-Policy Self-Distillation under the same training budget. SD-Zero also enables iterative self-evolution.

English