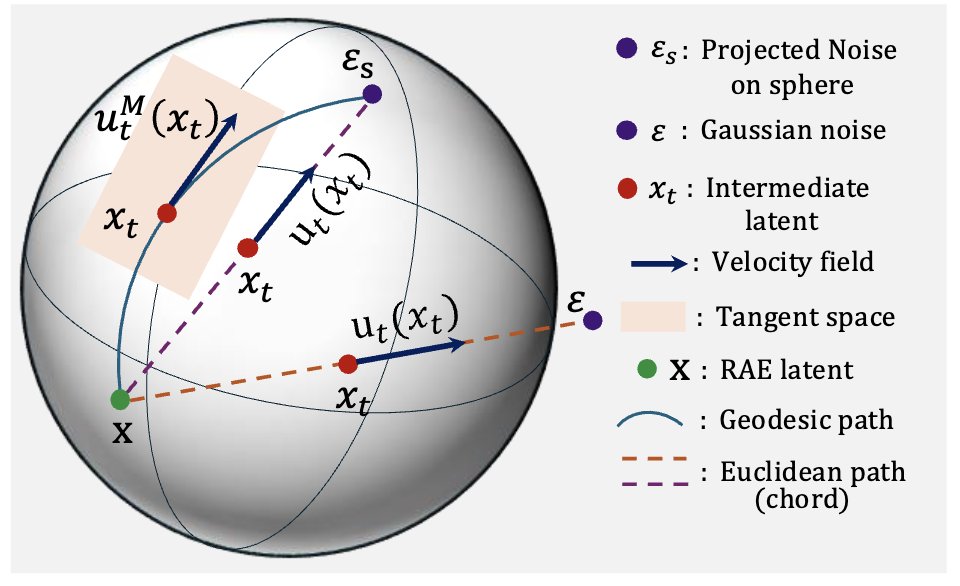
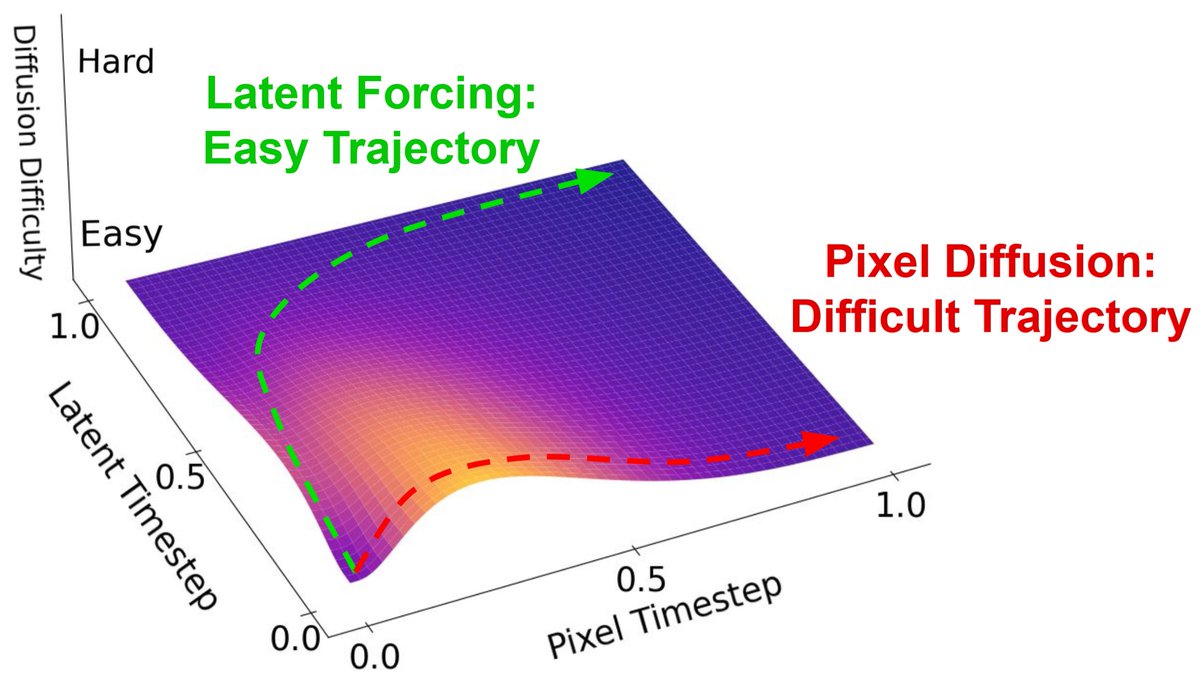
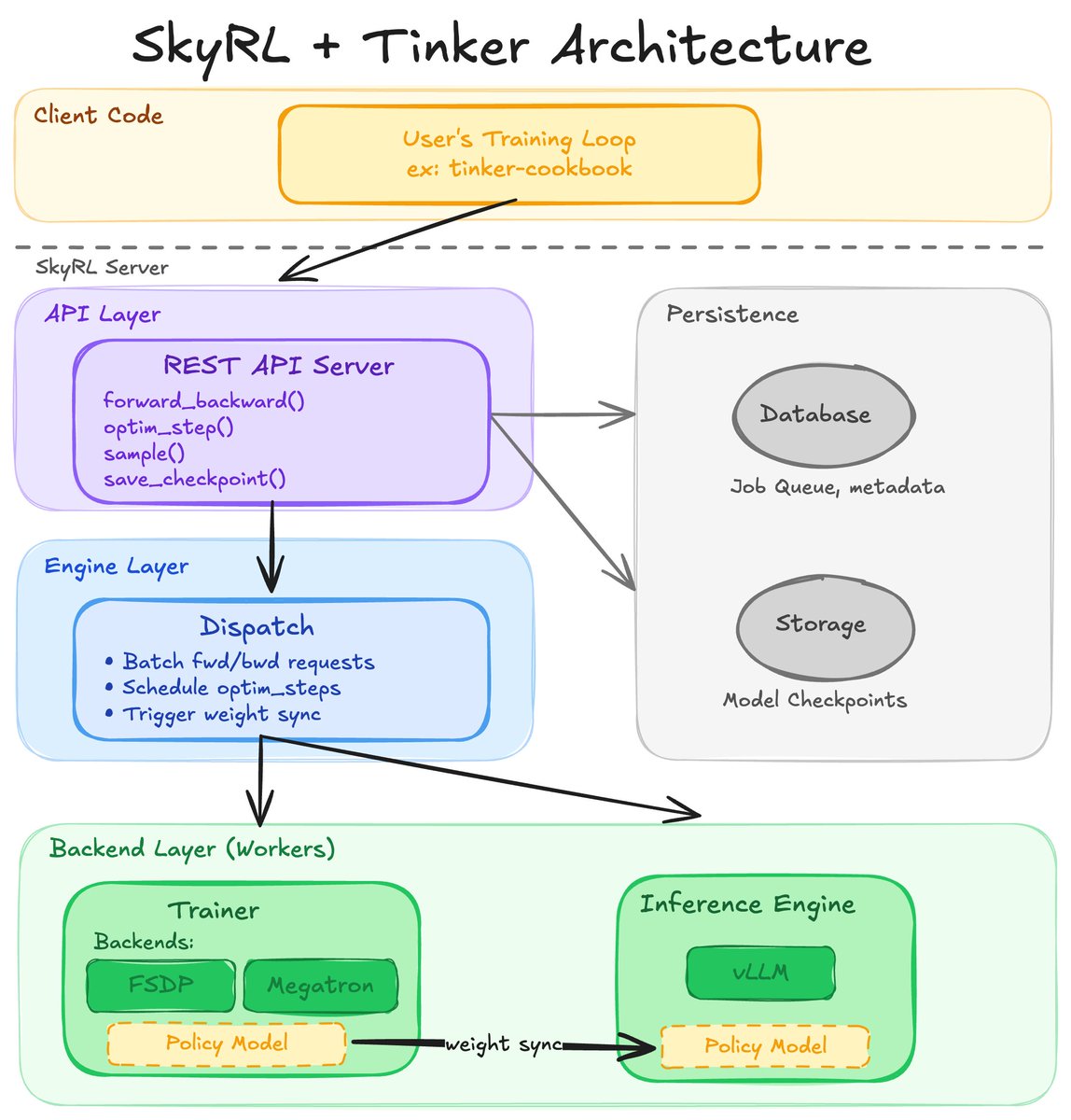
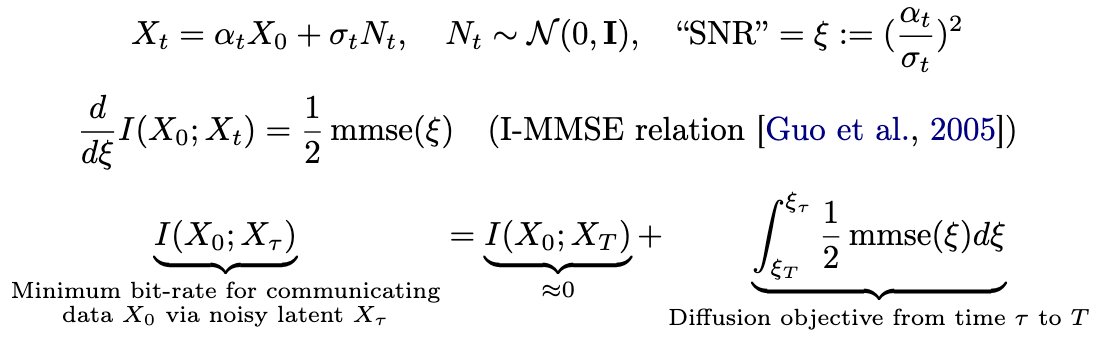Nikhil Barhate retweetledi

Apparently it is not well known and not easy to see that this "simple masked loss" is EXACTLY gradient-equivalent to PPO-Clip (at least for one way of computing the mask).
Here's how to see this:
The standard token-level PPO-Clip objective is the rather unintuitive
J_t = min(r_t A_t, clip(r_t, 1 - eps, 1 + eps) A_t)
To understand what's going on, split by cases:
1) Positive advantage: J_t = r_t A_t if r_t <= 1 + eps, else constant (clipped)
2) Negative advantage: J_t = r_t A_t if r_t >= 1 - eps, else constant (clipped)
So when we differentiate, we either get grad r_t A_t = r_t A_t grad log pi_t, or we get 0 if the token got clipped.
So we can use the objective J_t = M_t A_t r_t with gradient
grad J_t = M_t r_t A_t grad log pi_t,
where M_t = stop-grad((A_t >= 0 AND r_t <= 1 + eps) OR (A_t < 0 AND r_t >= 1 - eps))
In other words, PPO-Clip is gradient-equivalent to a simple masked loss. The loss value may differ, but it produces identical gradients.
And so we see that actually, PPO-Clip is really quite intuitive. John just wanted to make sure that we are paying attention.
wh@nrehiew_
Official confirmation that Periodic Labs uses a simple masked importance sampling RL loss
English