@TheEthanDing that ic that convinced their excited manager this was a cutting edge idea in 2026 should get a bonus though
English
Noah
156 posts

New research from Databricks: the context window is the only persistent substrate today's LLM agents have, and it floods fast. A single SQL query can return millions of rows that ride along in every subsequent turn, even when only one cell ever mattered. We hit this constraint every day in the agents we run in production, from Genie to Agent Bricks' Supervisor Agent to KARL. In a new post from the Databricks research team, we introduce MemEx: a programmable Python scratchpad that lets agents transform, slice, and persist tool outputs as typed objects in a live kernel. Same observe-act loop. Different action space. Across nine frontier and open-weight models on two enterprise agentic tasks (OfficeQA Pro and Enterprise Structured Retrieval): • Frontier models (Opus 4.6, Sonnet 4.6, Gemini 3.1 Pro) gain 2 to 5 accuracy points at 25 to 30% lower cost • Qwen 122B and Qwen 397B nearly double accuracy at 40 to 50% lower cost • Four of the five points on the OfficeQA Pro cost-accuracy Pareto frontier are MemEx configurations MemEx extends the code-as-action line (CodeAct, Anthropic Programmatic Tool Calling, Cloudflare Code Mode) with persistent scope across turns, eager spawn_agent for parallel sub-agents that share the parent's namespace, typed submit() for validated returns, and live-object scope injection. Built on aroll, the same Databricks agentic rollouts framework already powering those production systems. MemEx is rolling out across Databricks first-party agents and Agent Bricks soon. If you build on Databricks agents today, you'll be able to try it. Full write-up: databricks.com/blog/memex-pro…

This is the debate we should have everywhere in America. In the richest communities. In the poorest. No community should live with this kind of senseless violence if we have solutions that stop it. "The certainty of being caught is the #1 deterrent of violent crime." -National Institute of Justice

We won't be far behind if C-22 passes. In its current state, VPNs would almost certainly require us to log identifying user data. Signal isn't headquartered in Canada so they can just shut off Canadian servers, but our HQ is. We pay an ungodly amount of taxes to this corrupt government, and in return they want to destroy the entire essence of our service to basically spy on its own citizens. Not happening. We'll move HQ and take our taxes elsewhere.









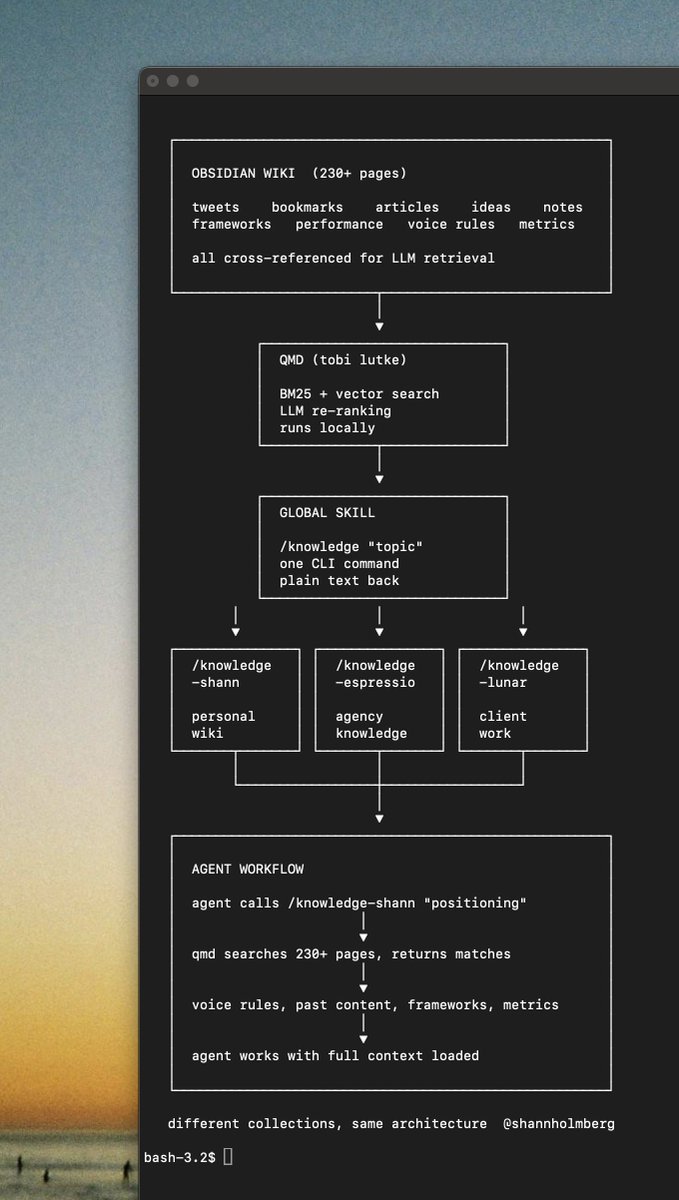

We've redesigned Claude Code on desktop. You can now run multiple Claude sessions side by side from one window, with a new sidebar to manage them all.



MICROSOFT BUILT A TOOL THAT CONVERTS LITERALLY ANYTHING INTO CLEAN MARKDOWN FOR YOUR LLM pdfs. word docs. excel. powerpoint. audio. youtube urls one pip install and your AI pipeline stops choking on raw files forever no custom parsers. no broken layouts. no garbled text. just clean, structured markdown your LLM can actually read github.com/microsoft/mark…