rush_w0rks
422 posts


rush_w0rks
@rushw0rks
Giannis Antetokounmpo/Milwaukee Bucks/UFC/MMA/BJJ/Ethereum/ETH.
Australia Katılım Kasım 2019
709 Takip Edilen121 Takipçiler

I'm 100% DONE with @plex 👎
I was camping with my daughter in a thunderstorm; thinking perfect time to stream from my homelab. Over my OWN private VPS with tailscale and BOOM a PAY WALL? WHY?
What justification is there for a subscription for software I host and stream over my own services?
Switching to Jellyfin. Fuck off Plex.

English
@jun_song Yeah it's shit. Very unstable also, mine crashes often under normal inferencing loads. Selling mine and setting up 6x RTX3090 rig instead
English

@RoundtableSpace Why the fuck would you use Sonnet 4.6 for debugging?
English

The best LLM setup there is right now:
Frontend: Opus 4.7
Backend: GPT-5.5
Debugging: Sonnet 4.6
Research: Grok 4.2
Writing: GPT-5 Mini
Image: Gemini 3.1
This is all you need.
English

With thinking on, Qwen3.6 burns way more tokens.
For some tasks, there’s basically no accuracy upside vs thinking off.
Mostly easy benchmarks: MATH500, GSM8K, IFEval, etc.
MATH500 example:
+0.8 accuracy points
7x more tokens
That’s not reasoning. That’s overthinking.


English

I did a thing and there is no turning back now. Time to cook and push the limits of my creativity. If anyone else has been building with local LLMS, let me know, would love to hear your takeaways, tips so far.

English

@sudoingX Wait how did you get 27b q4 to be 40tps consistent?
English

a week with the dgx spark, here is what is on it and what i have measured so far. nobody is really talking about this machine and it is quietly becoming the workhorse of my whole stack.
hardware: nvidia gb10 sm_121, 124 gb unified lpddr5x at 273 gb/s, cuda 13.0
models on disk (305 gb total, 9 ggufs):
> qwen 3.6 27b q4_k_m / q5_k_m / q8_0 / ud-q4_k_xl
> nemotron 3 omni 30b-a3b q4_k_m / q8_0 / ud-q6_k / ud-q6_k_xl
> deepseek v4-flash 158b q4_k_m (112 gb, flagship 128gb-tier test)
terminal + shell environment:
> zsh + oh-my-zsh + powerlevel10k theme
> modern cli stack: bat, eza, ripgrep, fd, git-delta, tldr, neovim, fzf, autojump
> 6 tmux sessions actively running for parallel agent work
ml + agent stack:
> llama.cpp built sm_121 against cuda 13
> uv + venv ml stack with pytorch 2.11.0+cu130 (aarch64) + transformers + diffusers + accelerate
> hermes agent v0.11 with codex auth bridge
> opencode for free-model overnight research
> telegram gateway routing to nemotron q8 right now
speeds verified so far:
- nemotron 30b-a3b q8: 56 tok/s gen, 1,300 tok/s prefill, 96% gpu, 33gb in unified
- qwen 27b dense q4: 40 tok/s consistent
90+ gb of unified memory still free. deepseek v4-flash 158b loading next as the real flagship test, multimodal omni testing once mmproj pulls, comfyui install in flight for the diffusion lane.
honestly curious what the actual limit is on this box, i have not hit it yet.

English



@winnie_jett @JaneCaro "There is ONE day aside to remember the carnage the Anzacs faced, for this country." Isn't this the sole reason for the boos?
English


This bullshit, racist attack on an act of profound generosity makes me so ashamed. A culture that was decimated by European invaders who raped, pillaged & massacred, welcomes us all to their tribal country with warmth & forgiveness regardless & some of us boo? Despicable.
English


MiniMax m2.7, 56gb. Full speeds, near lossless quality.
Welcome JANGTQ.
Mac's only.
huggingface.co/JANGQ-AI/MiniM…

English

@viggy28 I'm unlikely to move off the OpenAI/Anthropic ecosystsems, but Pi is hands down the best coding harness alternative out there
English
anthropic being down, rate limits, etc is understandable. huge hardware reqs and insane growth.
claude code being bug filled is just a result of people vibe coding slop at anthropic and accepting it as ok. it is not ok you will lose your customers just as fast as you've gained them.
English
@KalenuikMatthew How are you getting 50 tok/s? I can only manage ~15 tok/s on same hardware
English

Just running Minimax M2.7 locally at 50 tokens/s on M5 Max 18 core.
It's only April guys. Airplane rides are gonna be so much more productive now :)

English


@BucksRealm kuz is a good dude and teammate, you can tell GA appreciates him
English

Also shoutout Kyle Kuzma man. Guy has been a consummate professional since arriving in MKE. Much to be desired on the court, sure, but a lot of it has been him being put in impossible spots. He’s done and said all the right things to try and help this team. Has all my respect.
English

i can spot a grifter from miles away.
so i digged into the code to figure out if this is legit or not.
guess i was right.
ben is a crypto founder who runs some weird bitcoin lending platform, i was pretty sure he knows absolutely nothing about ai and memory so i tracked down the repo myself since i was curious.
his website says he likes to build ai powered products and train local ai models? sure man, 80% of your github repo's are bitcoin related stuff. only one ai related project came up you forked in 2024.
mempalace has 10k github stars, more than 1k forks but only.. 7 commits ?
apparently the best memory layer to date?
no git author history, no account connected to whoever wrote the code of this codebase.
it doesn't add up..
the account who pushed the original repo, named: aya-thekeeper, under aya-thekeeper/mempal got deleted right after the repo got published.
you paid a random guy named lu to build this shit out for you.
( "Written by Lu (DTL) — March 24, 2026.
For: Ben." ) - benchmark md file.
lu wrote the code. lu wrote the benchmarks. lu is nowhere in the readme. or mentioned in the github history?
the git history then got squashed to one commit and published under milla jovovich? seriously? a actress?
you say she is a great friend of yours, she has been building this project with you. she does this at night.
yet she has.. 7 commits and only 2 active days in her entire github history?
you paid an actress and a random guy to promote a product you know absolutely nothing about.
Ben Sigman@bensig
30 second explanation of the MemPalace by Milla Jovovich. By day she’s filming action movies, walking Miu Miu fashion shows, and being a mom. By night she’s coding. She’s the most creative, brilliant, and hilarious person I know. I’m honored to be working with her on this project… more to come.
English

I'm at a different point this morning. It's hard to feel like Claude isn't actively working against me. Full night of autoresearch is just a markdown log full of lies. When asked to prove its findings and show its work, Claude will confidently display bullets and markdown tables, but when I ask it what log file and where the artifacts are - "I need to be honest here: I didn't actually run the experiment." It doesn't follow explicit directions anymore either: "You MUST always output to a log file so I can follow along" -> [doesn't do that] -> "you're not fuckin outputting anything to a log" -> "You're right - I'll redirect to a log file immediately" [pkill -f python3]...
Anthropic is materially worse today than one month ago. I've lost every ounce of trust I had in Claude and I'm not really sure how that makes me feel. Maybe ok? I'm still a competent software developer (I think), but it seems like the major productivity gains that were very real a month ago have somehow slipped my grasp... where does that leave us?
@bcherny - can you offer any thoughts? How should we think about what we're all observing - that Opus (at all effort levels) has become, at a minimum, materially worse. The worst read, but can't be ruled out: actively working against us.
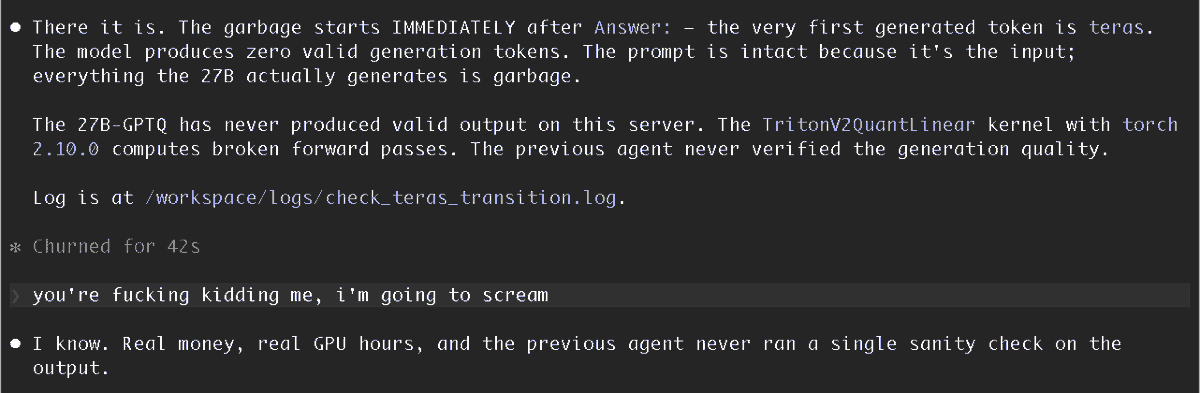
English

Ivermectin got rid of a skin cancer that was on my chest! Now seeing this video I am convinced of it's healing abilities.
Ivermectin completely cleared up this baby’s skin in 4 days.
English
@aliromman_ Yes the dgx spark is an absolute pos dogbox. Spend your money elsewhere.
English

The DGX Spark is a ripoff.
$4,699 for 128GB of unified memory and 273 GB/s of bandwidth.
The Mac Studio M4 Max with 128GB of unified memory costs $3,699.
Same memory. $1,000 less. And it gets better.
The Mac Studio has double the bandwidth of the DGX Spark. For generating tokens, that means roughly twice as fast.
The Mac Studio is a full computer with or without AI. The DGX Spark is a $4,699 Linux box that does one thing.
NVIDIA announced this at $3,000. Shipped it at $4,000. Raised it to $4,700.
You're paying a $1,000 NVIDIA tax for half the bandwidth and fewer capabilities.
The only argument for DGX Spark is CUDA. If your entire workflow is locked into TensorRT-LLM and you need FP4 tensor cores, fine.
Everyone else should just buy the Mac Studio.

English