
NeuralMyth
963 posts

NeuralMyth
@seoinetru
Unleashing imagination through neural network-generated fantasy art. Follow for captivating scenes and mystical creatures 🎨 #fantasyart #digitalart
Amsterdam, The Netherlands Katılım Mart 2015
80 Takip Edilen15 Takipçiler

【Intelの本気】LLMを爆速・超軽量化する「auto-round」が凄すぎる!
Intel開発の最新量子化ツール「auto-round」が登場!
AIモデルの精度を維持しながら、驚異的なメモリ節約を実現します。
・200Bの巨大モデルを20GBのGPUで動作可能に
・Intel CPU/XPUやNVIDIA GPUなど幅広く対応
・vLLMやllama.cpp、GGUF形式もフルサポート
低スペックPCでも高性能なAIが動かせる、まさに革命的なツールです!✨
#生成AI #LLM

日本語
NeuralMyth retweetledi


NeuralMyth retweetledi

I can’t believe I stopped using Claude Code max and entirely use DeepSeek and Hermes. It’s so fast, so so fast, 3x faster for the same task. So cheap. I spent $5 last week and never need worry about being rate limited or usage hit limits very two hours. For most tasks it’s perfect enough.
English
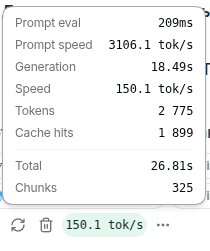
@xoofx But the network search was turned on, so it turns out 17 seconds of generation
English
@xoofx Memory: 125 GB (16 GB used, 109 GB available); swap 8 GB
CPU: AMD Ryzen 9 5950X — 16 cores / 32 threads, ~3.4 GHz (boost to 5.1 GHz)
GPU: NVIDIA GeForce RTX 4090 (AD102)
Polski

So I have built a local AI PC rig with 2 x AMD R9700 AI PRO 32GB, running on Ubuntu 24.04 server and tested unsloth/Qwen3.6-35B-A3B-GGUF/UD-Q4_K_XL - so it runs on a single GPU and it is producing 77.3 tokens per second, not bad! 🚀
That's the actual speed in the video recording:
English

Big moment for Soniox: Today we’re launching Soniox Text-to-Speech.
This is a major step forward for us. Soniox started with speech-to-text. Now, with both STT and TTS, we are becoming the voice platform for every language.
Soniox TTS is built for the hardest parts of speech generation:
- Native-speaker-quality speech in 60+ languages
- Hallucination-free speech generation
- Alphanumerics spoken correctly like numbers, IDs, addresses
- Correct pronunciation for names and foreign words
- Ultra-low-latency streaming for real-time voice applications
And the pricing is simple: $0.70 per hour of generated speech.
What excites us most is the bigger picture: Developers and companies can now work with one provider for the core voice stack: speech-to-text, text-to-speech, multilingual voice, real-time infrastructure, regional deployments, and compliance.
This is a big step in our transition from an STT provider to the voice platform for every language.
Voice is becoming a core interface for software. But to work globally, it has to be fast, accurate, robust, and affordable across every language. That is what we are building at Soniox.
Read the blog post: soniox.com/blog/soniox-te…

English

Just dropped two open-source models: MiMo-V2.5-Pro (Code Agent, 1T total) and MiMo-V2.5 (Multimodal Agent, 310B total).
Oh and one more thing — we're giving devs & creators 100T tokens on us. Go build something cool 🛠️
🎁 100T Free Token Grant for Builders 100t.xiaomimimo.com
Xiaomi MiMo@XiaomiMiMo
Xiaomi MiMo-V2.5 is now officially open-sourced! MIT License, supporting commercial deployment, continued training, and fine-tuning - no additional authorization required. Two models, both supporting a 1M-token context window : • MiMo-V2.5-Pro: built for complex agent and coding tasks, ranking No.1 among open-source models on GDPVal-AA and ClawEval • MiMo-V2.5: a native omni-modal model with strong agent capabilities A model's value isn't measured by rankings alone — it's measured by the problems it solves. Let's build with MiMo now! 🤗 Weights: huggingface.co/collections/Xi… 📄 Blog: #blog" target="_blank" rel="nofollow noopener">mimo.xiaomi.com/index#blog
English
NeuralMyth retweetledi

Por $60 dólares mensais você roda um LLM do nível do Opus 4.5 sozinho. Sem limite de tokens, sem cota, sem nerfarem seu modelo. Opensource.
Esse modelo aqui: huggingface.co/unsloth/Qwen3.…

Português
NeuralMyth retweetledi

Someone just built a PDF editor that's 10x smaller than Adobe and runs 100% offline.
It's called RevPDF. Edit text and images inside any PDF, redact, sign, split, merge, and convert, all on your device. No cloud, no signup, no account.
~20MB. Works on Mac, Linux, Windows, Android, and iOS.
100% Free.
English
NeuralMyth retweetledi

NeuralMyth retweetledi

Crazy expensive
Muapi is offering same api at 20-60% less price
Also allows faces unlike fal which rejects everything
fal@fal
Seedance 2.0 is now available to everyone without any restrictions! fal.ai/models/bytedan…
English

Seedance 2.0 is now available to everyone without any restrictions!
fal.ai/models/bytedan…
English
@bridgemindai Why is there no price in these tables, as for me the most important parameter?
English

Meta just dropped Muse Spark and it's beating Claude Opus 4.6, GPT 5.4, and Gemini 3.1 Pro on nearly every multimodal and reasoning benchmark.
But Claude Opus 4.6 still wins on agentic coding.
The one category that matters most to vibe coders.
Meta is back on the map.
The frontier just got a lot more crowded.

English

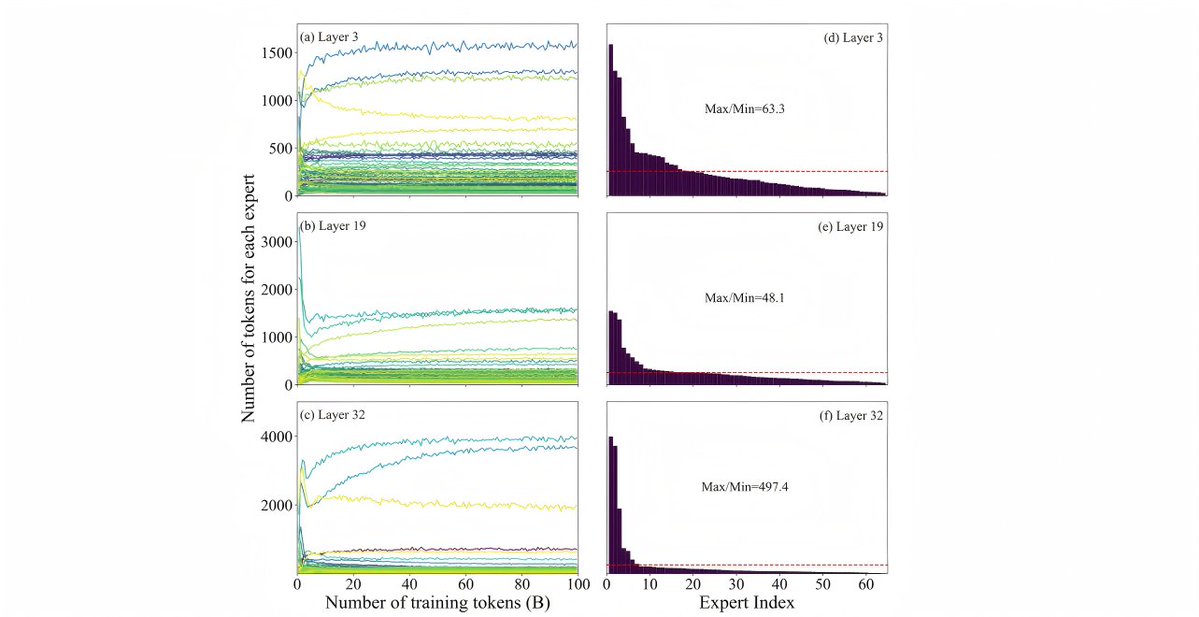
🚀Yuan3.0 Ultra: A Trillion-Parameter MoE Model Built for Enterprise AI
🏢Enterprise applications require more than chatbots—real-world workflows demand AI that can efficiently execute multi-step tasks. Yuan3.0 Ultra is the core engine powering enterprise AI agent deployment.
The Innovation: LAEP (Learning-based Adaptive Expert Pruning) Unlike traditional MoE models that sacrifice accuracy for speed, LAEP works with the way experts naturally specialize—pruning redundancies without disrupting functional structure.
Results:
✅️33% fewer parameters (1515B → 1010B)
✅️49% faster training
✅️Only 6.8% active parameters per token (68.8B)
✅️14% shorter outputs, 16% higher accuracy
Built for Enterprise: Document analysis, multi-source RAG, and intelligent tool selection that filters invalid requests.
👐Open source — weights + technical report available now.
github.com/Yuan-lab-LLM/Y…
English
🚀Trillion parameters. Zero compromises. 100% open source.
🔥Introducing Yuan 3.0 Ultra — our flagship multimodal MoE foundation model, built for stronger intelligence and unrivaled efficiency.
✅️Efficiency Redefined: 1010B total / 68.8B activated params. Our groundbreaking LAEP (Layer-Adaptive Expert Pruning) algorithm cuts model size by 33.3% and lifts pre-training efficiency by 49%.
✅️Smarter, Not Longer Thinking: RIRM mechanism curbs AI "overthinking" — fast, concise reasoning for simple tasks, full depth for complex challenges.
✅️Enterprise-Grade Agent Engine: SOTA performance on RAG & MRAG, complex document/table understanding, multi-step tool calling & Text2SQL, purpose-built for real-world business deployment.
📂Full weights (16bit/4bit), code, technical report & training details — all free for the community.
👉Learn More: github.com/Yuan-lab-LLM/Y…

English
@sama I'm not ready to pay for this yet, it's too crude and not very smart.
English

@sama It doesn't work well, the advice is stupid, he doesn't understand anything about design, it's useless.
English
More than 200k people downloaded the Codex app in the first day.
And they seem to love it.
CODEX FTW!
English

🥳 Introducing MiniCPM-o 4.5
The first full-duplex omni-modal LLM in open-source community 🎬🎙️
🔥 Key Highlights:
• Full-duplex Omni-modal Live Streaming: The model can see, listen, and speak simultaneously in a real-time conversation without mutual blocking
• Proactive Interaction: Moving beyond reactive QA to performing proactive interaction, such as initiating reminders
• Leading Performance: Scoring 77.6 on OpenCompass, it outperforms GPT-4o & Gemini 2.0 Pro in vision-language tasks with 9B params
The best part? You can experience all above on your PC!
#MiniCPM #OpenSource #MultimodalAI #LLM
English

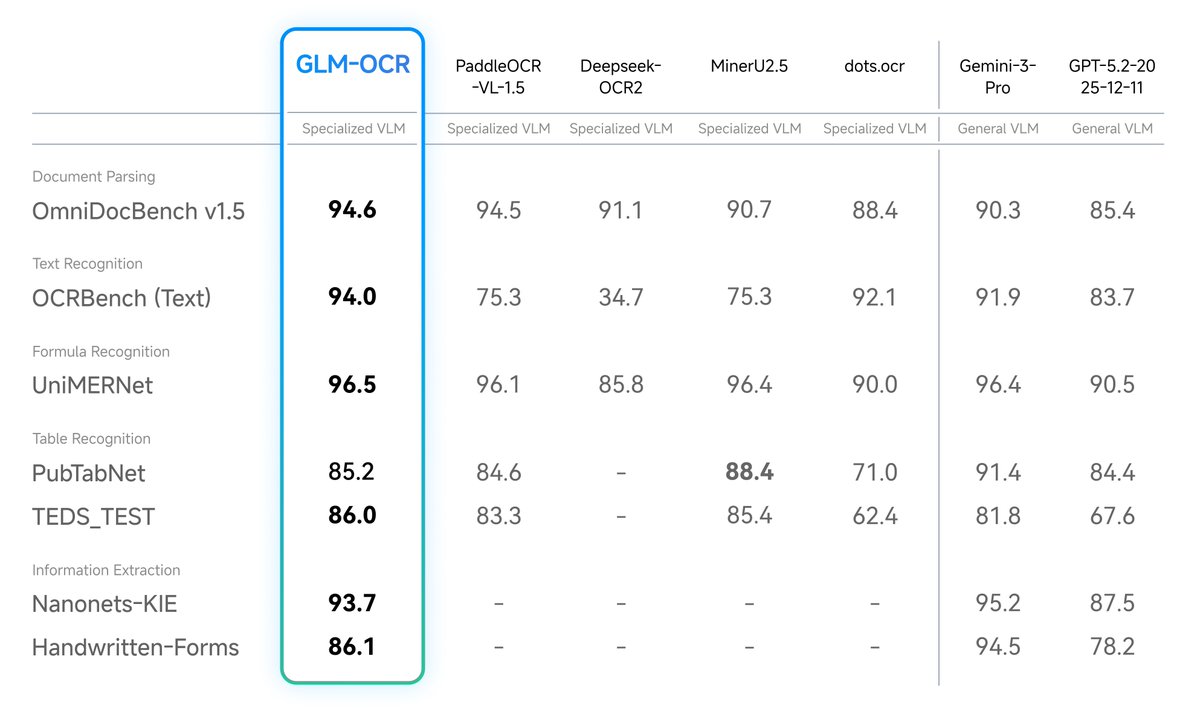
Introducing GLM-OCR: SOTA performance, optimized for complex document understanding.
With only 0.9B parameters, GLM-OCR delivers state-of-the-art results across major document understanding benchmarks, including formula recognition, table recognition, and information extraction.
Weights: huggingface.co/zai-org/GLM-OCR
Try it: ocr.z.ai
API: docs.z.ai/guides/vlm/glm…
English
@StepFun_ai It wouldn't be bad to improve your understanding of design
English

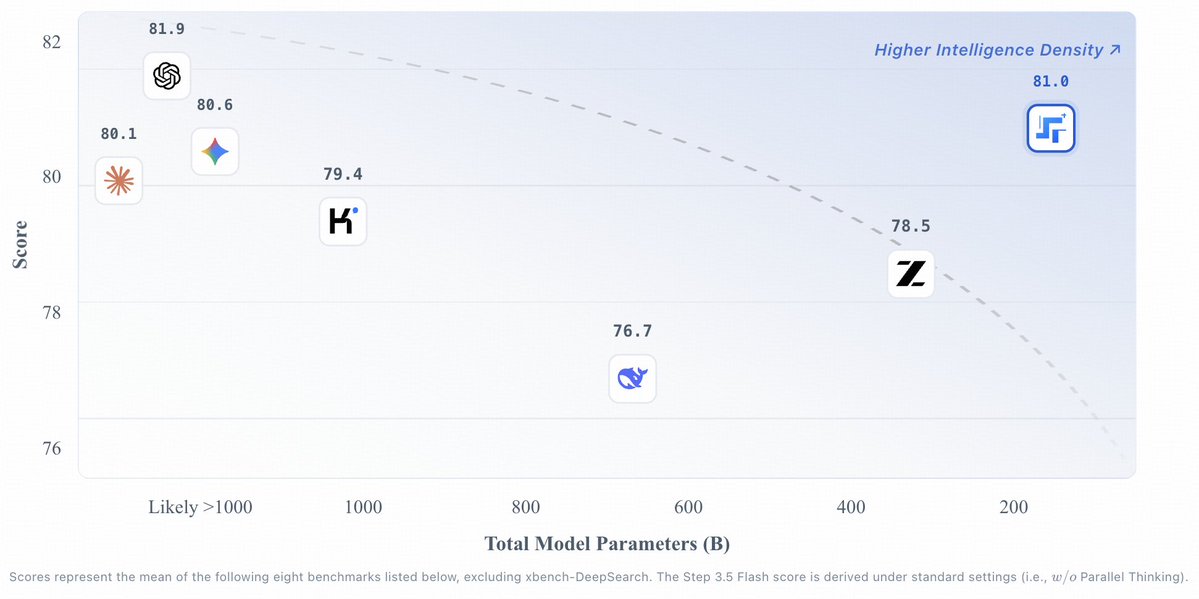
⚡️ Step 3.5 Flash is coming: Fast Enough to Think. Reliable Enough to Act!
We’re dropping our most capable open-source foundation model yet. Frontier reasoning meets extreme efficiency.
It leverages a sparse Mixture of Experts (MoE) architecture, 196B total → 11B active.
Key Capabilities:
✅Reasoning at Speed: MTP-3 powered throughput at 100–300 tok/s (350 tok/s peak for single-stream coding tasks).
✅Agentic Power: ⚡️ 74.4% SWE-bench Verified ⚡️ 51.0% Terminal-Bench 2.0. Proven stability for complex, long-horizon tasks.
✅256K Efficient Context: 3:1 SWA ratio + Full Attention. Massive datasets or long codebases support with minimal overhead. Consistent performance, hybrid efficiency.
✅Local-First Deployment: Optimized for Mac Studio M4 Max, NVIDIA DGX Spark. Secure, private, and frontier-capable. Your data, your hardware, your agent.
You can try Step 3.5 Flash right now:
👉 OpenRouter: openrouter.ai/stepfun/step-3…
👉 GitHub: github.com/stepfun-ai/Ste…
👉 HuggingFace:huggingface.co/stepfun-ai/Ste…
👉 Blog:static.stepfun.com/blog/step-3.5-…
👉 ModelScope: modelscope.cn/models/stepfun…
🌌 The Next:Step 4 training is officially LIVE!
We're calling on the world's boldest builders to co-creat the Step 4 right now. Let's define the Agentic Era together!
Join our Discord:discord.gg/RcMJhNVAQc
English