Sabitlenmiş Tweet

more of my tibetian yak herding gf thread
English
Steppe Cyber Vedic Futurist🕉️☸️ 🥩🌲
2.7K posts

@steppebuddha
join #kaliacc on urbit at: ~lavfun-fiplyr/kaliacc

The Railway dashboard is currently unavailable, and all running Railway services are down. We're working with our upstream provider to restore service. Updates: status.railway.com





What historical fact sounds fake but is true?



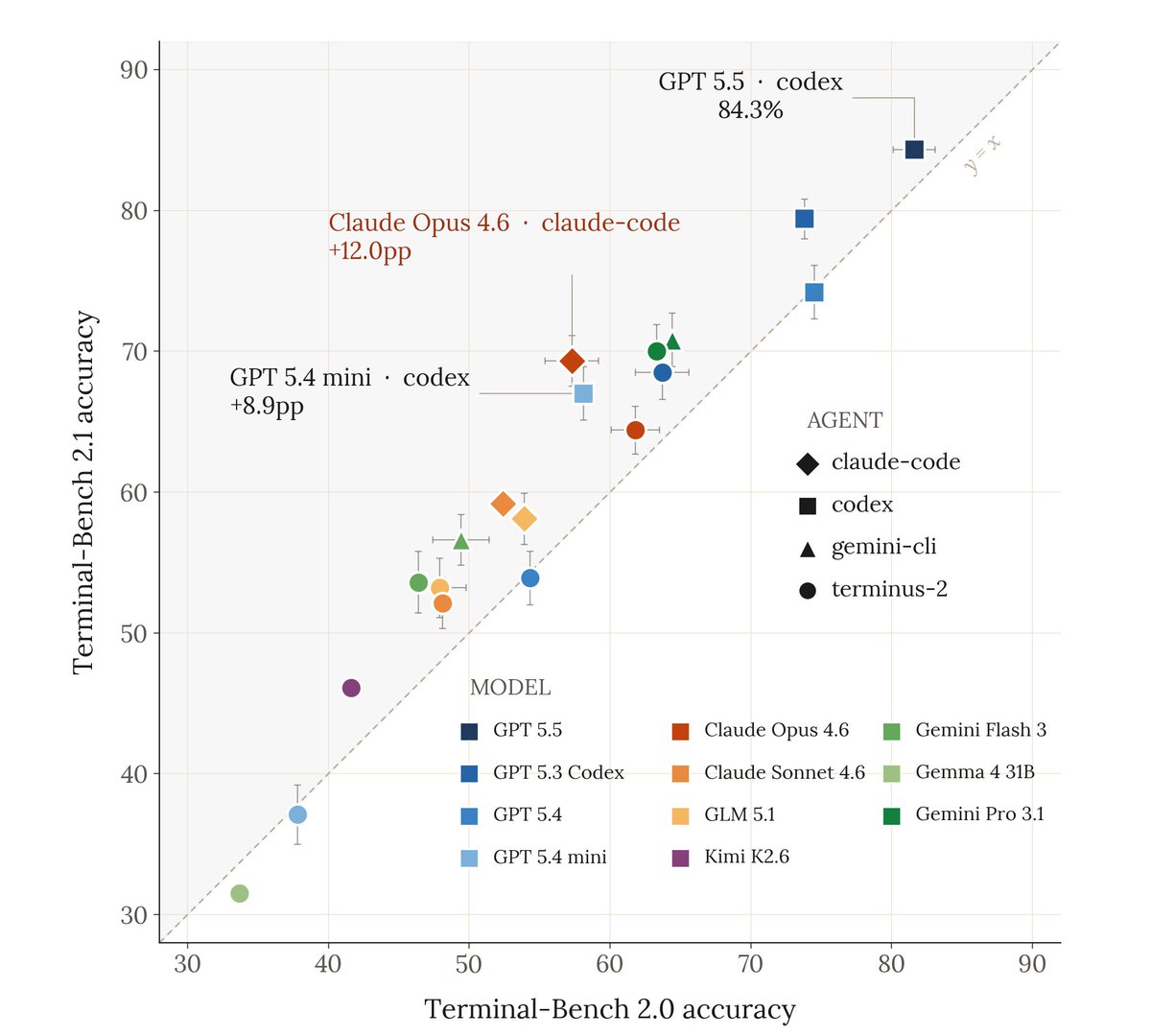


the Codex app turns 3 (months old) today. they grow up so fast











