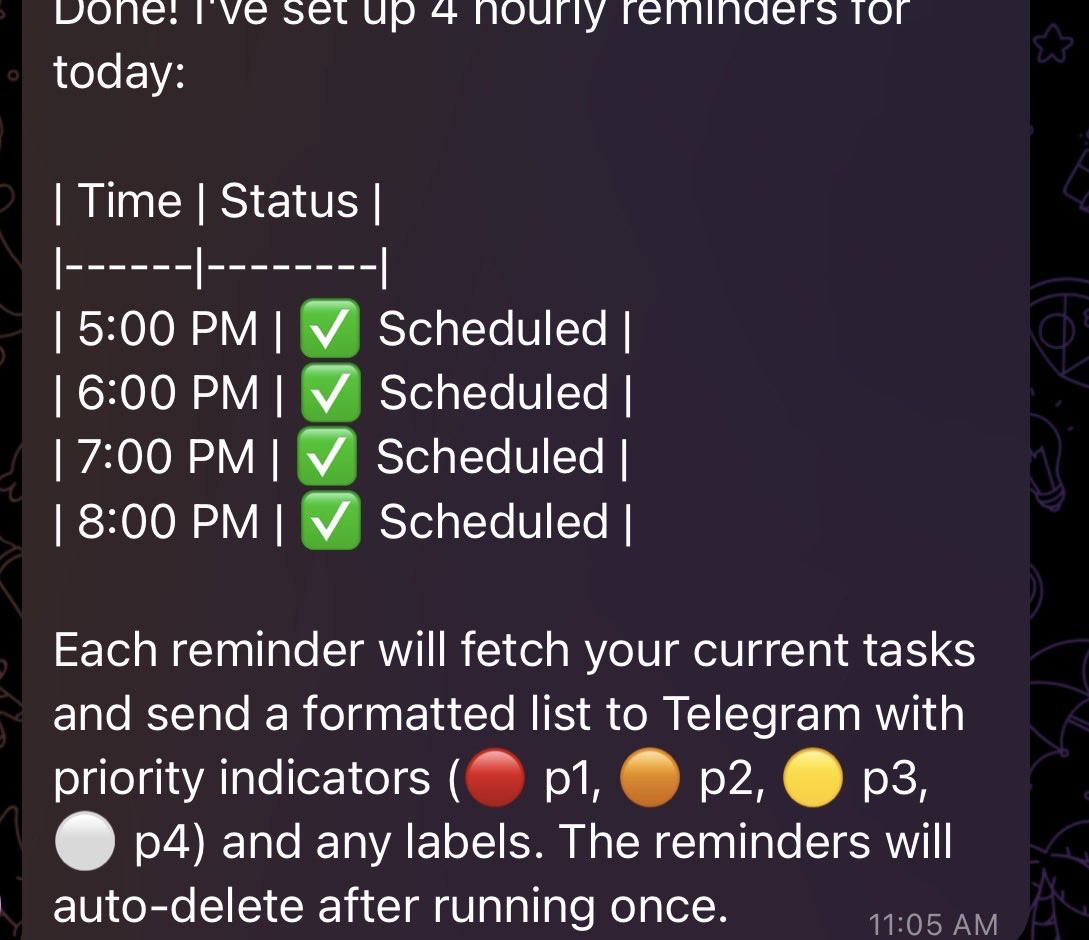
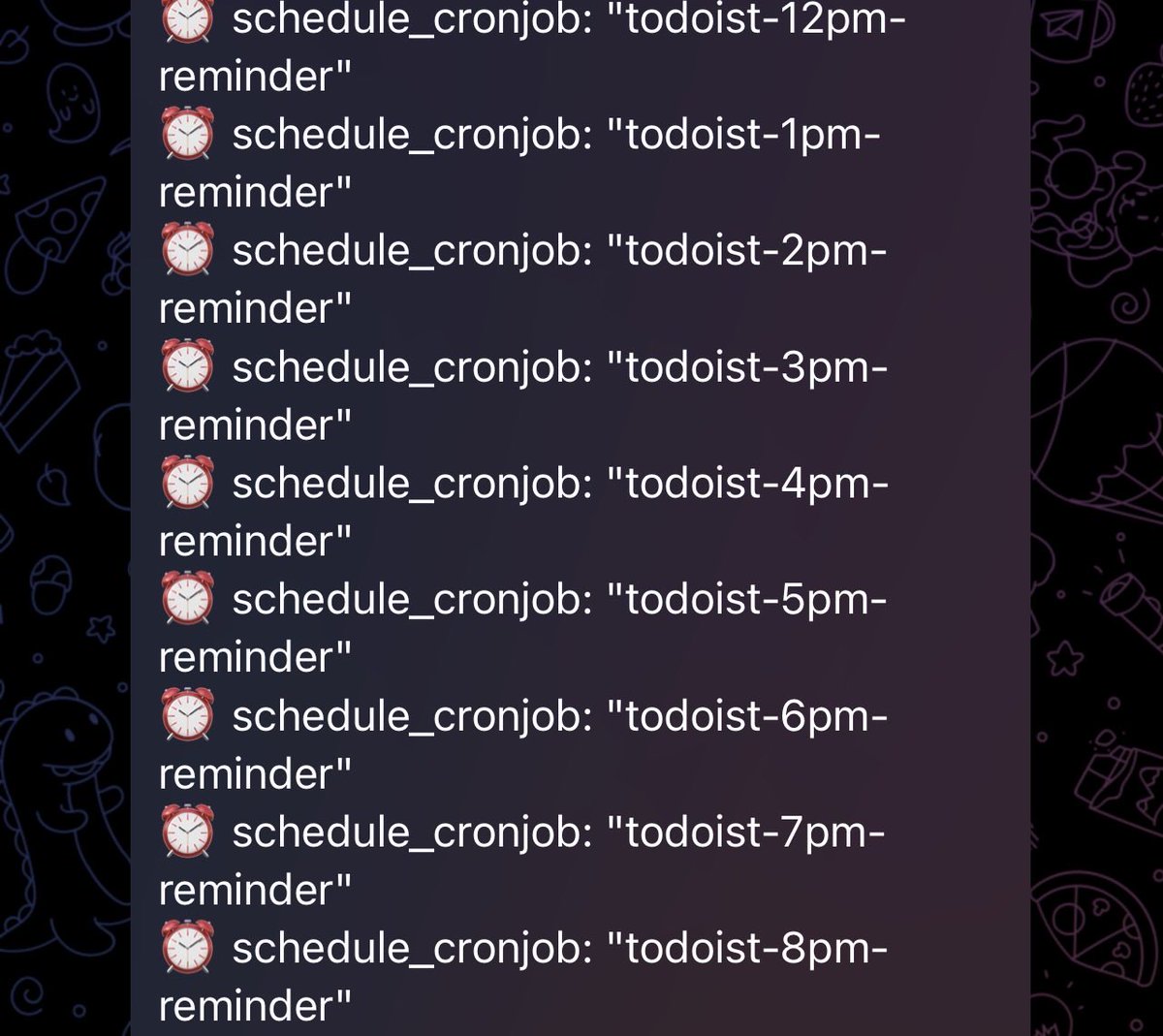
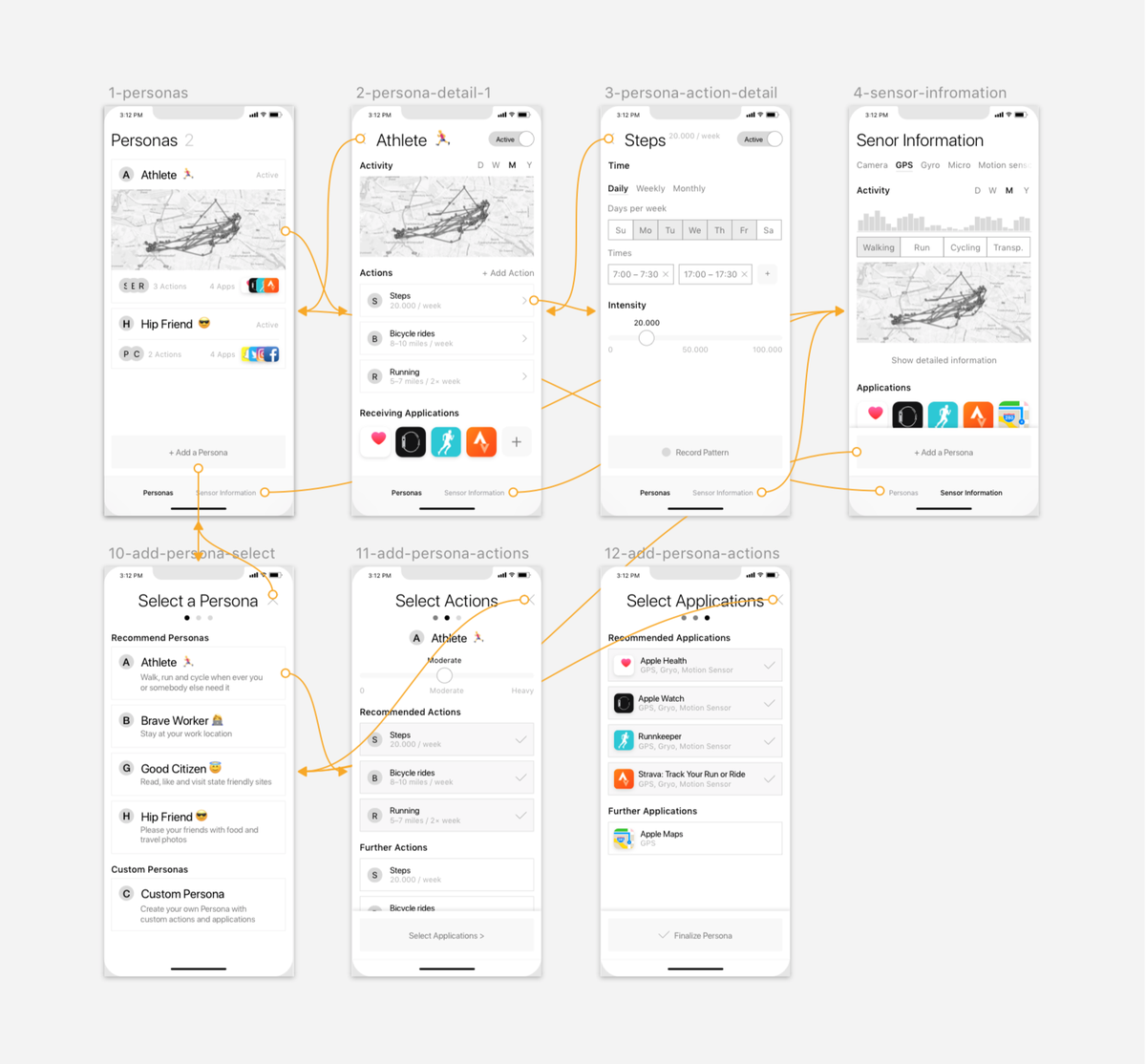
@witcheer @stackwalnuts Super relevant to what I'm trying right now on Hermes: Obsidian-backed memory with ongoing cycles so each run closes with structured updates and the next run starts from a fresh state + goals.
Keep us posted on week-one outcomes.
English