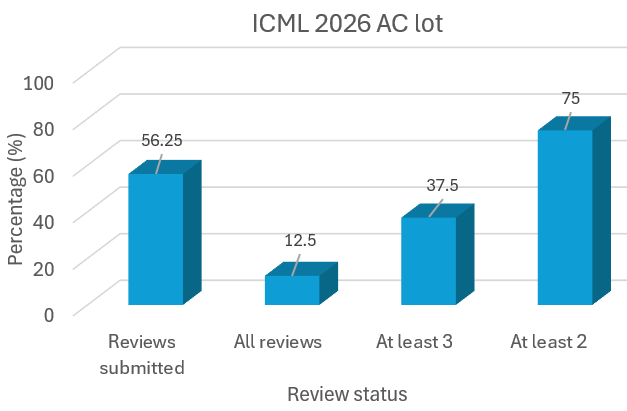
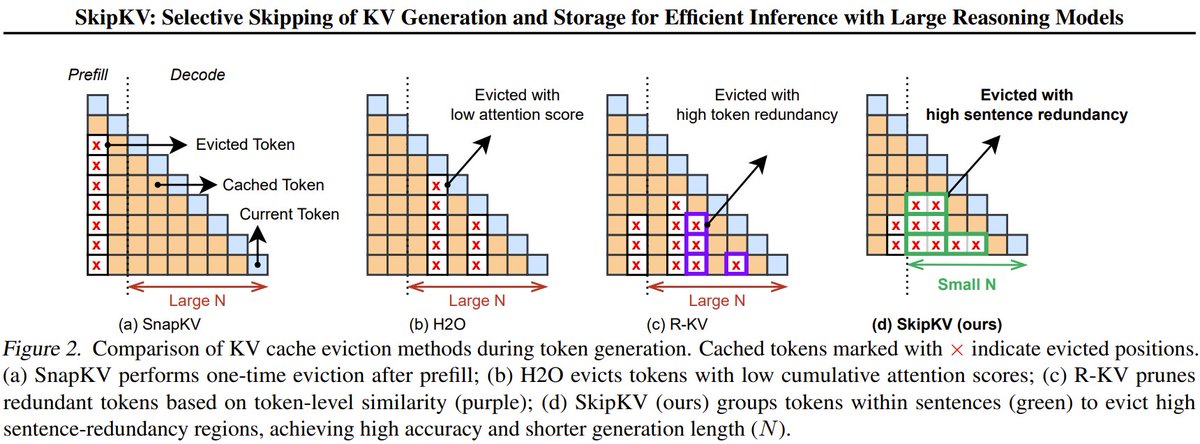
🎉🎉Announcing #ICML2026 workshop on "Multi-Modal Agentic AI": scale-icml-2026.github.io
Topics covered: 1. Agentic memory, 2. Efficient agentic AI systems, 3. Scaling of multi-modal agents, 4. Agents for Planning, 5. Evaluation, guard railing, and benchmarking of agents
🚀Confirmed speakers: @dasongle (GenBio) @mohitban47 (UNCCH) @james_y_zou (Stanford) @chelseabfinn (Stanford) @MengdiWang10 (Princeton) @sunjiao123sun_ (Google) @MikeShou1 (NUS) @MinhyukSung (KAIST)
With @HongyiWang10 @digbose92 @jaeh0ng_yoon @ManlingLi_ @nagsayan112358 @schowdhury671
#AgenticAI #MAS #MultimodalAI

English