Sabitlenmiş Tweet

Thoms Bosboom
9K posts

@thomasbosboom
Now at @[email protected]






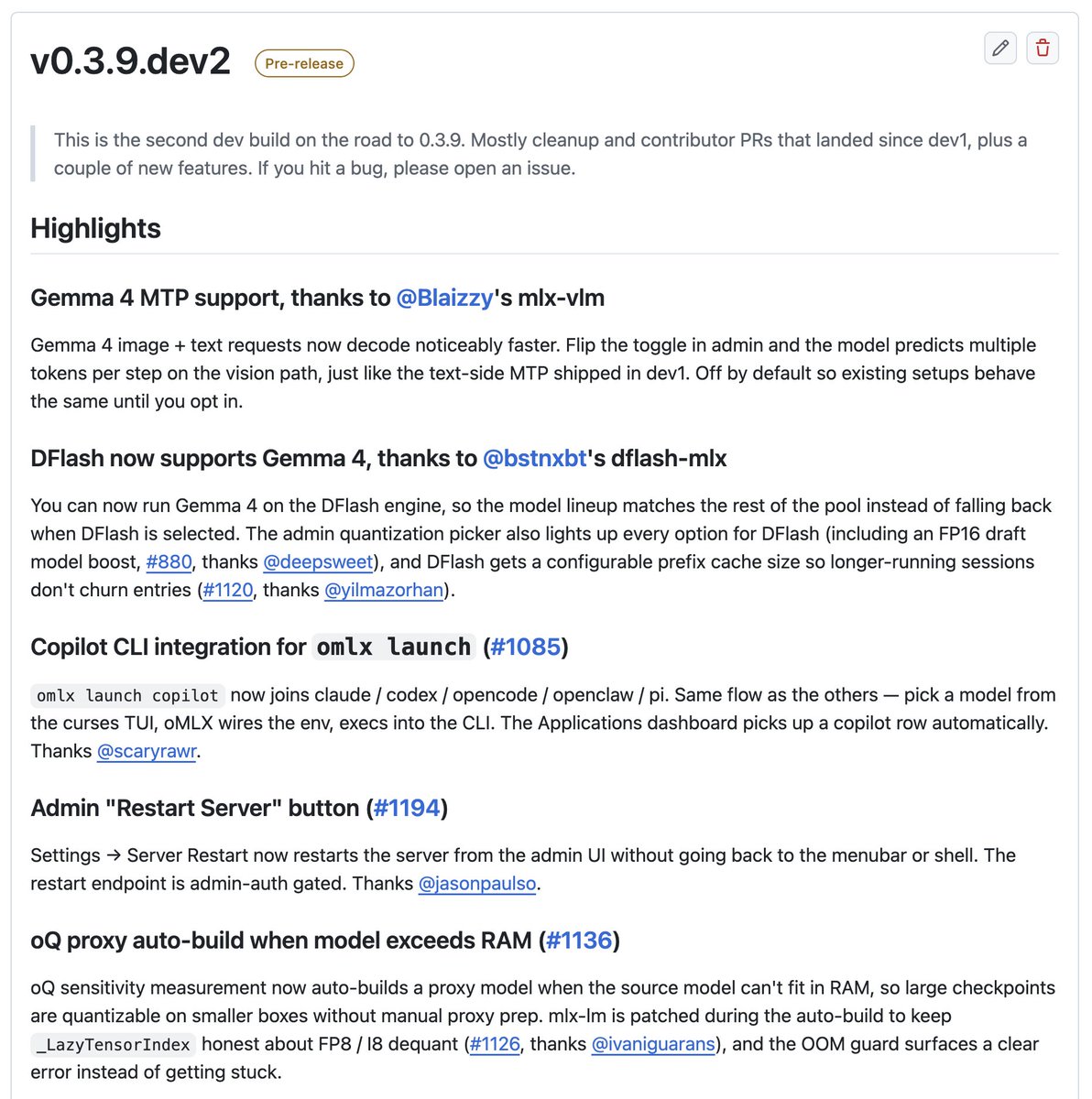


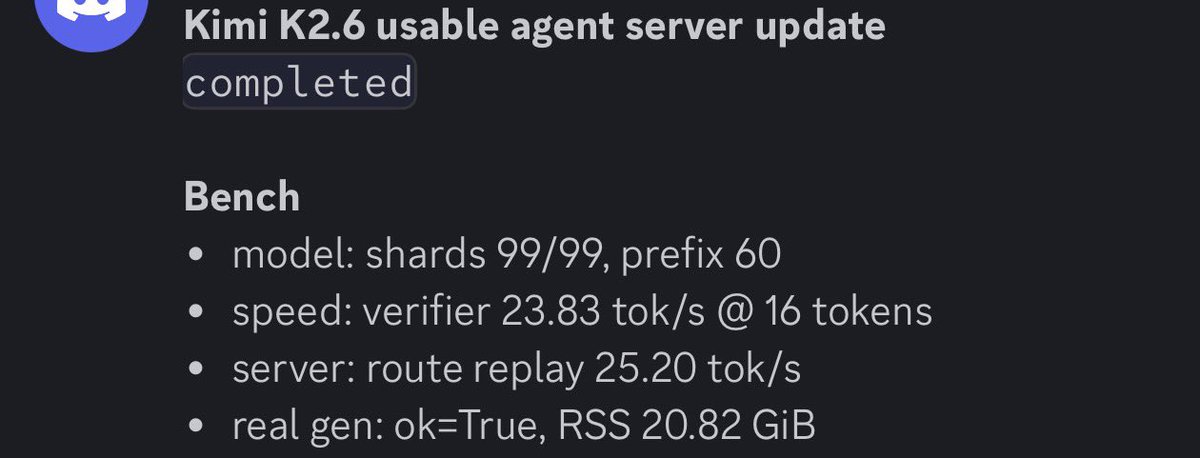


iOS 26.5 dropped today with a fix for CVE-2026-28994 — a Wi-Fi use-after-free our @defendtheworld discovered via automated Wi-Fi fuzzing. The bug is preauth and requires no user interaction.

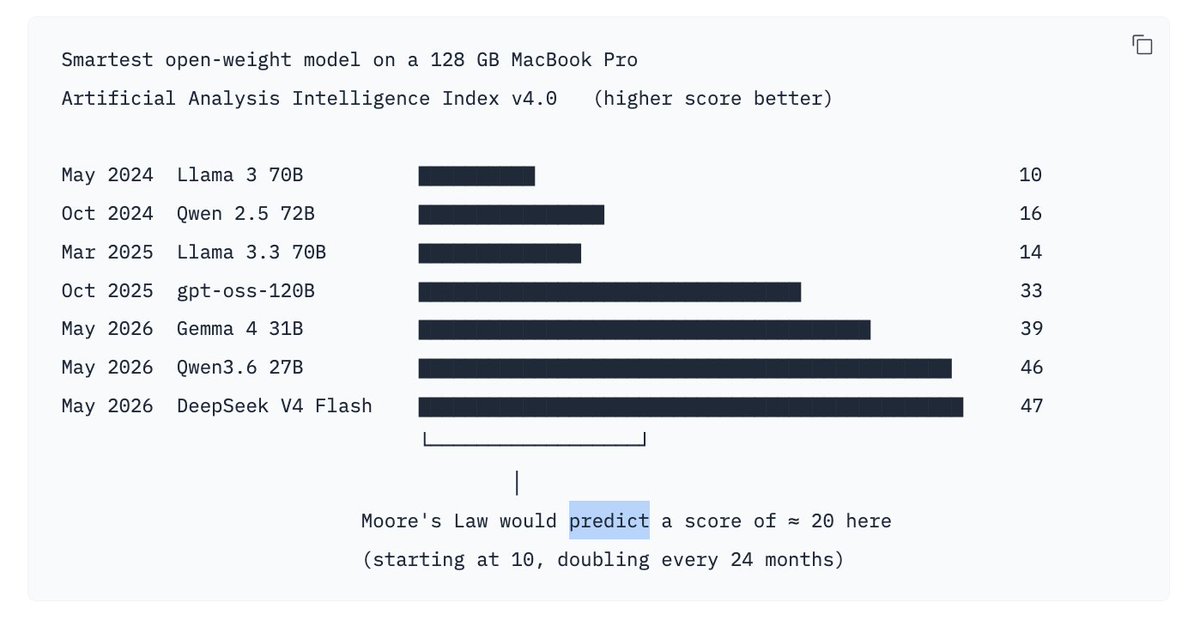





@AlexJonesax Try enabling Native MTP 💪






