
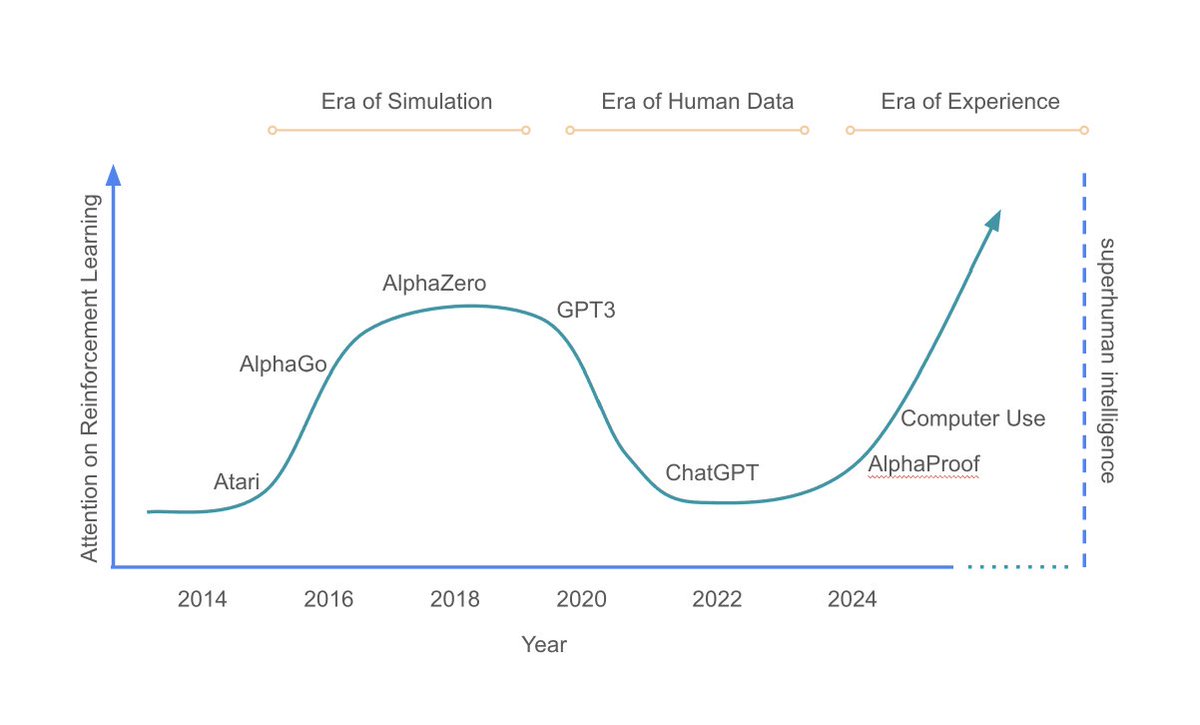
Era of Simulation
Era of Human data
Welcome to the Era of Experience - @David Silver , @RichardSSutton
#reinforcementlearning
#visionaries
#understandingAgenticAI
#reinforcementlearning
tinyurl.com/eraofexperienc…
English
va4az
141 posts












❤️🔥❤️🔥Excited to share our new paper ❤️🔥❤️🔥 **Why Has Predicting Downstream Capabilities of Frontier AI Models with Scale Remained Elusive?** w/ @haileysch__ @BrandoHablando @gabemukobi @varunrmadan @herbiebradley @ai_phd @BlancheMinerva @sanmikoyejo arxiv.org/abs/2406.04391 1/N









It was fast, Flash Attention v2 just landed on OpenAI Triton repo, less than 24h after the CUDA release. github.com/openai/triton/… github.com/openai/triton/…






