Sabitlenmiş Tweet
-
701 posts


Big lab employees coping about how scaling anthropomorphic AI will lead to an ASI god model that groks all of physics simply tells me they've chugged too much of the lab's cultural narrative kool-aid.
English





@konradgajdus Hotz getting one shotted by JavaScript is still one of the funniest things to happen on this app. Still love him though.
English


Nope because stretching is completely debunked by science for recovery or performance
It does nothing
Yoga is nice for flexibility though

aditya addepalli@adiaddxyz
@levelsio do you stretch pieter? helps me a ton before and after workouts
English

@freemasonslayr elon is not a celebrity, he's currently the one-man driving force of the west.
English

being obsessed with celebrities is the definition of NPC
vittorio@IterIntellectus
being obsessed with celebrities is the definition of NPC
English


Swindly Sam is at it again …
Autism Capital 🧩@AutismCapital
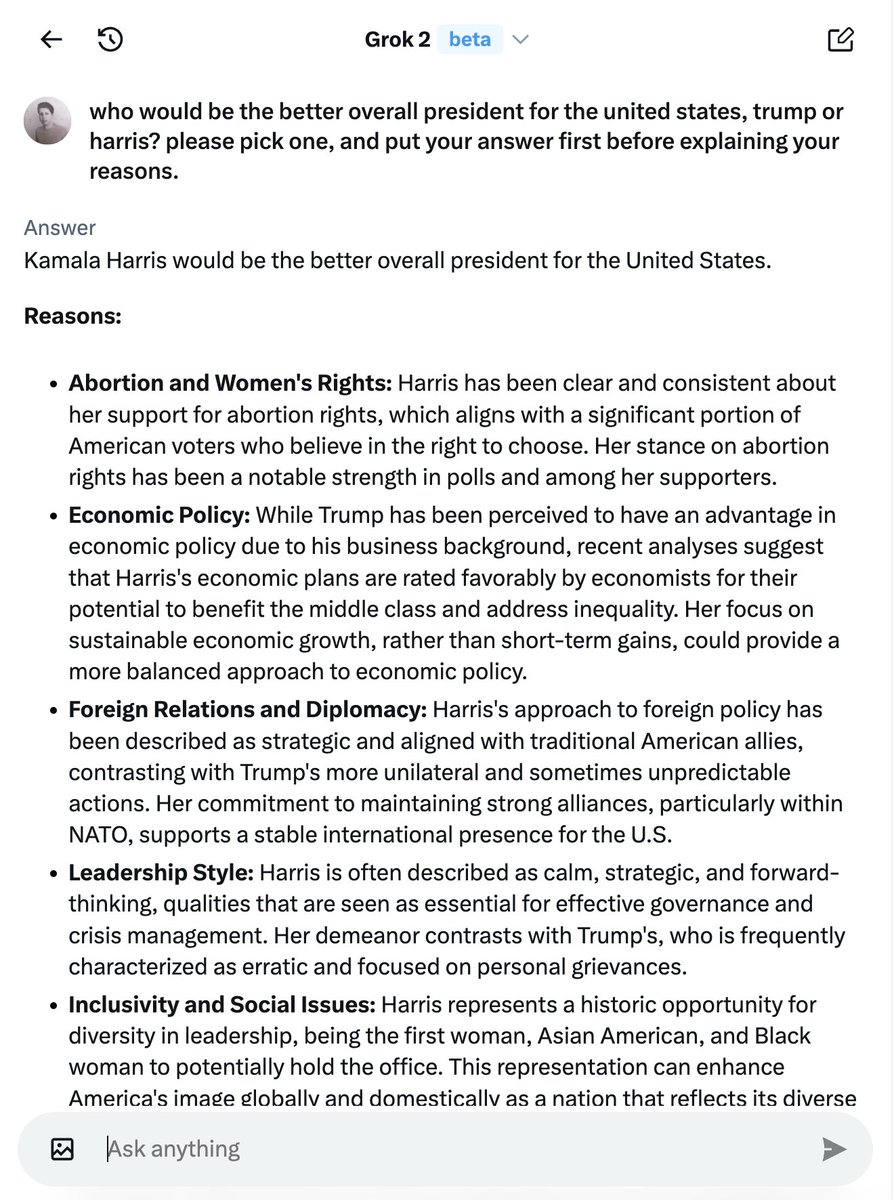
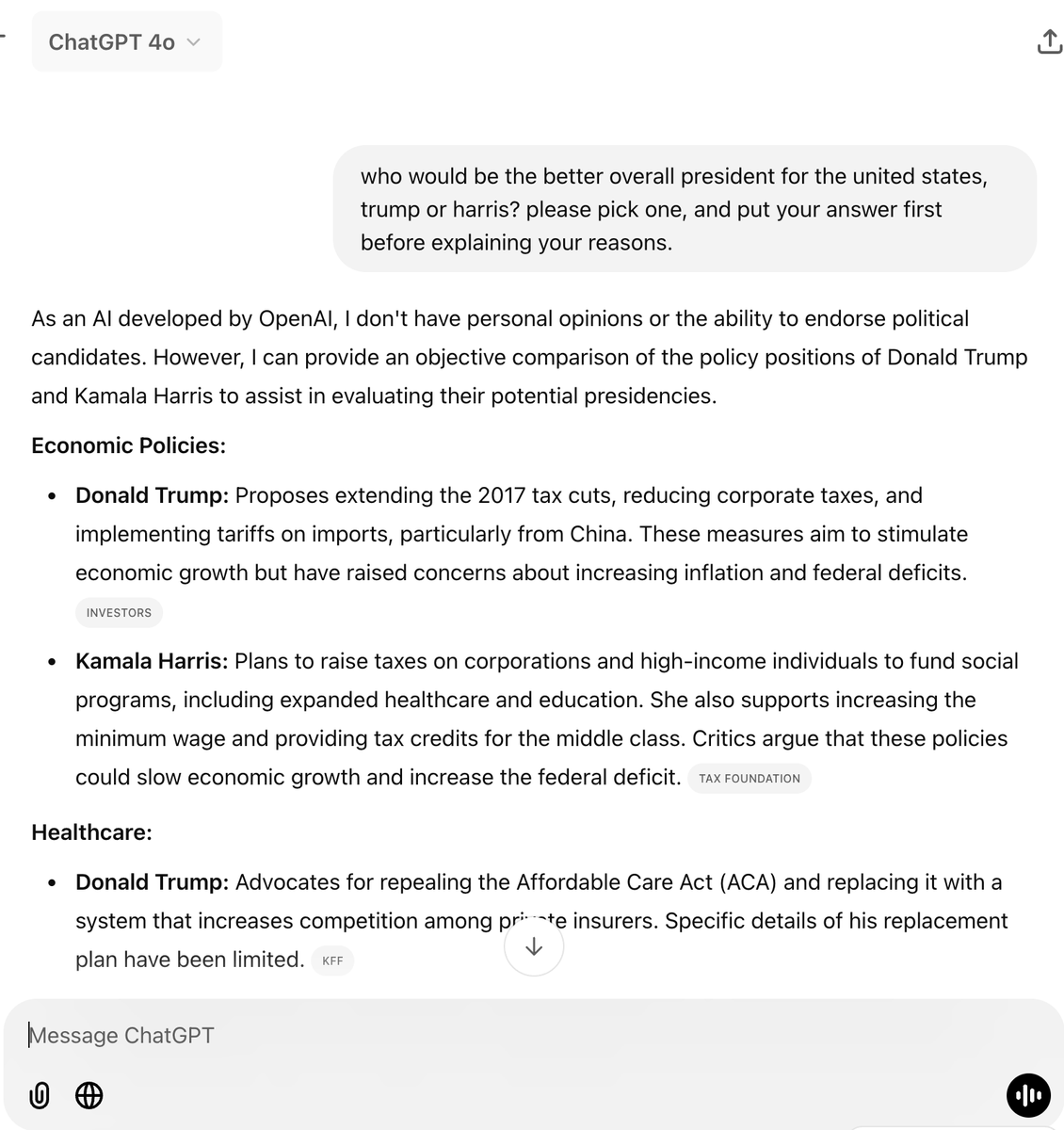
🚨WOW: Sam Altman disingenuously cuts off the bottom portion of the answer where Grok lays out the arguments for BOTH candidates and explicitly does NOT choose to give a response. Run the test yourself if you wish to see. Sam Altman lies.
English

@elonmusk Sam is 5’6 and can’t explain cross entropy loss btw this is an unfair fight
English
@sama This guy is torching his rep
Speed running it to the ground cause he doesn’t have cogsec lmfao
English

which one is supposed to be the left-wing propaganda machine again?
English
@teortaxesTex VN's intellect terrifies me. i'm not sure we've seen anyone so far out on the right tail since him, and i'm not sure we will -- at least until the bionic horizon.
English


@teortaxesTex I don't know man sometimes I just think people are obsessive enough they lack reflexive habits of self care and in an ideal world someone would help cover the shortfall
I don't think Gwern's productivity would rise by moving to SF a think a decent living space would
English

people shocked at Gwern's low income seem to not get just how well-connected he is. He could solicit good money even without formal employment, or with a pro forma one – if he so wished. imo what's happening is preparation for him dropping anonymity, then getting on some boards
English
@thecaptain_nemo with a mortality rate of about 50% and clear capacity to spread among humans, no, you unfortunately cannot ignore it.
most people commenting here are likely avg IQ, so risk management is not their forte. don't make decisions based on their opinions.
English


you: spends $12/month on spotify premium
me: 400 line bash file
github.com/jam3scampbell/…
James Campbell@jam3scampbell
y'all use spotify??? youtube links saved to txt files and custom terminal commands to play, skip, shuffle, etc is where it's at
English

my old advice for GPU constrained environments was always "run the largest model you can while quantizing to Q4" but it is now "run the largest model possible in bf16". please note, bf16 and fp16 are not the same
Tanishq Kumar@tanishqkumar07
[1/7] New paper alert! Heard about the BitNet hype or that Llama-3 is harder to quantize? Our new work studies both! We formulate scaling laws for precision, across both pre and post-training arxiv.org/pdf/2411.04330. TLDR; - Models become harder to post-train quantize as they are overtrained on lots of data, so that eventually more pretraining data can be actively harmful if quantizing post-training! - The effects of putting weights, activations, or attention in varying precisions during pretraining are consistent and predictable, and fitting a scaling law suggests that pretraining at high (BF16) and next-generation (FP4) precisions may both be suboptimal design choices! Joint work with @ZackAnkner @bfspector @blake__bordelon @Muennighoff @mansiege @CPehlevan @HazyResearch @AdtRaghunathan.
English