
🌐 Mr. WEB3
4.5K posts

🌐 Mr. WEB3
@web3ui
Your Digital Identity for Applications, Games, Metaverses, Wallets, and Websites. 🌐 To buy: 👉 https://t.co/Qo99Y1kVEW 👉 https://t.co/Xx9GpSmMMc
DLT | Blockchain Katılım Aralık 2021
73 Takip Edilen206 Takipçiler




Introducing 0GM-1.0-35B-A3B.
Our first proprietary AI model. Mixture of Experts (MoE), 35B parameters, 3B active per token.
Trained on our own decentralized GPU network. Open source under Apache 2.0.
English
@witcheer 💥Same issue over here, it's struggle for multi-agent tasks.
English

I ran Hermes agent (v0.13.0) with qwen3.6-35B-A3B on my RTX 4060 Ti 8GB for the first time today. full local agent stack.
my question was: can a local 3B-active MoE model actually drive an agent harness end-to-end?
quickly, my setup:
>WSL2 Ubuntu 26.04 → CUDA 13.2 → llama.cpp (b9049) → llama-server → Hermes Agent
>model: qwen3.6-35B-A3B-UD-Q4_K_M
>config: -ngl 999 -ncmoe 30 -c 32768 --cache-type-k q8_0 --cache-type-v q8_0
>baseline decode: 35.36 tok/s (from prior -ncmoe sweep)
I tested 4 rounds, easy to hard:
1. single tool call (list files) - pass, 31.4 tok/s
2. 5 chained tool calls (mkdir → venv → pip → write script → run) - pass, self-corrected a path error
3. read 10 files from windows via /mnt/c/ - pass when scoped, fail when hermes read full files
4. write a 95-line python CLI with argparse, then run it - pass, genuinely usable code
my biggest issue: the context.
hermes system prompt eats ~13.5K tokens. out of 32K, that leaves ~18.5K usable. a multi-step task fills that in 3-4 exchanges.
when I pushed it, hermes tried to compress via the same qwen model → slot contention → timeout → retry storm → ctrl+c.
and also, hermes has a 64K minimum context gate - needs a config override to run with 32K
my conclusion:
hermes + qwen3.6-35B-A3B is a capable local agent for short automated tasks, code gen, file ops, cron jobs. 4-5 tool calls per session, but not viable for long multi-turn sessions. context fills too fast, compression self-destructs, VRAM cliff halves speed before you hit the wall.
----
I am curious if anyone's running hermes agent with a local model on similar hardware (8-12 GB VRAM). what model are you pairing it with? how do you handle the context ceiling?
I am especially interested in setups that solve the compression-model problem (separate lightweight model for context compression).
witcheer ☯︎@witcheer
now testing real results with Hermes on WSL2
English

Two days ago, I asked whether I should buy a Mac Studio for local LLMs.
I was genuinely humbled by how much great feedback I received. The replies turned into a surprisingly useful buying guide: Mac Studio vs. MacBook Pro, NVIDIA GPUs, AMD options, memory size, bandwidth, M5 timing, and why smaller models can change the whole calculus.
This is useful information for anyone who wants to experiment with local LLMs. I turned the best takeaways into a short video using Codex, mainly with two tools: Chrome browser to capture and synthesize the comments, and Hyperframe for video creation.
English

tested out @antirez' ds4.c this morning. so impressive and delivers.
on a M3 max, 128GB, stock ds4 settings:
- 14–15 t/s at 62K pre-filled actual coding conversation
- memory usage was flat during gen ~85GB res
- disk cache is ~8GB for a full 100K context window
- thermals were normal, light fan activity
- inference server is rock solid so far
biggest constraint: anytime there's a compact, we pay the wait-time price of a fresh prefill (~1min per 10k context) before we are back in action.
sequential inference + multiple agents in parallel performance is unclear, will report back.
I'm so amped.
English
@Liftaris1 Can't wait to see more added avatars or we can generate one from my profile pic.. 🤣lolz 👍
English

Herm: All-in-one TUI built for Hermes. Chat with your agent and watch it manage everything it touches.
11 tabs. 42 themes.
My submission for the creative hackathon.
npm i -g herm-tui && herm
github.com/liftaris/herm
@NousResearch @Teknium @imbabybrooklyn
English

We've reached 1,000,000 domains under management!
To every domainer, builder, and registrant who trusted us with their portfolio — thank you.
Where we're going next 👇

English
English


@making_banq The Decentralized Website Address (Blockchained Record) is natively resolving in @brave browser, check this out. #Decentralize #DLT #Web3 #NFT #Domains #Crypto #Blockchain #Browser #UDFam
🌐 dweb.brave
GIF
English

🔥 Your domain = your brand. Your brand = your empire.
Stop sleeping on premium domains. The right name can change EVERYTHING for your business.
Selected domains. Serious moves. 💰
unstoppabledomains.com/s/any1.brave

English
@DomainDegen @JohanPoyhonen @domainsea Anyone knows when will the @unstoppableweb drop our domains .agi onchain for us ? It's close to the end of April 2026. #UDFam #Web3 #NFT #Domains
English


🌐 Mr. WEB3 retweetledi
🔥Premium domain for sale: AVATAR.MOI🔥
🔥Short. Memorable. Future-proof.
Perfect for #AI #Avatar, #DigitaliD #Identity, or #Metaverse projects. #AvatarArt #GamerLife #DN
💰Buy It Now: $1,300 | Lease to Own: $108/mo
DM me to make an offer! 👇
#DomainForSale #Web3
GIF
English

vibecoded a .agent seller frontstore:
ipfs.io/ipfs/QmUHUudrE…
English
@making_banq @LadyRocketSpace @sandy_carter @5quirks @unstoppableweb Fully functional Matrix, just added more functions to the player and the Matrix Reboot for Mr.WEB3 IPSF
#UDFam #IPFS #WEB3 #Domain #Tokenization
ipfs.io/ipfs/QmPFDKd4P…
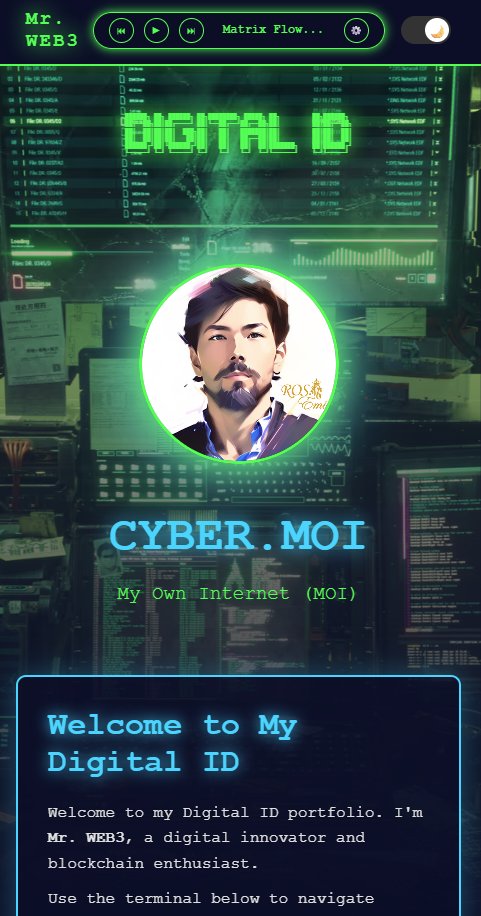
English
@LadyRocketSpace @sandy_carter @5quirks @unstoppableweb
Website incoming:
The Makingbank Kingdom
A COSMIC TERRITORY for .Mooncat and .Lunar Domains

English

altcoin.crypto is now live on the #ipfs. Built in 4 minutes with NO coding skills. Great job @5quirks and all the other devs involved in the project
ipfs.io/ipfs/QmdnmwCU1…
English
@5quirks @ntropiq 💥 Just updated the IPFS for Mr.WEB3 dweb, adding a ▶️ Music Player 🎶
🌐 ipfs.io/ipfs/QmQEsmxMo…
English

@web3ui @ntropiq the brave resolution is part of their integration, not sure if they have the feature turned on for that particular tld. Just checked out the IPFS for mr.web3 it looks awesome!
ipfs.io/ipfs/QmZCVGhmQ…
English

Our AI site builder now supports deploying sites to web3 domains via IPFS 💪
These resolve natively in Brave & Opera browsers.
Check out @5quirks site 👇
Brady@ntropiq
You all loved being able to generate websites with AI so much that we just made it a dedicated tab on our site Now our site builder is: - No longer limited to landers, with easy templates to start with - Interactive, so you can iterate on your designs - Embedded directly on our site, so you don't need to jump over to ChatGPT Check it out at the link below. All domainer club members get free AI credits to try it out. We're still in the early innings of our site builder - stay tuned as we roll out improvements soon unstoppabledomains.com/ai-site-builder
English

English


