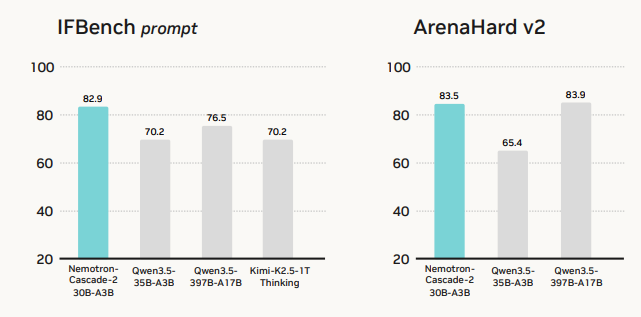
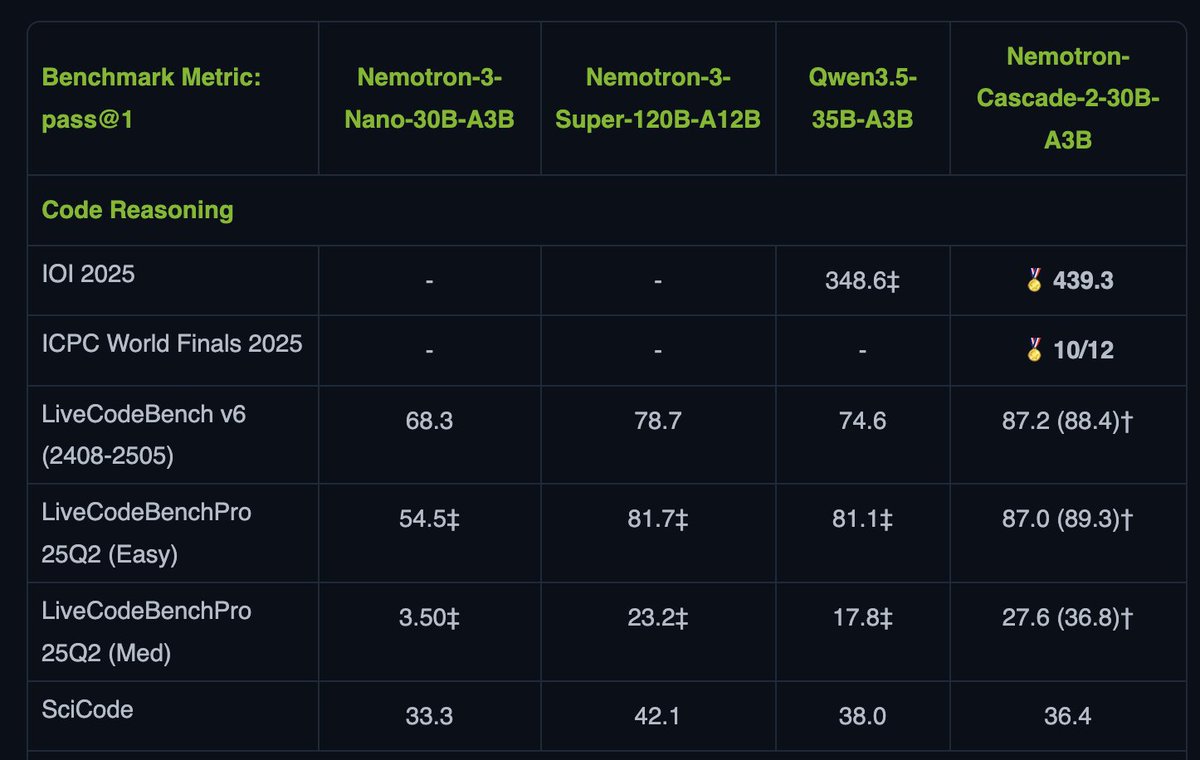
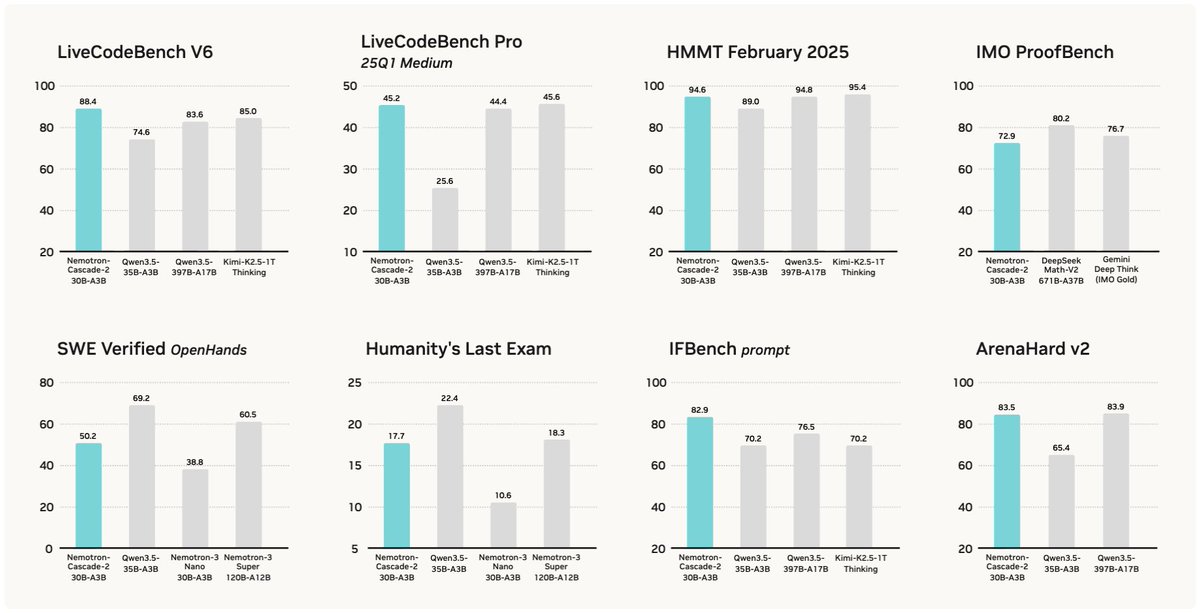
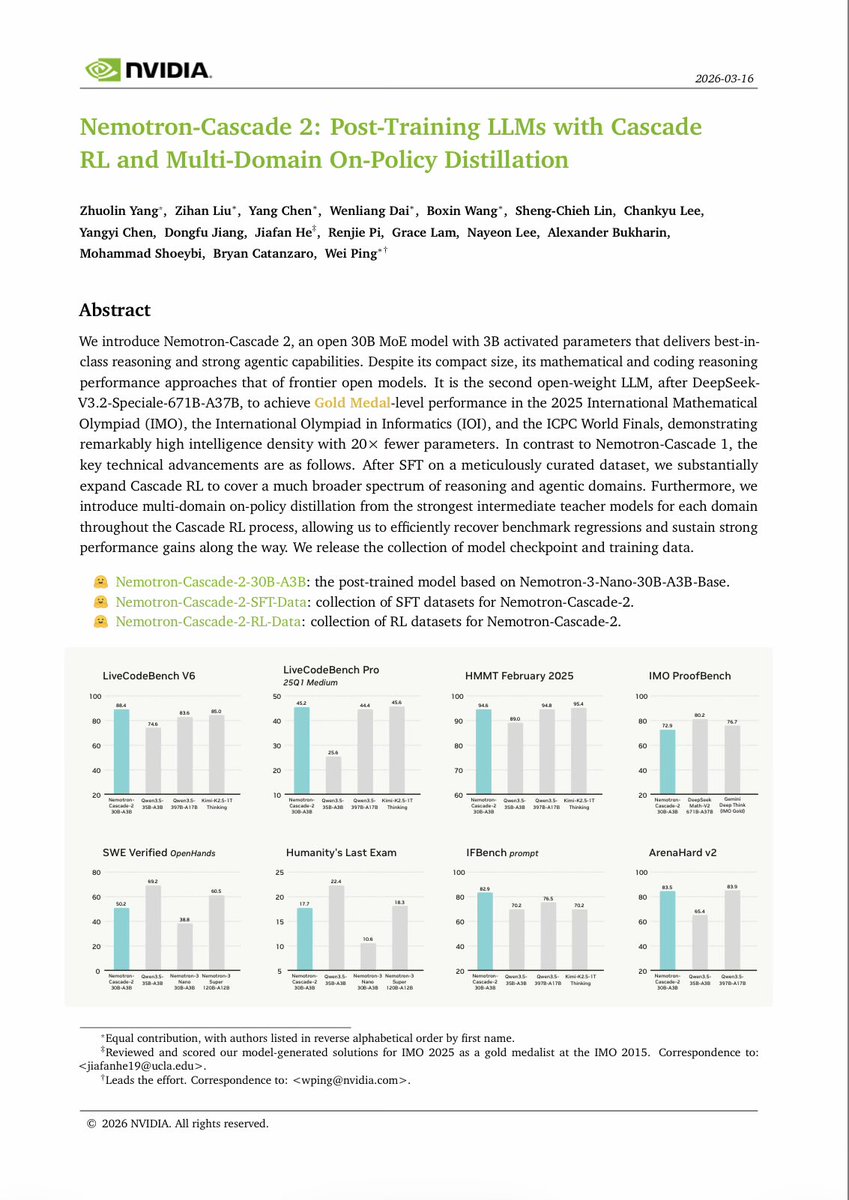
🚀 Introducing Nemotron-Cascade 2 🚀 Just 3 months after Nemotron-Cascade 1, we’re releasing Nemotron-Cascade 2: an open 30B MoE with 3B active parameters, delivering best-in-class reasoning and strong agentic capabilities. 🥇 Gold Medal-level performance on IMO 2025, IOI 2025, and ICPC World Finals 2025: • Capabilities once thought achievable only by frontier proprietary models (e.g. Gemini Deep Think) or frontier-scale open models (i.e. DeepSeek-V3.2-Speciale-671B-A37B). • Remarkably high intelligence density with 20× fewer parameters. 🏆 Best-in-class across math, code reasoning, alignment, and instruction following: • Outperforms the latest Qwen3.5-35B-A3B (2026-02-24) and even larger Qwen3.5-122B-A10B (2026-03-11). 🧠 Powered by Cascade RL + multi-domain on-policy distillation: • Significantly expand Cascade RL across a much broader range of reasoning and agentic domains than Nemotron-Cascade 1, while distilling from the strongest intermediate teacher models throughout training to recover regressions and sustain gains. 🤗 Model + SFT + RL data: 👉 huggingface.co/collections/nv… 📄 Technical report: 👉 research.nvidia.com/labs/nemotron/…