
yoovraj ゆび
2.9K posts
yoovraj ゆび
@yoovraj
Engineering Manager | Technologist | Application Engineer Love Electronics / Arduino / RPI / DIY robot cars / Edge AI
Japan Katılım Nisan 2009
987 Takip Edilen581 Takipçiler
Wow all of the sudden labor strike of ground staff at Mumbai Airport !!! My flight delayed by half an hr which is the minimum time. It may take long for negotiation!!! And looks like it is affecting all flights taking off from Mumbai AirPort ?
#cstmia
English
- old age elderly traveling with a stick. Wondering what kind of troubles she is going through because of such delay
- families with babies must also have a very tough time because of these delays
- people with schedule / meetings get affected
- people with emergency travel
English
It looks like luggage is still not loaded in flight as ground staff strike
English
@CSMIA_Official
Simple questions
- why a baby child care room present near a smoking room with such a narrow corridor. Passive smoking right from birth !!!
- surprised by seeing pigeons inside. They also feel the summer !!
- good integration with digiyatra! Keep it up
English
@dataforin I am also wondering the need to own a computer these days. In fact, most of the ipads or tablets can be used as quick laptops and if your work data is synced on cloud, and the reasonable speeds provided by mobile networks, you dont even need local storage.
English

While most Indian households now own a mobile phone, computer ownership in India has grown slowly. Over the last two decades, the share of households that own a computer has increased from just over 1% to just over 9%. In most developed countries, by contrast, computer ownership exceeds 75%.
Among the 30 million households in India that own a computer, 90% have a laptop, while 20% own a desktop. A little under 10% of computer-owning households report having both a laptop and a desktop.
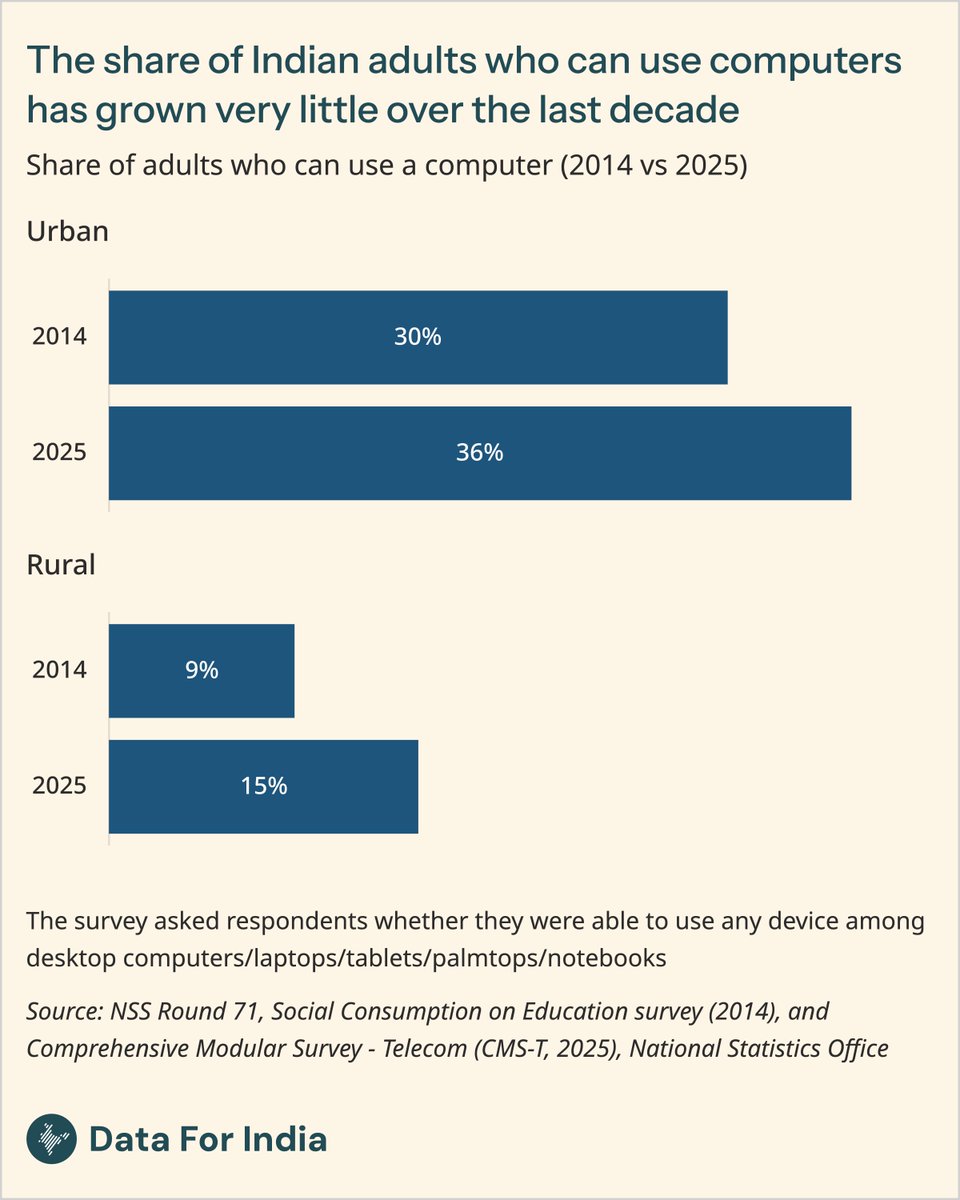
India has also made limited progress in the ability to use computers over the last decade. A little over one in five adults, or 200 million people, were able to operate a computer as of 2025. This share is roughly twice the share of households that own a computer, suggesting that many people may have learned to use a computer, or use one in college or at work, without owning one themselves.
While the proportion of rural adults who can use a computer has increased, it still stands at just about one in six. Among urban adults, the figure is much higher with over one in three adults, but it has grown only marginally over the last decade.
How does the ability to use computers vary by age group and gender in India? Read @akwaghmare’s piece to find out: dataforindia.com/computers/?utm…
#Computer #Technology #Laptop #India #DataForIndia
English
yoovraj ゆび retweetledi

Introducing Claude Managed Agents: everything you need to build and deploy agents at scale.
It pairs an agent harness tuned for performance with production infrastructure, so you can go from prototype to launch in days.
Now in public beta on the Claude Platform.
English
yoovraj ゆび retweetledi

Today, India takes a defining step in its civil nuclear journey, advancing the second stage of its nuclear programme.
The indigenously designed and built Prototype Fast Breeder Reactor at Kalpakkam has attained criticality.
This advanced reactor, capable of producing more fuel than it consumes, reflects the depth of our scientific capability and the strength of our engineering enterprise. It is a decisive step towards harnessing our vast thorium reserves in the third stage of the programme.
A proud moment for India. Congratulations to our scientists and engineers.
English
yoovraj ゆび retweetledi

LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English
yoovraj ゆび retweetledi
Software horror: litellm PyPI supply chain attack.
Simple `pip install litellm` was enough to exfiltrate SSH keys, AWS/GCP/Azure creds, Kubernetes configs, git credentials, env vars (all your API keys), shell history, crypto wallets, SSL private keys, CI/CD secrets, database passwords.
LiteLLM itself has 97 million downloads per month which is already terrible, but much worse, the contagion spreads to any project that depends on litellm. For example, if you did `pip install dspy` (which depended on litellm>=1.64.0), you'd also be pwnd. Same for any other large project that depended on litellm.
Afaict the poisoned version was up for only less than ~1 hour. The attack had a bug which led to its discovery - Callum McMahon was using an MCP plugin inside Cursor that pulled in litellm as a transitive dependency. When litellm 1.82.8 installed, their machine ran out of RAM and crashed. So if the attacker didn't vibe code this attack it could have been undetected for many days or weeks.
Supply chain attacks like this are basically the scariest thing imaginable in modern software. Every time you install any depedency you could be pulling in a poisoned package anywhere deep inside its entire depedency tree. This is especially risky with large projects that might have lots and lots of dependencies. The credentials that do get stolen in each attack can then be used to take over more accounts and compromise more packages.
Classical software engineering would have you believe that dependencies are good (we're building pyramids from bricks), but imo this has to be re-evaluated, and it's why I've been so growingly averse to them, preferring to use LLMs to "yoink" functionality when it's simple enough and possible.
Daniel Hnyk@hnykda
LiteLLM HAS BEEN COMPROMISED, DO NOT UPDATE. We just discovered that LiteLLM pypi release 1.82.8. It has been compromised, it contains litellm_init.pth with base64 encoded instructions to send all the credentials it can find to remote server + self-replicate. link below
English
I just registered to Invent the Future with Arduino UNO Q and App Lab. You should too! #hacksterio hackster.io/contests/inven…
English
yoovraj ゆび retweetledi

Wow this is crazy idea !!! A Social Network for AI Agents !!!
moltbook.com
molt.church
English
yoovraj ゆび retweetledi


yoovraj ゆび retweetledi


yoovraj ゆび retweetledi

Watch our CEO Jensen Huang outline the blueprint for America’s AI century in Washington, D.C. at NVIDIA GTC.
From national AI infrastructure and quantum computing to robotics and reindustrialization, see how NVIDIA and its partners are advancing America's AI leadership.
English
yoovraj ゆび retweetledi

Sakana AI’s CTO says he’s ‘absolutely sick’ of transformers, the tech that powers every major AI model
“You should only do the research that wouldn’t happen if you weren’t doing it.” (@thisismyhat) 🧠
@YesThisIsLion
venturebeat.com/ai/sakana-ais-…
English
yoovraj ゆび retweetledi

Today Meta announced #Monarch, a new framework for distributed programming that delivers scalability without sacrificing performance.
Monarch can be used to drive, or even debug, a large cluster in a notebook. It can also orchestrate large, fault tolerant model pre-training or highly asynchronous and heterogenous reinforcement learning jobs.
🔗 Read the blog from the PyTorch Team at Meta: hubs.la/Q03PC-LP0
Contributors include: @marius, @joespeez
#PyTorch #OpenSourceAI #PyTorchCon

English