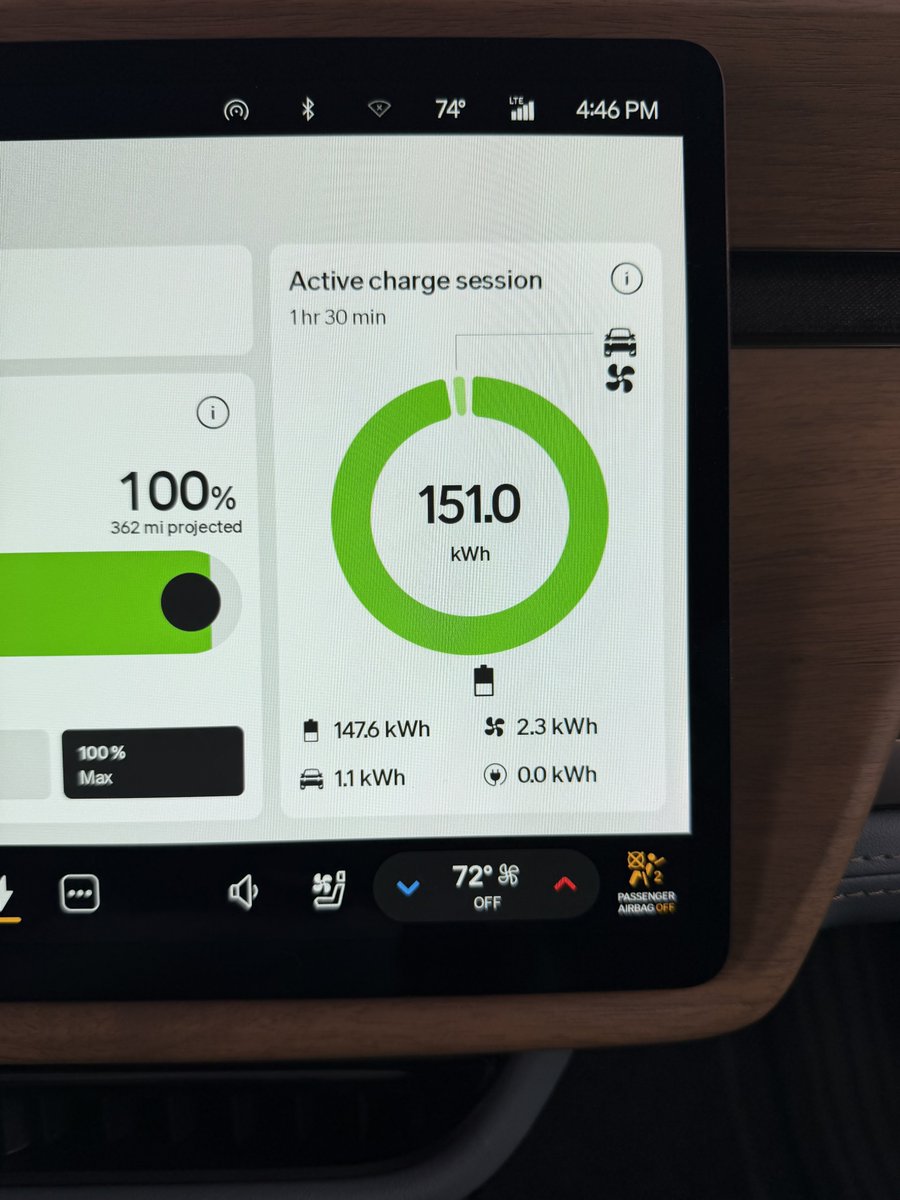
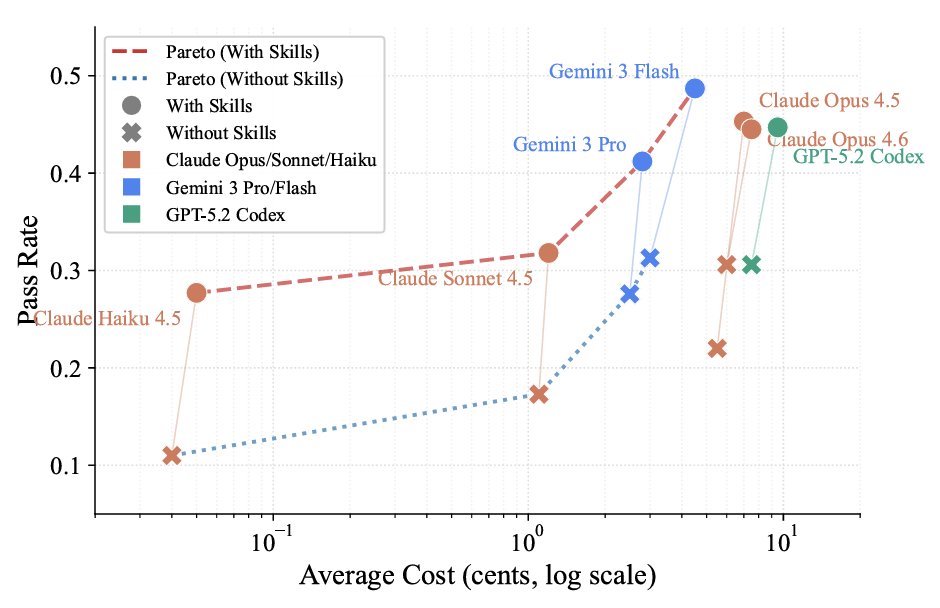
@HistoryGPT @emollick Gemini doesn’t even work as well as Claude models in Google’s own Antigravity IDE. Or didn’t a month ago when I last tried.
English
David
788 posts







Hi. Professional C/C++ programmer here. The open-source code I can find written by Adam Back and Satoshi Nakamoto don't look remotely similar. Back's code looks typical of academic Unix programmers who also hack their code to run on Windows. Satoshi code was written by a professional Windows programmer who also wrote for Unix. Stylistically, they look nothing alike. There's not enough time between 2005 when I can find the newest Adam Back and January 2009 when Satoshi published Bitcoin/0.1 to account for the change. Both are perfectly competent programmers, but stylistically, they are completely different. The NYTimes tried to compare their English language in posts/emails. I'm compare their C/C++ language in their open-source code. The NYTimes merely points out they both use C++ as if that's another corroborating detail, when the actual code seems to disqualify Adam Back.

Although I didn't find @JohnCarreyrou's Satoshi reveal to be compelling, I'm glad he wrote it, because it's one of my favorite topics to talk about, and it brings out OG crypto twitter, from when it was good.




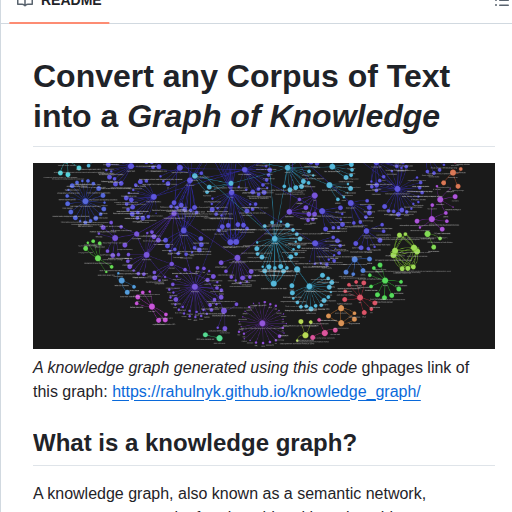
🚨 Andrej Karpathy thinks RAG is broken. He published the replacement 2 days ago. 5,000 stars in 48 hours. It's called LLM Wiki. A pattern where your AI doesn't retrieve information from scratch every time. It builds and maintains a persistent, compounding knowledge base. Automatically. RAG re-discovers knowledge on every question. LLM Wiki compiles it once and keeps it current. Here's the difference: RAG: You ask a question. AI searches your documents. Finds fragments. Pieces them together. Forgets everything. Starts over next time. LLM Wiki: You add a source. AI reads it, extracts key information, updates entity pages, revises topic summaries, flags contradictions, strengthens the synthesis. The knowledge compounds. Every source makes the wiki smarter. Permanently. Here's how it works: → Drop a source into your raw collection. Article, paper, transcript, notes. → AI reads it, writes a summary, updates the index → Updates every relevant entity and concept page across the wiki → One source can touch 10 to 15 wiki pages simultaneously → Cross-references are built automatically → Contradictions between sources get flagged → Ask questions against the wiki. Good answers get filed back as new pages. → Your explorations compound in the knowledge base. Nothing disappears into chat history. Here's the wildest part: Karpathy's use case examples: → Personal: track goals, health, psychology. File journal entries and articles. Build a structured picture of yourself over time. → Research: read papers for months. Build a comprehensive wiki with an evolving thesis. → Reading a book: build a fan wiki as you read. Characters, themes, plot threads. All cross-referenced. → Business: feed it Slack threads, meeting transcripts, customer calls. The wiki stays current because the AI does the maintenance nobody wants to do. Think of it like this: Obsidian is the IDE. The LLM is the programmer. The wiki is the codebase. You never write the wiki yourself. You source, explore, and ask questions. The AI does all the grunt work. NotebookLM, ChatGPT file uploads, and most RAG systems re-derive knowledge on every query. This compiles it once and builds on it forever. 5,000+ stars. 1,294 forks. Published by Andrej Karpathy. 2 days ago. 100% Open Source.






A big week ahead. It all starts Monday morning! #AppleLaunch




Why do people still buy new cars? That $50,000 car you just paid off cost you $63,000 in total payments. Plus, it is now only worth $20,000 so it's lost $43,000 in depreciation....in 5 years. Buy used. Come on people....stop throwing your money away.