For the past few weeks, I’ve been working on a solution based on Nvidia Spark (and other on-premises tech)
to save on cloud tokens without sacrificing quality whenever possible.
It’s a bit of a wild vibe-coding at this stage, but it seems like this is how every project starts these days. Such are the times…
Repost please if you’re interested in this solution. Feedback is appreciated!
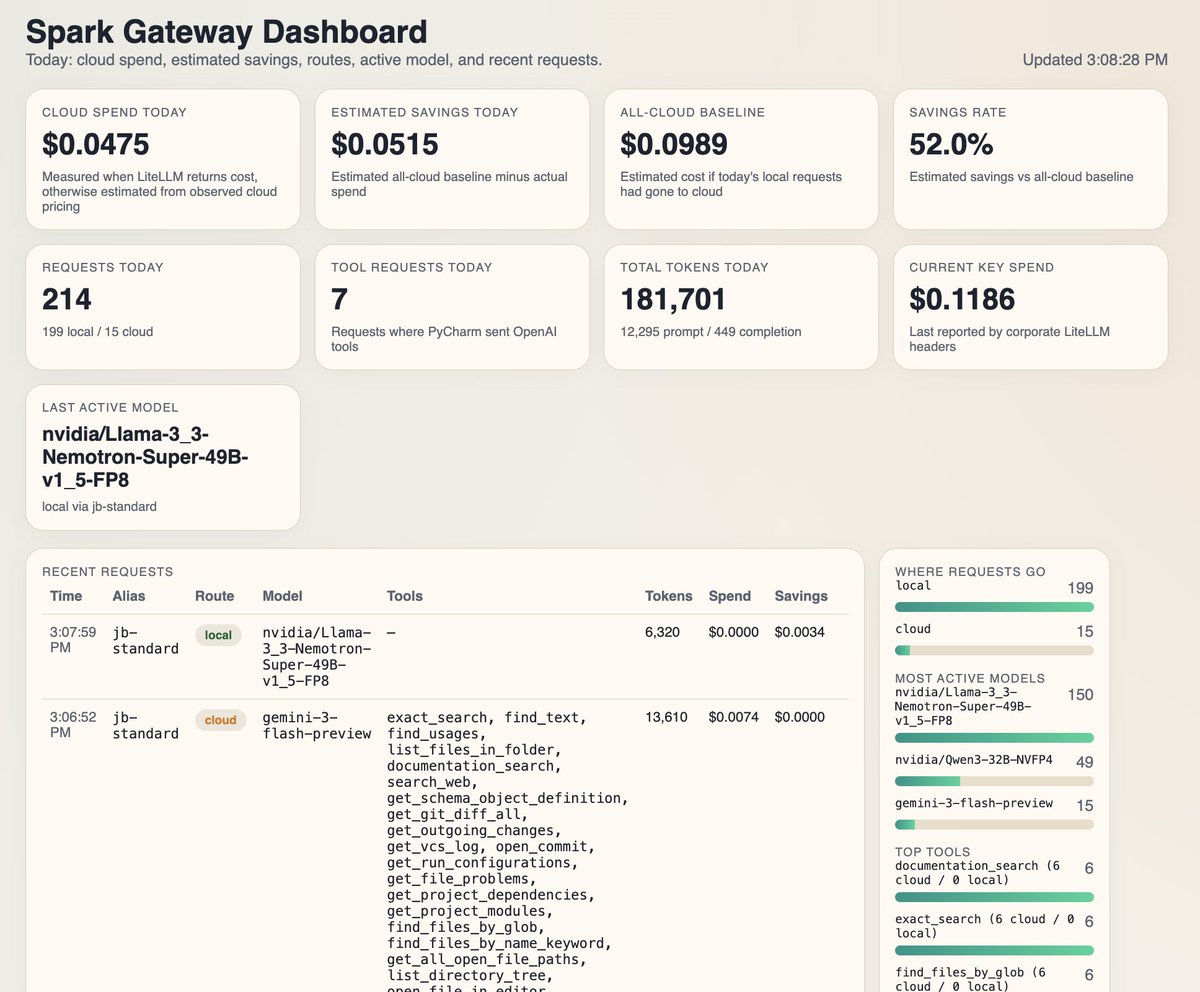
Solution uses several approaches simultaneously to get the most out of the local device. But at the same time, you don’t have to suffer through very long waiting times or stupid responses from LLMs.

English