
MD RIFAT
3.1K posts


The issue of sim-to-real transfer can be improved through better simulations, but it cannot be fixed because the solution requires not to leave reality at all.
Typically, most robotics workflows take the transition to reality as the end point of the process, while @PrismaXai flips it to the very beginning, where operators use actual robots in real-world environments, resulting in training data directly obtained from those exact physical circumstances.
This eliminates any issues with the transfer problem and the fidelity gap, offering data directly from the world in which the robot exists.
What is intriguing here is the cumulative nature of the process, as more and more operators join, generating data from various environments, expanding the dataset naturally without having to create diversity intentionally.
Nothing groundbreaking or innovative about the idea itself. The implementation is.

English

Now is the time to secure your spot in @Zerg_App.
If you wait - you’ll regret it later.
Don’t just watch - start creating content, engage with the community, and build your presence.
👉 Join Discord : discord.gg/zerg
👉 Start earning XP : welcome.zerg.app/referral/MQZDE…
Those who start today will lead tomorrow.
English

Optimum really nailed it.
“Redefining how data moves so major use cases can thrive.”
That line says a lot. Stablecoins. Tokenization. DeFi. All of it, powered by RLNC.
And no this isn’t just another L2 narrative. It feels different. This is the data layer finally catching up to what global scale actually demands.
Most chains are still stuck moving data the old way. It’s slow. Latency builds up. Things break under pressure.
Optimum flips that entirely with Random Linear Network Coding (RLNC).
Faster. Smarter. More resilient.
And the outcome? Blockchains that start to feel like the internet instant, seamless, global.
Think about what that unlocks:
• Stablecoins settling across borders in seconds
• Tokenized RWAs updating in real time
• DeFi systems that don’t fall apart when TVL hits billions
That’s what “global scale” is supposed to look like.
@get_optimum is quietly building the kind of infrastructure the space has been waiting on for a while now.
Who else is bullish on RLNC data acceleration?
@cryptooflashh
@shariaronchain

Imon@Imonbroz
Storing large files across a distributed network sounds easy at first. But it quickly gets complicated. Each node only has limited storage, and none of them know what the others are holding. That’s the core challenge this paper dives into how to distribute data efficiently so a downloader can recover the full file while connecting to as few storage locations as possible. There’s no coordination here. Every node acts on its own. That makes things harder, but also far more realistic for large scale systems. The authors look at three different approaches. The first is uncoded storage. It’s simple nodes just store random pieces of the file. Easy to set up, no complexity. But it doesn’t perform well. Too many overlaps happen, and important pieces go missing. So the downloader ends up connecting to more and more nodes just to fill the gaps. Then comes traditional erasure coding, like Reed Solomon. This improves things quite a bit. The file is encoded in a way that only a subset of pieces is needed to reconstruct everything. Much more efficient. Still, there’s a tradeoff. It requires a significant amount of extra storage at the central server before anything gets distributed, which adds overhead. The third approach is where things start to stand out random linear coding. Instead of storing actual chunks, nodes store random linear combinations of the data. It sounds abstract but the impact is clear. Almost any group of nodes will provide useful, independent information. Because of that, the downloader can rebuild the entire file with high probability after connecting to nearly the minimum number of nodes. No coordination needed. So what’s the takeaway? Uncoded storage is simple but inefficient. Erasure coding is effective but comes with a storage cost. Random linear coding sits right in the middle it delivers near optimal performance without needing extra centralized storage. In a way, it makes a completely uncoordinated system behave as if everything were perfectly organized. And that’s a pretty powerful idea for distributed storage and peer to peer networks. @get_optimum @cryptooflashh
English
@PawanKumar67103 @PrismaXai This hybrid teleop approach is brilliant!
English

We often 𝙞𝙢𝙖𝙜𝙞𝙣𝙚 𝙧𝙤𝙗𝙤𝙩𝙞𝙘𝙨 𝙖𝙨 𝙖 𝙛𝙪𝙩𝙪𝙧𝙚 where machines work completely on their own, but the reality today is far more nuanced. Most systems still operate in a space between manual control and full autonomy, where reliability matters more than hype. @PrismaXai builds in that space by combining human precision with machine execution, allowing robots to perform consistently while also generating valuable real-world data that helps models improve over time.
What makes this approach interesting is 𝙝𝙤𝙬 𝙞𝙩 𝙩𝙪𝙧𝙣𝙨 𝙝𝙪𝙢𝙖𝙣 𝙞𝙣𝙥𝙪𝙩 𝙞𝙣𝙩𝙤 𝙨𝙤𝙢𝙚𝙩𝙝𝙞𝙣𝙜 𝙨𝙩𝙧𝙪𝙘𝙩𝙪𝙧𝙚𝙙. Every action isn’t just task completion, it contributes to better training data, improved accuracy, and a clearer understanding of operator performance. Speed, consistency, and precision start to matter, and over time this creates a system where skill is measurable rather than random.
Instead of relying purely on automation, this kind of setup makes robotics more usable today while still moving toward autonomy. It also solves a key challenge scaling. Coordinating operators, maintaining quality, and building trust becomes easier when the system is designed around performance and feedback rather than manual control.
• 𝐍𝐨𝐭 𝐟𝐮𝐥𝐥𝐲 𝐚𝐮𝐭𝐨𝐧𝐨𝐦𝐨𝐮𝐬 𝐲𝐞𝐭 → robotics still needs human support for real-world reliability
• 𝐇𝐮𝐦𝐚𝐧 + 𝐦𝐚𝐜𝐡𝐢𝐧𝐞 𝐚𝐩𝐩𝐫𝐨𝐚𝐜𝐡 → teleoperation ensures precision while AI continues to improve
• 𝐃𝐚𝐭𝐚 𝐚𝐝𝐯𝐚𝐧𝐭𝐚𝐠𝐞 → every human action becomes high-quality training data
• 𝐏𝐞𝐫𝐟𝐨𝐫𝐦𝐚𝐧𝐜𝐞 𝐦𝐚𝐭𝐭𝐞𝐫𝐬 → operators are judged by speed, accuracy, and consistency
• 𝐒𝐜𝐚𝐥𝐚𝐛𝐥𝐞 𝐬𝐲𝐬𝐭𝐞𝐦 → structured network replaces random/manual coordination
• 𝐋𝐨𝐧𝐠-𝐭𝐞𝐫𝐦 𝐯𝐢𝐬𝐢𝐨𝐧 → building the bridge toward true autonomy, not skipping steps
In the long run, this shifts the focus from just building smarter robots to building better systems around them where humans and machines work together, and each interaction makes the overall network stronger.

English

Day 4/5 Of Explaining The Vision Of @twin3_ai With A Hand-Drawn Art
In this art I have explained the Soul Injection. Soul Injection is the bridge between a static digital twin and an active, autonomous agent. It is the process of pouring your unique Soul Signal, your core values, ethics, and decision making patterns into the 256D Twin Matrix.
Your specific vibes and qualitative nuances are distilled into the system. The SBT acts as the filter, ensuring only your verified essence can power the twin.A machine without a soul is just a tool. An agent with a soul is an extension of self. In a world of a billion autonomous agents, the ones that carry an authentic human signal are the ones that will build trust, settle value, and navigate the decentralized economy effectively.
The machine provides the scale and the soul provides the direction.

Satoshi The 2'nd@satoshithe2nd_
Day 3/5 Of Explaining The Vision Of @twin3_ai With A Hand-Drawn Art🩶 Your digital twin cannot just exist, it must understand. It needs a framework to translate your human intuition, values, and knowledge into a language the machine can navigate. Let me introduce you to the 256 Dimensions Twin Matrix. In the realm of AI, data is coordinate in high dimensional space. The Blueprint is the architectural layer where your essence is categorized and weighted. Your digital self lives in high dimensional embeddings. To capture the nuance of a human personality, we need more than just likes and dislikes. We need a spectrum that captures the subtle gradients of how you think, work, and create. Every preference, skill, and memory is assigned a dimension. This ensures your AI agent doesn't just mimic you it aligns with you.
English

Why the Current Token Launch Model
is Broken and How ZERG Fixes It
Most token launches today favor the fastest bots or the deepest pockets. At ZERG, we believe the redistribution of success should be as transparent as the blockchain itself.
Enter the Token Box Offering (TBO).
How it works:Instead of a standard sale, assets are distributed via tiered loot boxes. Whether you snag a Common or a Legendary box, you are receiving a specific percentage of the supply.
The ZERG Difference:
Timing doesn't dictate destiny: The distribution is generated at creation. The last box sold has the same mathematical potential as the first.
Deterministic Logic:
Our box outcomes aren't guessed they are
hard-coded and verifiable.
Provably Fair:
We’ve removed the "black box" of tokenomics and replaced it with a literal (and fair) loot box.
Success should be shared, not just snatched. Join the ZERG evolution.
@Zerg_App
Aysho 🟧 (✸,✸) π²@aysho_M
3 Types of Extraction Mechanisms Explained Simply In the evolving world of Web3, understanding how value is extracted is key 👇 Bundling Transactions are grouped together for efficiency but control over ordering can create hidden advantages. PVP / VAMPS It’s a competitive battlefield where participants extract value directly from each other. Dev Extraction Developers design systems where they capture value through fees, tokenomics, or protocol mechanics. The game isn’t just about participation anymore. It’s about understanding where the value flows and who captures it. Stay sharp, Stay informed. @Zerg_App
English

𝐎𝐫𝐚𝐜𝐥𝐞𝐬 𝐖𝐞𝐫𝐞 𝐒𝐭𝐞𝐩 𝐎𝐧𝐞 - 𝐑𝐢𝐚𝐥𝐨 𝐈𝐬 𝐅𝐢𝐱𝐢𝐧𝐠 𝐖𝐡𝐚𝐭 𝐂𝐨𝐦𝐞𝐬 𝐍𝐞𝐱𝐭
@RialoHQ
grialo everyone
At first, I thought oracles solved everything. They bring real-world data into smart contracts, so the system should work perfectly.
But there’s a gap most people don’t notice.
Oracles send data, but they don’t always check if that data is actually true. The smart contract receives it, trusts it, and executes without any verification.
That’s where things can go wrong.
If the input is incorrect, the outcome will also be incorrect. And since smart contracts don’t question data, even a small error can trigger a completely wrong action.
This creates a hidden risk in the system.
• Data is trusted without verification
• Wrong inputs can lead to wrong execution
• No built-in layer to confirm truth
• The system depends on blind trust
That’s the limitation.
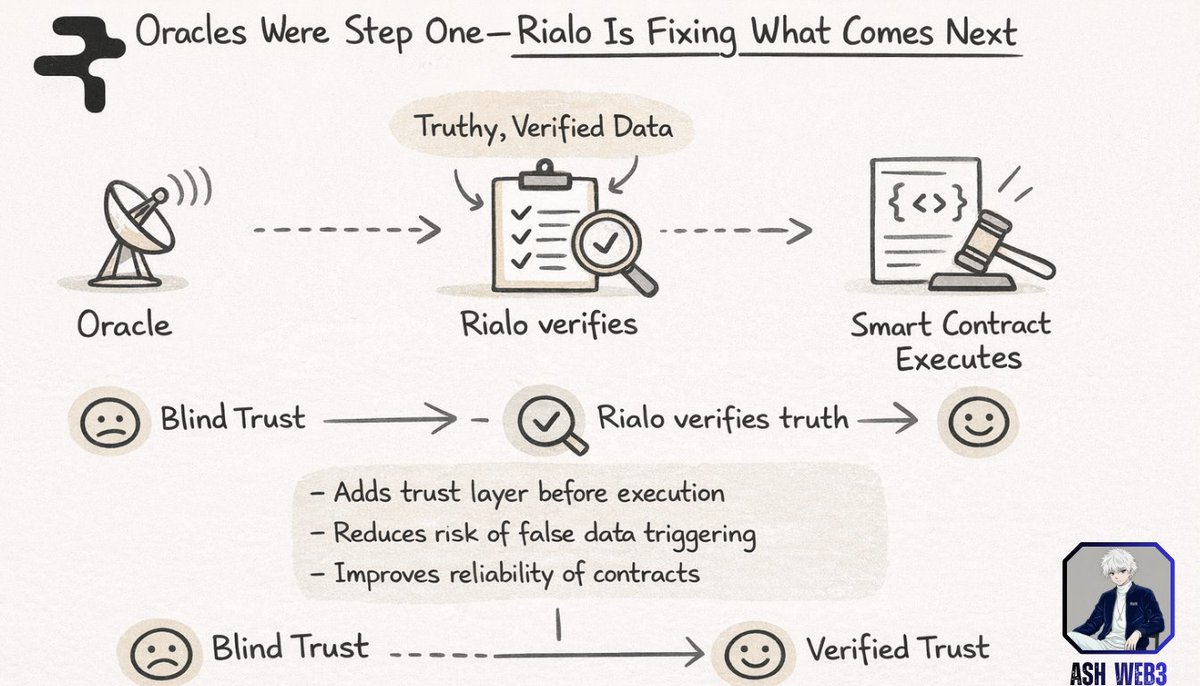
Now this is where Rialo changes the model.
Instead of just passing data forward, Rialo adds a verification step before execution. It checks whether the event or data is actually true before allowing the smart contract to run.
So the flow becomes simple but much stronger.
Oracles bring the data → Rialo verifies the truth → then execution happens
This small change makes a big difference.
• Adds a trust layer before execution
• Reduces risk of false data triggering actions
• Improves reliability of smart contracts
• Moves the system from blind trust to verified trust
This is not just an improvement, it’s a necessary evolution.Because bringing data on-chain was never the final solution. Making sure that data is correct is what really matters.
Rialo is focusing on that missing piece and that’s where things start to get more secure and more reliable.
English

@DonutAI
Everything you need to know about today’s D0 Workshop + AMA:
The first-ever D0 Workshop & AMA is happening today’s ! 🍩
If you want the inside scoop on Donut and some sweet rewards, you can't miss this.
What’s in store:
✨ How to master D0
1️⃣The Goal: Learn how to use D0 & give your feedback.
2️⃣ The Perks: We’re giving away D0 codes all session long.
3️⃣ The Alpha: Get news you won't find
🙋 Direct Q&A with the team
📅 Friday, April 17th
🕐 1:00 AM PST | 4:00 PM UTC+8
Set your alarms. The team is ready for your questions! 🍩
Don't be late. See you there! 🍩🚀
@GigiWillliams
#DonutAI #D0 #Web3 #AMA

English

𝐂𝐨𝐧𝐭𝐞𝐧𝐭 𝐂𝐥𝐢𝐧𝐢𝐜 𝐅𝐫𝐢𝐝𝐚𝐲
Today at 7:30 PM, the @PrismaXai team is reviewing selected content and sharing actionable feedback to help you improve
If you’re building, writing, or experimenting this is where your content gets sharper
Join in :
discord.gg/prismaxai
English

I’ve been noticing something off with all this AI agent hype going into 2026.
Most people I talk to are excited about agents doing everything, but nobody really explains how they actually trust each other or make decisions when things get messy.
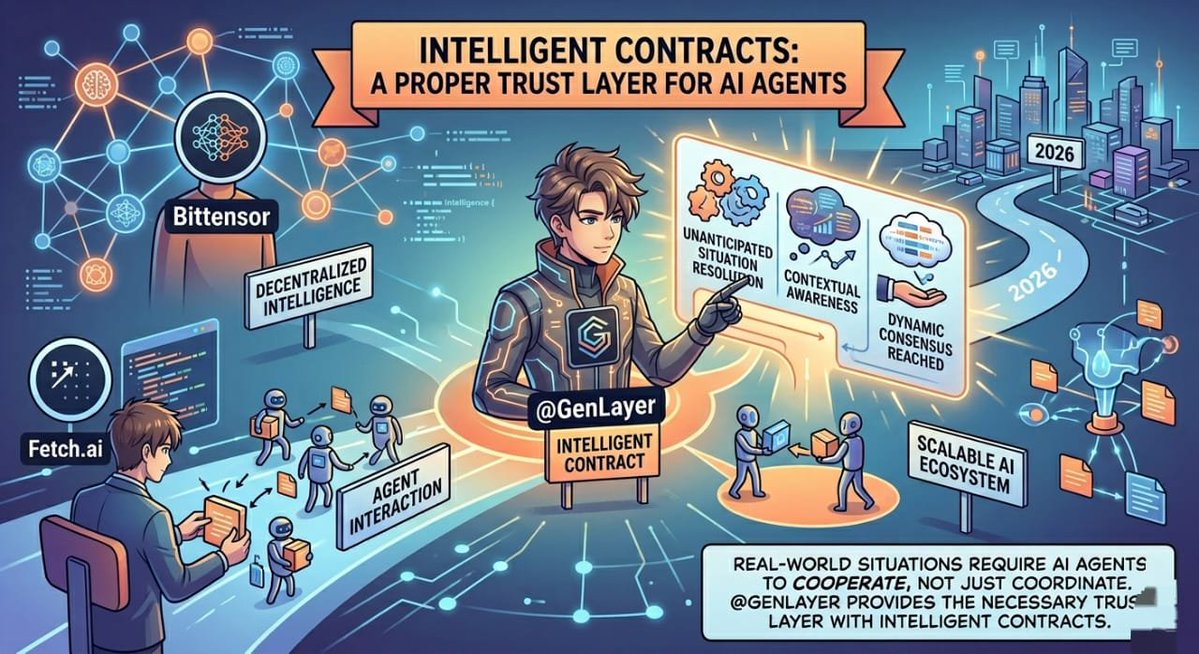
So my top 3 AI crypto picks right now are Bittensor, Fetch.ai, and @GenLayer.
I’ve looked into Bittensor and Fetch.ai for a bit. Bittensor is solid for decentralized intelligence, and Fetch.ai is pushing agent-to-agent interaction. But both still feel like they stop at coordination.
GenLayer is the only one that made me pause a bit.
The idea of Intelligent Contracts just makes more sense in real situations. Instead of just running fixed code, it can deal with uncertainty, check context, and still reach a decision.
That part feels important because real-world use isn’t always clean or predictable.
If AI agents are actually going to transact and work together at scale, there has to be a proper trust layer behind them, not just code that breaks when something unexpected happens.
That’s why it's my top pick for 2026.
English
@marurlemo @blockchainjeff @MurielMedard @kentlinyy @EliLaipson This RLNC upgrade could really scale DeFi to the moon!
English

Day 87
Decentralize to Scale
𝗪𝗵𝘆 𝗦𝘁𝗮𝗯𝗹𝗲𝗰𝗼𝗶𝗻𝘀, 𝗧𝗼𝗸𝗲𝗻𝗶𝘇𝗮𝘁𝗶𝗼𝗻 & 𝗗𝗲𝗙𝗶 𝗡𝗲𝗲𝗱 𝗮 𝗡𝗲𝘄 𝗡𝗲𝘁𝘄𝗼𝗿𝗸 𝗟𝗮𝘆𝗲𝗿
In blockchain, a layer simply means a level of responsibility in the system. And each layer does a specific job.
Stablecoins, Tokenization, and DeFi need a new network layer because these systems rely on constant data movement: prices updating, transactions propagating, and states syncing across nodes. But traditional networking (routing) struggles here. As activity grows, delays increase, bandwidth is wasted, and performance drops.
Optimum changes this at the network level with a new layer. It’s not another blockchain or app layer. It’s a network layer upgrade, the part that moves data between nodes.
𝐖𝐡𝐚𝐭 𝐢𝐬 𝐎𝐩𝐭𝐢𝐦𝐮𝐦 𝐛𝐮𝐢𝐥𝐝𝐢𝐧𝐠
Optimum @get_optimum is building a high-performance decentralized networking layer for Web3, powered by 𝐑𝐚𝐧𝐝𝐨𝐦 𝐋𝐢𝐧𝐞𝐚𝐫 𝐍𝐞𝐭𝐰𝐨𝐫𝐤 𝐂𝐨𝐝𝐢𝐧𝐠 (𝐑𝐋𝐍𝐂), to move data faster and more efficiently across blockchains.
With RLNC, data is encoded into flexible packets that can be reconstructed even if some are lost. This removes the need for constant retransmissions and keeps data flowing smoothly even under heavy load.
For example: In DeFi trading, instead of waiting for missing data before execution, nodes can reconstruct it instantly from coded packets, reducing latency and missed opportunities.
This means faster stablecoin transfers, more reliable tokenized assets and smoother DeFi execution
For Ethereum, this is critical: higher throughput without sacrificing decentralization, lower latency during peak demand and better scalability for global financial systems.
Optimum isn’t just improving blockchains. It’s upgrading the data layer powering the future of finance.
𝐋𝐞𝐚𝐫𝐧 𝐦𝐨𝐫𝐞 𝐚𝐛𝐨𝐮𝐭 𝐎𝐩𝐭𝐢𝐦𝐮𝐦:
➔ Follow X @get_optimum
➔ Join Discord discord.gg/getoptimum
➔ Check Docs docs.getoptimum.xyz
• I am a volunteer contributor to Optimum

BlockWeb@marurlemo
Day 86 Decentralize to Scale 𝗖𝗼𝗱𝗶𝗻𝗴 𝘃𝘀 𝗥𝗼𝘂𝘁𝗶𝗻𝗴: 𝗧𝗵𝗲 𝗜𝗻𝘁𝗲𝗿𝗻𝗲𝘁 𝗨𝗽𝗴𝗿𝗮𝗱𝗲 𝗠𝗼𝘀𝘁 𝗣𝗲𝗼𝗽𝗹𝗲 𝗡𝗲𝘃𝗲𝗿 𝗡𝗼𝘁𝗶𝗰𝗲𝗱 Optimum @get_optimum is building a high-performance decentralized networking layer for Web3 designed to make data flow faster and more efficiently across blockchains like Ethereum. For decades, the internet has relied on routing, sending packets from one point to another, step by step. If a packet is lost, it must be resent. Simple but inefficient at scale. Now imagine coding instead of routing. With 𝐑𝐚𝐧𝐝𝐨𝐦 𝐋𝐢𝐧𝐞𝐚𝐫 𝐍𝐞𝐭𝐰𝐨𝐫𝐤 𝐂𝐨𝐝𝐢𝐧𝐠 (𝐑𝐋𝐍𝐂), data isn’t sent as fixed packets. Instead, nodes combine or code data into new packets before forwarding them. Each packet carries partial information about the whole dataset. This means even if some packets are lost, the receiver can still recover the original data. No need for exact retransmissions. Example: Instead of waiting for one missing file chunk, you receive multiple coded pieces that can rebuild it anyway. This shift from routing to coding reduces delays, saves bandwidth, and improves reliability especially in large, dynamic networks. For Ethereum, this is a game changer. ♾️ Faster block propagation ♾️ Lower latency under congestion ♾️ Higher throughput without centralization Optimum doesn’t just move data, it upgrades how data moves. 𝐋𝐞𝐚𝐫𝐧 𝐦𝐨𝐫𝐞 𝐚𝐛𝐨𝐮𝐭 𝐎𝐩𝐭𝐢𝐦𝐮𝐦: ➔ Follow X @get_optimum ➔ Join Discord discord.gg/getoptimum ➔ Check Docs docs.getoptimum.xyz • I am a volunteer contributor to Optimum
English

Just started looking into @ritualnet and it’s actually interesting
The idea of combining AI inference with on-chain verification feels like a different direction from most projects
Still learning,but I can see why people are paying attention
Anyone here already building on it?

English
English



5,000 Members on @DlicomApp Discord!
From a small community to a fast growing movement 💙
And this is just the beginning…
If you’re already here. you’re early 👀
If not… you’re starting to get late.
More updates. More rewards. More growth ahead
Let’s building together 🚀



English
@0xwillow_g @ritualnet @0xMadScientist @Jez_Cryptoz @joshsimenhoff @dunken9718 @cryptooflashh @Ritual_IN Amazing GGG
English



you know you've been ritual for too long when you can recognise what this is!!!!!!!

moctx (❖,❖)@moc_tx89
what do these 2 colors remind you of?
English

A Small Win A Big Meaning @PrismaXai Journey
Success isn’t always loud
sometimes it shows up quietly as growth recognition and trust. Receiving this new role in PrismaX means a lot more than a badge it represents consistency learning and genuine contribution over time.
I’m truly grateful to this amazing community for the support encouragement and belief. Without you all this milestone wouldn’t feel this special.
I got Navigational. This role is not the end it’s a new responsibility to contribute more help others and keep building forward.
specifically thanks to @vivianrobotics
@shayebackus
English
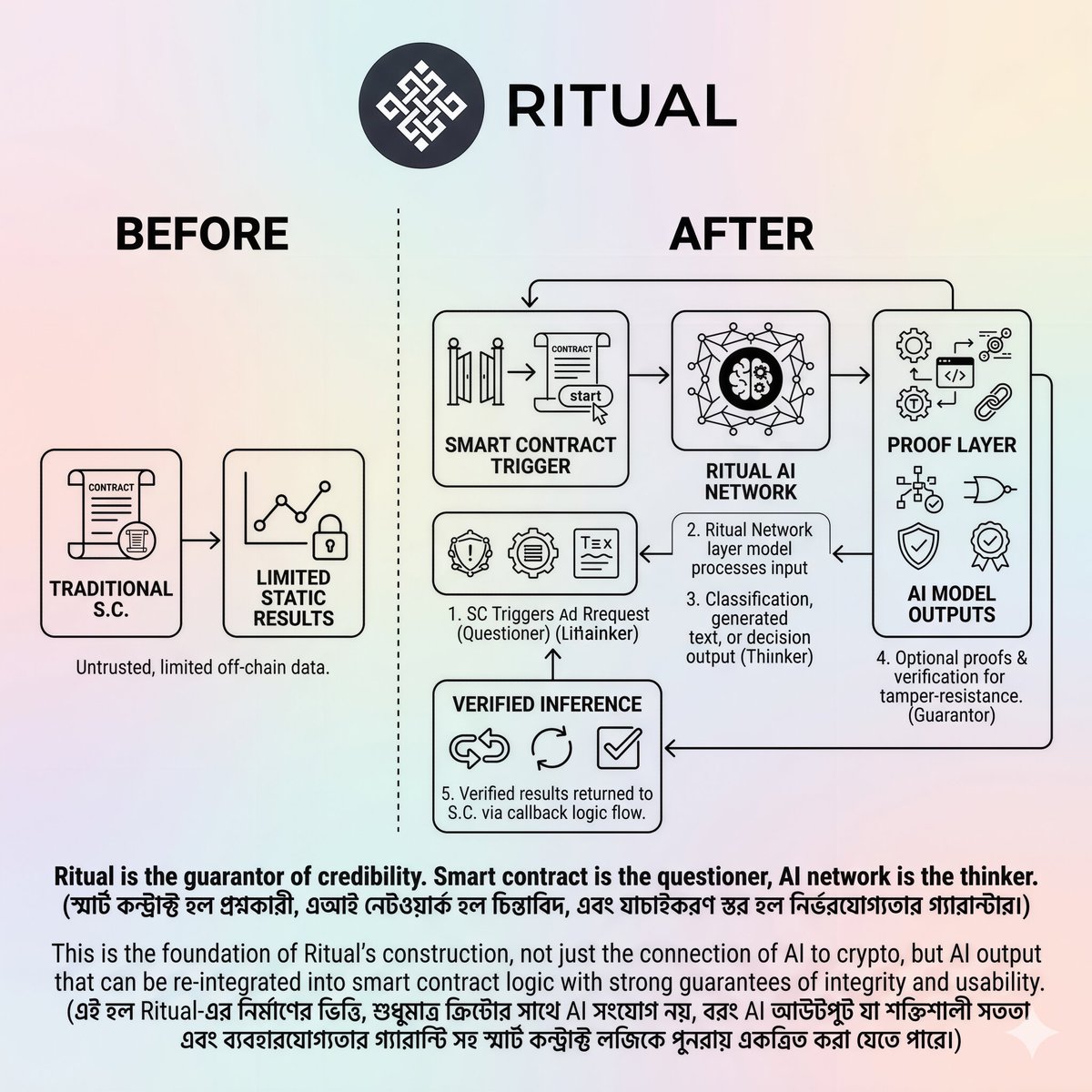
• @ritualnet, the smart contract does not directly run any AI model, it simply sends a request to a compute node. The work is done at the network’s designated model layer.
The process from request to receipt of verified results is completed in five steps:
First, the contract triggers a request when an output is required. In the second step, that request reaches the Ritual AI network or infernet layer and the corresponding model processes the input. In the third step, the model produces classification, generated text, or decision support results.
In the fourth step, optional proof and verification methods are used to ensure that the computations have not been tampered with. In the fifth and final step, the verified results are returned to the smart contract following the callback flow specified in the documentation and the subsequent logic of the contract is executed.
Summary:
The smart contract is the questioner, the AI network is the thinker, and the verification layer is the guarantor of credibility. In an on-chain system, getting an answer is not enough, the key is that the answer is reliable.
This is the foundation of Ritual’s construction, not just the connection of AI to crypto, but AI output that can be re-integrated into smart contract logic with strong guarantees of integrity and usability.
@joshsimenhoff @ritualfnd
@Jez_Cryptoz
MD RIFAT@RIFAT5666
𝗠𝗼𝘀𝘁 𝗔𝗜 𝘀𝘆𝘀𝘁𝗲𝗺𝘀 𝗮𝗿𝗲 𝗯𝗼𝗴𝗴𝗲𝗱 𝗱𝗼𝘄𝗻 𝗯𝘆 𝗮 𝗰𝗼𝗺𝗽𝗹𝗲𝘅 𝗾𝘂𝗲𝘀𝘁𝗶𝗼𝗻: Do you want the answer now, or do you want proof that the answer is reliable? Fast output is attractive to users, but speed alone does not guarantee reliability. Latency and verification serve as conflicting goals in AI infrastructure. Reduced latency makes the system feel smoother, and strong verification limits the opportunity for manipulation or falsification of results. @ritualnet’s Infernet does not view this conflict as a permanent two-way street. Its design creates an integrated framework for handling inference requests according to the needs of each situation. Infernet supports multiple inference services and request flows, and optionally adds a proof mechanism to ensure computational authenticity where necessary. 𝗧𝗵𝗲 𝗸𝗲𝘆 𝗾𝘂𝗲𝘀𝘁𝗶𝗼𝗻 𝘁𝗵𝗲𝗿𝗲𝗳𝗼𝗿𝗲 𝗯𝗲𝗰𝗼𝗺𝗲𝘀 𝗿𝗲𝗹𝗲𝘃𝗮𝗻𝘁: when is speed enough, and when is higher certainty of the result essential? Not every use case is at the same risk. Some requests can be handled with limited verification, while others require more rigorous proof before trust can be placed. Getting answers quickly means solving the problem and moving forward. Verification is the second layer where the stability of the work is checked. Eliminating this layer increases speed, but increases reliance on assumptions. If you want full guarantees in every case, the system becomes cumbersome. The intelligent path is not to choose one side forever, but to build an infrastructure capable of handling both needs. Infernet indicates that balance, where there is neither distrust nor practical difficulties, but rather a smooth combination of the two, understanding the situation. @ritualfnd @joshsimenhoff @Jez_Cryptoz
English

Teleoperation is often portrayed as a laborious obstacle, but this view ignores the real potential.
The real goal is not simply to put more robots in the hands of more people. The point is to turn every human correction into a permanent structural asset.
If an operator's instructions are lost as soon as the task is completed, the system is memoryless. It gets the job done, but it doesn't have the ability to learn deeply from real-world experience.
What matters is whether each intervention leaves something behind that is sustainable, clear traces of the decisions, the context, the quality of the movement, and the circumstances that determined the outcome.
And this is where @PrismaXai is intriguing to me.
It brings teleoperation closer to a permanent level of coordination, where every action is recorded, evaluated, and re-enacted as usable intelligence within the system.
Once this cycle is in place, human labor is no longer a temporary fix.
It becomes a composite source of operational knowledge that paves the way for training improvements, workflows, and future efficiency gains across the entire network.
Website: prismax.ai
Discord: discord.gg/prismaxai
X: @PrismaXai

English