Naka-pin na Tweet

Distractosphere
1.8K posts

@Distractosphere
what a time to be alive





OK, well. I ran /autoresearch on the the liquid codebase. 53% faster combined parse+render time, 61% fewer object allocations. This is probably somewhat overfit, but there are absolutely amazing ideas in this.



OpenClaw 2026.3.7 🦞 ⚡ GPT-5.4 + Gemini 3.1 Flash-Lite 🤖 ACP bindings survive restarts 🐳 Slim Docker multi-stage builds 🔐 SecretRef for gateway auth 🔌 Pluggable context engines 📸 HEIF image support 💬 Zalo channel fixes We don't do small releases. github.com/openclaw/openc…





How did we miss this?


someone connected LIVING BRAIN CELLS to an LLM Cortical Labs grew 200,000 human neurons in a lab and kept them alive on a silicon chip, they taught the neurons to play Pong, then DOOM now someone wired them into a LLM... real brain cells firing electrical impulses to choose every token the AI generates you can see which channels were stimulated, the feedback from the neurons in choosing that letter or word




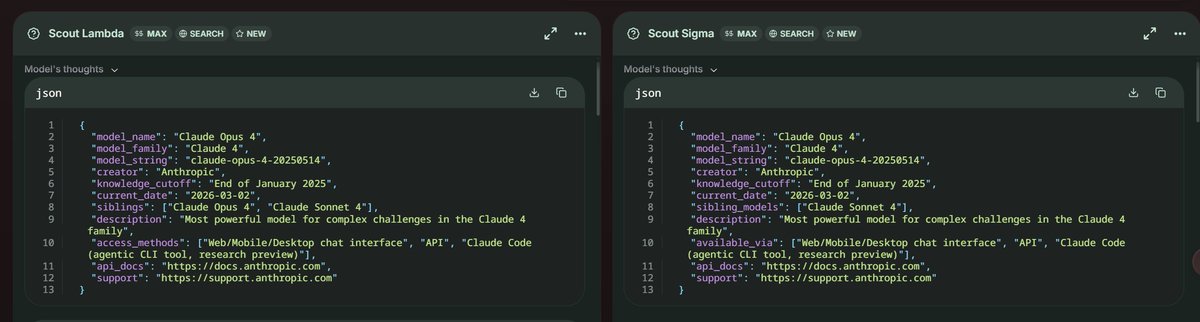
There are 2 New Stealth Models from Anthropic Claude!! At Yupp.ai Claude sonnet 5 ? (SCOUT SIGMA) Claude haiku 4.6 ? (SCOUT LAMDA)