
Fake Devs
210 posts

Fake Devs
@fake_devs
i own a vps
شامل ہوئے Eylül 2023
67 فالونگ7 فالوورز


English

@TheAhmadOsman Let's see what the European price of Intel ARC B70 will be. If it is close to one third of Nvidia RTX 5090, then it will be like a third of it in memory bandwidth & compute as well, but also almost 3 times less power and price. Price/performance ratio = same.
English

please don't waste your money or time on this for LLMs / local AI
Pirat_Nation 🔴@Pirat_Nation
Intel launched the Arc Pro B70 GPU at $949. It has 32 Xe cores, 32GB GDDR6 memory, up to 367 peak TOPS for AI, and 608 GB/s bandwidth.
English


@KingBootoshi Wait for @taalas_inc to release a Qwen3.5 27b card.
Their first Llama 3.1 8B cards run at 17k token/s
Maybe request API access and test if your harness can carry 8b llama for now
English

I DON'T NEED THESE LLMS TO BE MORE INTELLIGENT MAN I NEED THEM TO BE FASTER
I NEED CODE DONE AT THE BLINK OF AN EYE
THE BASE LEVEL INTELLIGENCE WE NEED FOR INSANE THINGS IS THERE
THE HARNESS CARRIES THE REST
IMAGINE IF THEY INSTANTLY ZIP THROUGH THE HARNESS & CHECKS! BONKERS
English

If you start an app now, please don't use:
1. Supabase = you will regret it.
→ use Convex, Neon, Better-Auth instead
2. Clerk = this is the worst choice ever
→ use Better-Auth instead
3. Supabase Storage or AWS S3
→ use Cloudflare R2, this is the cheapest you can have
4. Namecheap: laggy, buggy, boring
→ use Porkbun or Cloudflare
5. MongoDB = just don't
English

Every time an LLM says anything to me, I automatically assume it's BS unless it's read a source confirming it
NONE of the non-devs I talk to have this instinct
English
Fake Devs ری ٹویٹ کیا

@GeminiApp Why would anyone in their right mind move over to an AI Chat app that doesn't have branching and editing?
Literally everyone else has branching and editing.
This just shows that Google has no idea how people use those chat apps to get work done.
English

Switching to Gemini from other AI apps just got easier.
Starting to roll out today on desktop, you can now bring your preferences and chat history into Gemini, so you can pick up right where you left off in just a few clicks. 🧵

English

I love the retro airport terminal look, but didn't want to spend $3.5k on a vestaboard. I coded a fun tool that turns any tv into a vestaboard.
> add quotes / weather / stats etc
> no subscription, $199 one time fee
> first customer gets a free tv
hmu :)
English

You're not imagining it.
Despite Anthropic's 2x usage promo, people all over X and Reddit are complaining about hitting limits faster than before.
Doubled and still worse. That's how far the baseline has dropped.
Pranit@Pranit
Anthropic just pulled the oldest trick in SaaS pricing. I pay $200/mo for Claude Max. My limits have been noticeably worse this past week. Now they announce 2x off-peak usage for two weeks. Sounds generous. But here’s what actually happens: limits quietly drop, a temporary 2x makes the reduced limit feel normal, the promo ends, and you’re left at a baseline lower than where you started. You just didn’t notice the downgrade because the 2x absorbed the transition. These AI plans are massively subsidized. The raw compute behind a heavy user costs multiples of the subscription price. Every move like this is the subsidy quietly correcting. Very sneaky, Anthropic.
English
This key is literally @Microsoft telling you to not buy any windows laptop for real work.
Forced to use this for over 12 months now. Every day you get reminded that there is no right control key.
This really shows that no one at @Windows uses a windows laptop at all.

English

TurboQuant implemented in MLX with 6/6 exact match at every quant level across 64K context. That's not a compromise, that's compression magic.
4.9x smaller KV cache at 2.5-bit means models that used to need 64GB RAM now fit in 13GB. Local inference just changed forever.
Prince Canuma@Prince_Canuma
Just implemented Google’s TurboQuant in MLX and the results are wild! Needle-in-a-haystack using Qwen3.5-35B-A3B across 8.5K, 32.7K, and 64.2K context lengths: → 6/6 exact match at every quant level → TurboQuant 2.5-bit: 4.9x smaller KV cache → TurboQuant 3.5-bit: 3.8x smaller KV cache The best part: Zero accuracy loss compared to full KV cache.
English
@CreationsRoss I mean, if the the joke is "haha I gave you free cake" then I'm all for it
English

@varun_mathur For some reason, this reads like something @Cloudflare would offer in the near future
English

The Cost of Intelligence is Heading to Zero | Hyperspace P2P Distributed Cache
We present to you our breakthrough cross-domain work across AI, distributed systems, cryptography, game theory to solve the primary structural inefficiency at the heart of AI infrastructure: most inference is redundant.
Google has reported that only 15% of daily searches are truly novel. The rest are repeats or close variants. LLM inference inherits this same power-law distribution. Enterprise chatbots see 70-80% of queries fall into a handful of intent categories. System prompts are identical across 100% of requests within an application. The KV attention state for "You are a helpful assistant" has been computed billions of times, on millions of GPUs, identically.
And yet every AI lab, every startup, every self-hosted deployment - computes and caches these results independently. There is no shared layer. No global memory. Every provider pays the full compute cost for every query, even when the answer already exists somewhere in the network.
This is the problem Hyperspace solves where distributed cache operates at three levels, each catching a different class of redundancy:
1. Response cache
Same prompt, same model, same parameters - instant cached response from any node in the network. SHA-256 hash lookup via DHT, with cryptographic cache proofs linking every response to its original inference execution. No trust required. Fetchers re-announce as providers, so popular responses replicate naturally across more nodes.
2. KV prefix cache
Same system prompt tokens - skip the most expensive part of inference entirely. Prefill (computing Key-Value attention states) is deterministic: same model plus same tokens always produces identical KV state. The network caches these states using erasure coding and distributes them via the routing network. New questions that share a common prefix resume generation from cached state instead of recomputing from scratch.
3. Routing to cached nodes
Instead of transferring KV state across the network for every request, Hyperspace routes the request to the node that already has the state loaded in VRAM. The request goes to the cache, not the cache to the request.
Together, these three layers mean that 70-90% of inference requests at network scale never require full GPU computation.
This work doesn't exist in isolation. It builds on research from across the industry: SGLang's RadixAttention demonstrated that automatic prefix sharing can yield up to 5x speedup on structured LLM workloads. Moonshot AI's Mooncake built an entire KV-cache-centric disaggregated architecture for production serving at Kimi. Anthropic, OpenAI, and Google all launched prompt caching products in 2024 - priced at 50-90% discounts - because system prompt reuse is so pervasive that it changes the economics of inference.
What all of these systems share is a common limitation: they operate within a single organization's infrastructure. SGLang caches prefixes within one server. Mooncake disaggregates KV cache within one datacenter. Anthropic's prompt caching works within one API provider's fleet. None of them can share cached state across organizational boundaries.
Hyperspace removes this boundary. The cache is global. A response computed by a node in Tokyo is immediately available to a node in Berlin. A KV prefix state generated for Qwen-32B on one machine is verifiable and reusable by any other machine running the same model. The routing network provides the delivery guarantees, the erasure coding provides the redundancy, and the cache proofs provide the trust.
What this means for the cost of intelligence
Big AI labs scale linearly: twice the users means twice the GPU spend. Every query is a cost center. Their internal caching helps, but it's siloed - Lab A's cache can't serve Lab B's users, and neither can serve a self-hosted Llama deployment.
Hyperspace scales sub-linearly. Every new node that joins the network adds to the global cache. Every inference result enriches the cache for all future requests. The cache hit rate rises with network size because query distributions follow a power law - the most common questions are asked exponentially more often than rare ones.
The implication is simple: as the network grows, the effective cost per inference drops. Not linearly. Logarithmically.
At 10 million nodes, we estimate 75-90% of all inference requests can be served from cache, eliminating 400,000+ MWh of energy consumption per year and
avoiding over 200,000 tons of CO2 emissions. The first person to ask a question pays the compute cost. Everyone after them gets the answer for free, with cryptographic proof that it's authentic.
Training is competitive. Inference is shared
Open-weight models are converging on quality with closed models. Labs will continue to differentiate on training - data curation, architecture innovation, RLHF tuning. That's where the real intellectual property lives.
But inference is a commodity. Two copies of Qwen-32B running the same prompt produce the same KV state and the same response, byte for byte, regardless of whose GPU runs the matrix multiplication. There is no moat in multiplying matrices. The moat is in training the weights.
A global distributed cache makes this separation explicit. It doesn't matter who trained the model. Once the weights are open, the inference cost approaches zero at scale - because the network remembers every answer and can prove it's correct.
No lab, no matter how well-funded, can match this. They cannot share caches across competitors. They scale linearly. The network scales logarithmically. The
marginal cost of intelligence approaches zero.
That's the endgame.
English
@digitalix I cannot stress enough how fast I need your video on this one
English

32GB of VRAM for under $1000!
The Intel Arc Pro B70 just landed.
English
@deepak21684 @IntCyberDigest The maintainers patched it out.
You were affected only if you installed during a ~16 hours time window.
Fyi; if you uninstalled to be save. You can check your uv cache to see which litellm version was installed.
For me it was unfortunately 1.82.7

English

@fake_devs @IntCyberDigest I also installed the Hermes Agent yesterday but I don't see a litellm dependency in the requirements.txt. See screenshot below (what am I missing?)
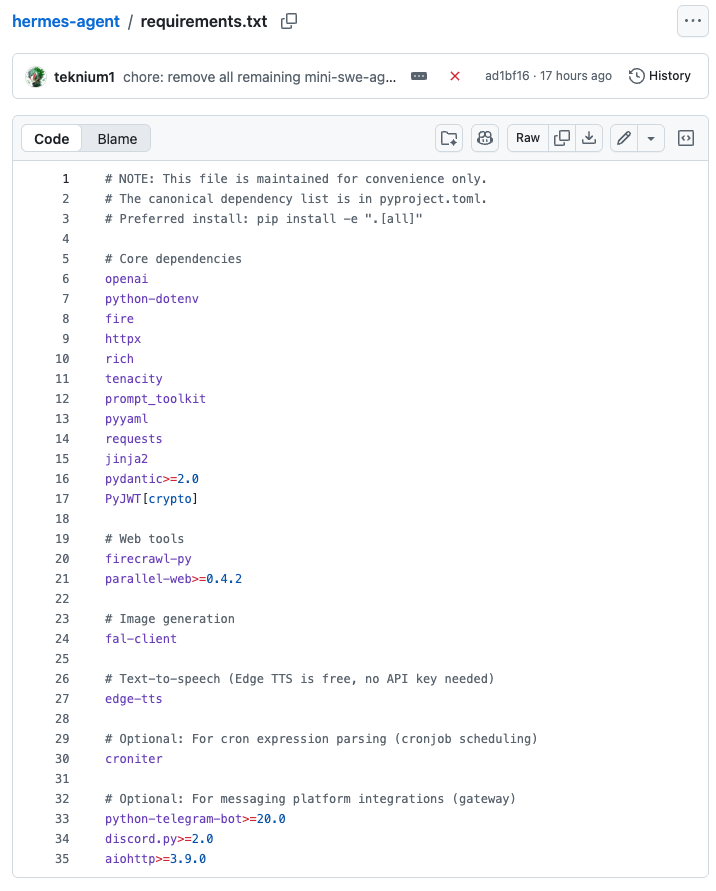
English

🚨‼️ We're in contact with the actor behind the Trivy and LiteLLM hack. They told us they are currently extorting several multi-billion-dollar companies from which they've exfiltrated data.
They've obtained 300 GB of compressed credentials and are working their way through them as we speak.
The LiteLLM compromise alone led to half a million stolen credentials, according to the threat actor.
Their message to the world: "TeamPCP is here to stay. Long live the supply chain."
They've sent us their new logo (see image) and also teamed up with several threat actors, including Xploiters and Vect.

English

My feed is showing me a bunch of folks who tapped out their whole usage limits on Mon/Tue.
Is this your experience? Please comment, I want to understand how widespread this is
Alexey Grigorev@Al_Grigor
I hit my limits very quick this week - even with 20x pro plan. It makes my claude code unusable A good reason to do more stuff with Codex!
English