
If you're smart and do research, in this case in AI, you're still safe when Mythos drops. smol comfort

English
im not a cat
6.1K posts

SOMEONE TURNED THE VIRAL "TEACH CLAUDE TO TALK LIKE A CAVEMAN TO SAVE TOKENS" STRATEGY INTO AN ACTUAL CLAUDE CODE SKILL one-line install and it cuts ~75% of tokens while keeping full technical accuracy they even benchmarked it with real token counts from the API: > explain React re-render bug: 1180 tokens → 159 tokens (87% saved) > fix auth middleware: 704 → 121 (83% saved) > set up PostgreSQL connection pool: 2347 → 380 (84% saved) > implement React error boundary: 3454 → 456 (87% saved) > debug PostgreSQL race condition: 1200 → 232 (81% saved) average across 10 tasks: 65% savings. range is 22-87% depending on the task. three intensity levels: > lite: drops filler, keeps grammar. professional but no fluff > full: drops articles, fragments, full grunt mode > ultra: maximum compression. telegraphic. abbreviates everything works as a skill for Claude Code and a plugin for Codex. this is PEAK




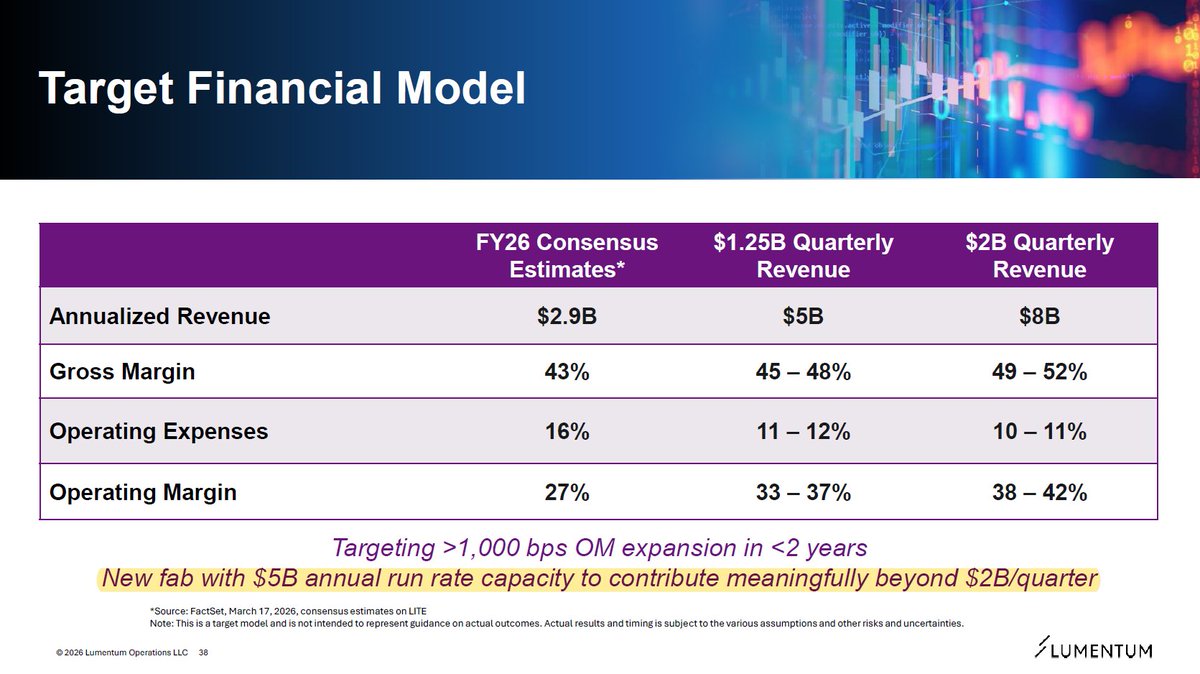
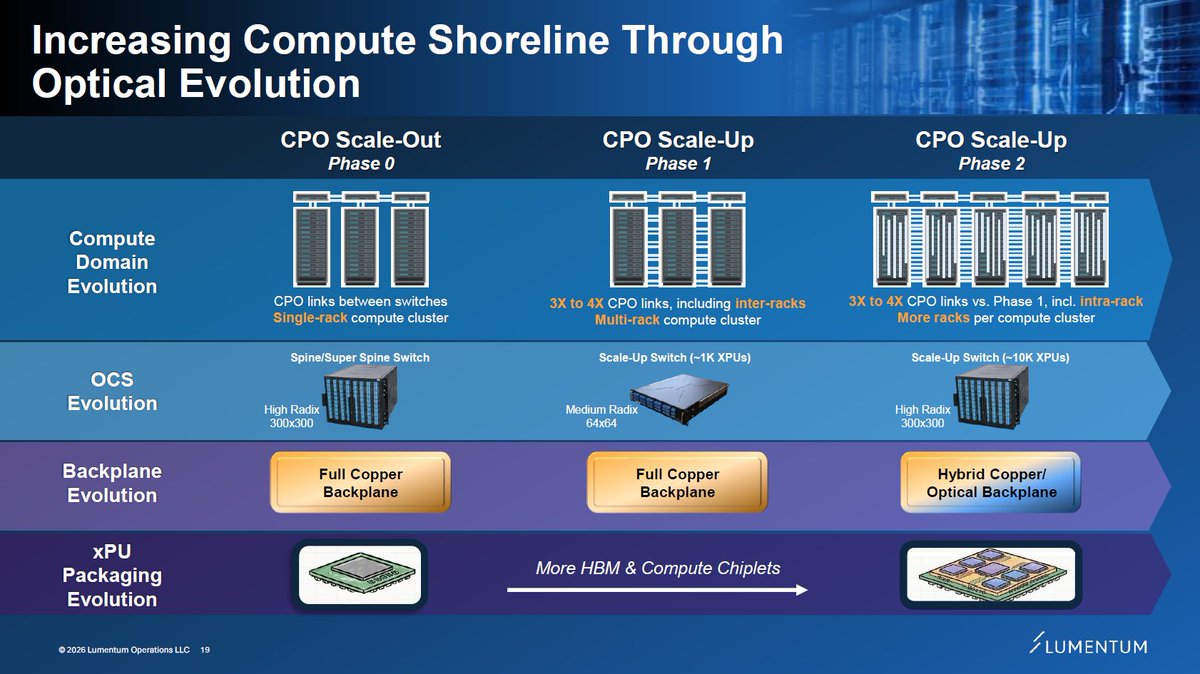

I might be 70% there in understanding CPO scale-up opportunity through Feynman, but some technical clarifications plus coming supplier datapoints should take that to 80-90%? Inter-rack optical scale-up for NVL576, as mentioned earlier, appears confirmed for Oberon. But that's only a first step. Scale-out near term is well understood. Orders received to date by $LITE or $COHR and their high level TAM statements seem roughly consistent. Jensen is often imprecise during presentations, but that often leads to opportunities. This is one of many AI technologies where fortunes could be made or lost over the next years.



Perplexity just became the the first Al company to truly go head-to-head with the Bloomberg Terminal... Using Perplexity Computer (with no local setup or single LLM limitation), it was able to build me a terminal with real-time data to analyze $NVDA using Perplexity Finance:


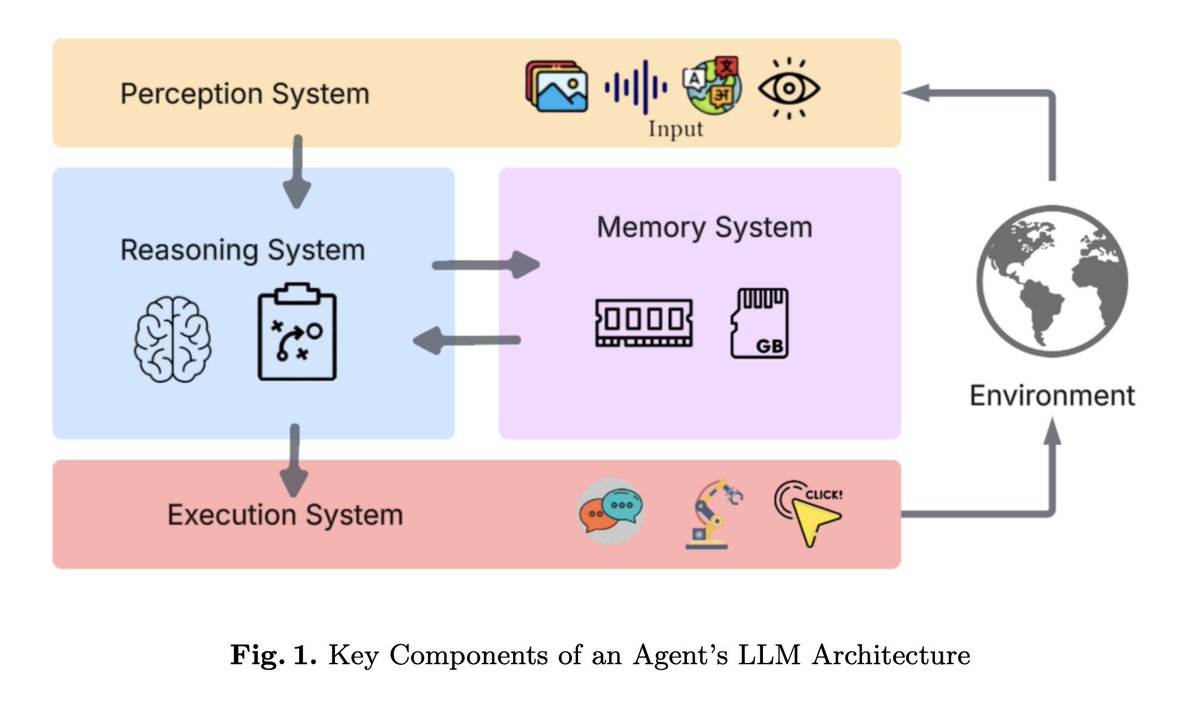

Still waiting
Once again Beth has performed wonderfully for family reunion If u knew Beth like I know Beth u would know the dependability I know


