تغريدة مثبتة
LDJ
466 posts


LDJ
@ldjconfirmed
Currently: Doing some stuff with AI. Prev founding team of: @NousResearch (2023) and @TTSLabsAI (2020) DM for interesting conversations.
S4 انضم Mart 2021
709 يتبع6K المتابعون
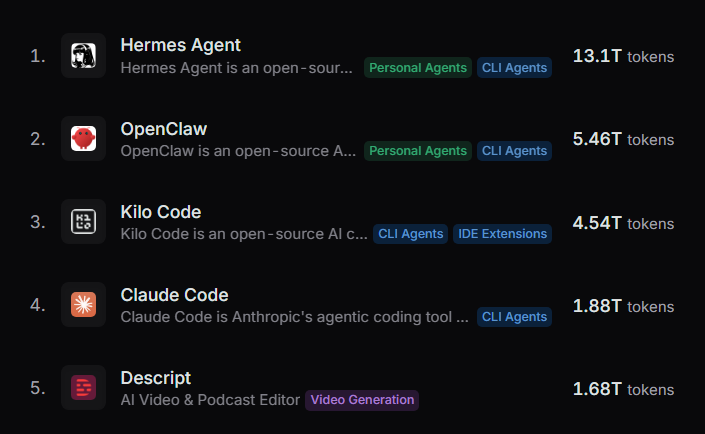
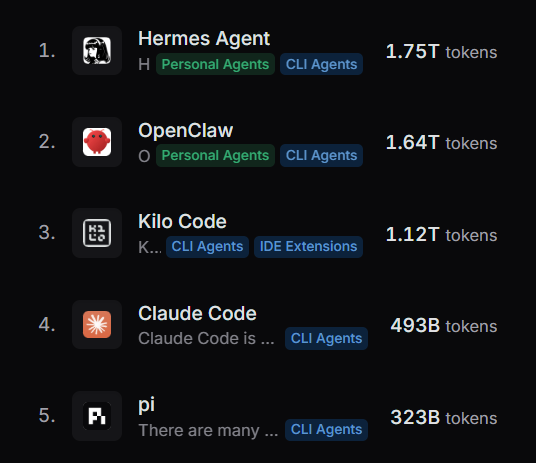
@kelstar_ @NousResearch @OpenRouter Not sure why that would impact the rankings in this way. But further update now; Hermes Agent is now #1 on the monthly global charts too, and is so far ahead that it has more usage than OpenClaw, Kilo Code and Claude Code combined.
English

@ldjconfirmed @NousResearch @OpenRouter Do you think it has anything to do with the codex subscription being hyped and so good right now?
English

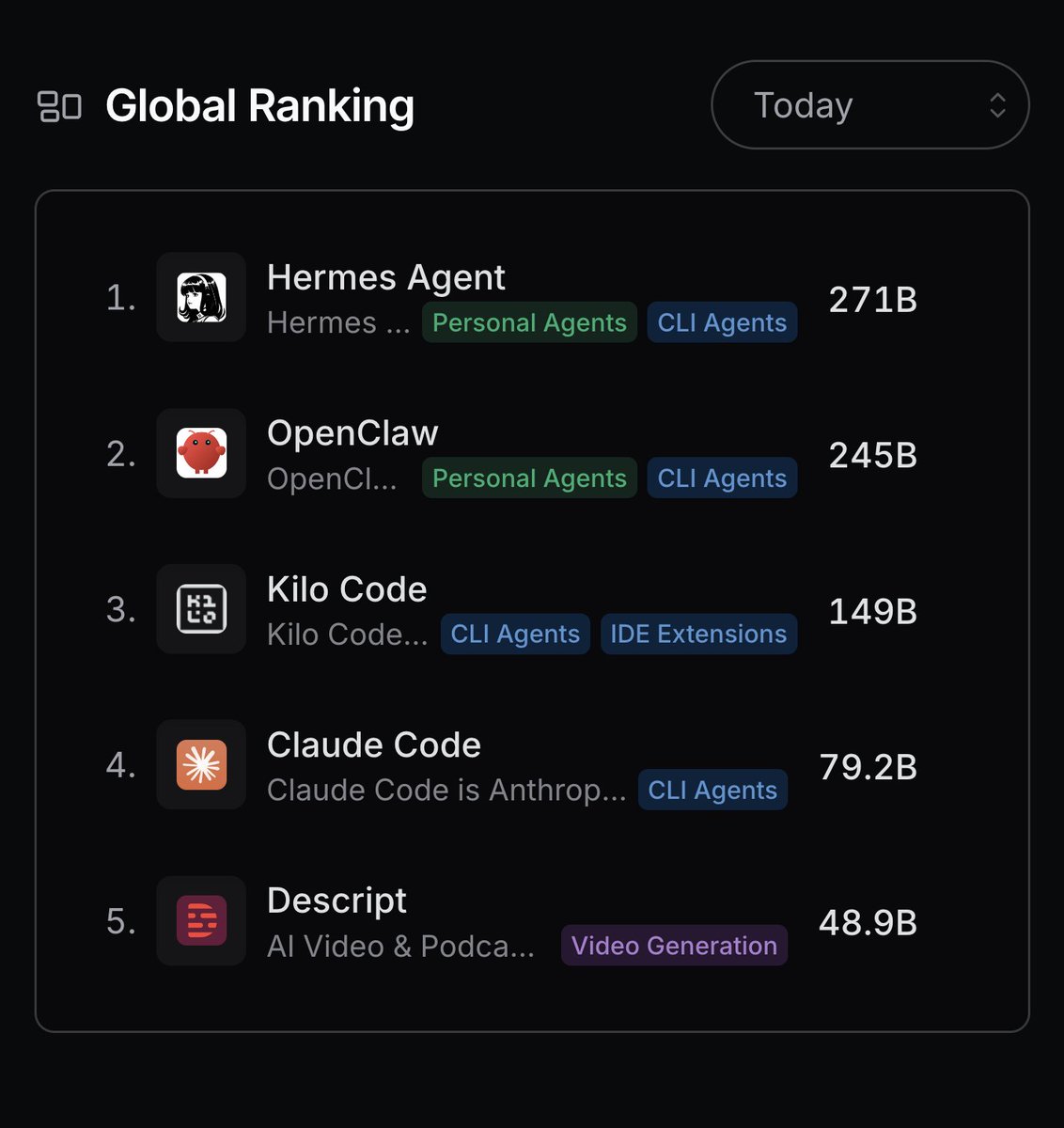
Hermes Agent is now #1 on the Global @OpenRouter token rankings.
While our journey together has just begun, we'd like to take this opportunity to thank our contributors, supporters, and users for all they have done to get us this far.
English
English
@kelstar_ @OpenRouter It's the daily global chart as clearly indicated in the screenshot. Don't worry, we'll do an all time #1 post when we get there too!
English


I'm speechless at Google signing a deal to use our AI models for classified tasks. Frankly, it is shameful.
For HR, I'm not speaking on behalf of Google but in my personal capacity, quoting public information from a well-sourced article of a reputable publication
English
Roughly related but I don't think they intend to use any GDPval score as evidence for AGI being achieved. They say in the paper themselves that it's largely work that is only a time-horizon of a few hours and the context is much more assisted than a real job. GDPVal is also far easier and more saturated than something like RemoteLaborIndex which comprises of real Upwork tasks (but still not typical employment positions)
Current GDPVal SOTA is over 80%
Current RemoteLaborIndex SOTA is less than 5%
English


As to the timeline for OpenAI declaring AGI, recall that Amazon has committed to invest $35B in OpenAI upon the earlier of: (1) OpenAI IPO, or (2) OpenAI meeting "specified milestones" - which Reuters reported means OpenAI declaring AGI. Importantly, Amazon's commitment to invest $35B *expires* on December 31, 2028.
Timing for the IPO depends heavily on market conditions. Thus, if Reuters' reporting was accurate, OpenAI must have felt very confident that AGI will be declared within the next ~2 years.

English
@daniel_mac8 @deredleritt3r In Microsofts October 2025 blog post about their latest partnership terms with OpenAI:
"Once AGI is declared by OpenAI, that declaration will now be verified by an independent expert panel."
English
@deredleritt3r true! hard for me to imagine how you can base an agreement on such vague language (unless, as you mention Prinz, it's more precise in the private agreement)
English
@deredleritt3r @daniel_mac8 "Economically valuable work" is further defined by people internally at OpenAI as the jobs tracked by the US bureau of labor statistics. So I suppose it's a majority of those jobs that they mean.
English
Not just "most"! What is "outperforming humans" - do we mean the average human, a Ph.D, a child...? What is "economically valuable work" - jobs or tasks? And do we include physical labor or not?
Some of these things may be explained further in the agreement, but again that's never been made publicly available.
English
@deredleritt3r In Feb 2026, Sam Altman said at a Stanford hackathon:
“If you are a sophomore now, you will graduate into a world with AGI in it"
Sophomores in Feb 2026 are set to graduate around mid-2028. I believe this is the first and only time he's stated such a near-term AGI prediction.
English
@ChaosEmergent @haider1 GPT-4.5 started training ~may 2024, almost exactly 2 years ago now. (Based on official OpenAI statements that mentioned starting training on their new next generation model at the time, along with corroboration from WallStreetJournal and others)
English

@haider1 wait then what was gpt-4.5
I assumed that the 5-series were distilled from 4.5 then RLVR'd as smaller models
English

greg brockman recently confirmed that "spud" is openai first new pre-train model in two years
since gpt-5.x models seem to build on gpt-4o/4-turbo, if openai RL can push a weaker base model like gpt-4o close to gpt-5.4-x-high-level intelligence
then openai clearly has a secret sauce
English
@zephyr_z9 That quote is not true to what he said. His statement was directly opposite of the what you created within your quotations. Here is his actual quote about that topic: "Even by 2028, I don’t expect that we’ll get systems as smart as people in all ways"
English


What's your AI adoption level?
(according to Steve Yegge)
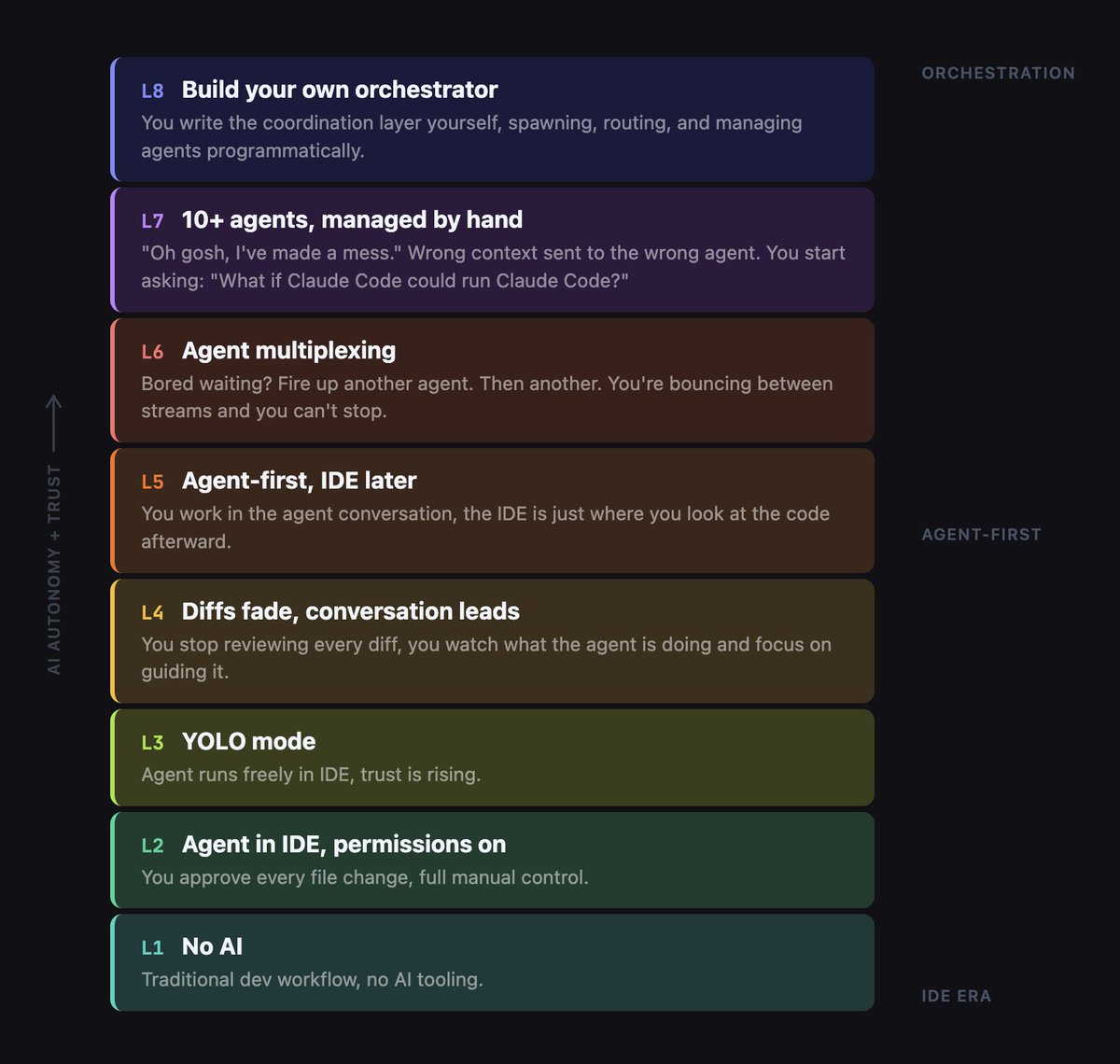
English
@otium33 @BasedBiohacker @bryan_johnson He has already publicly talked about results of his personal peptide experimentation prior to doing his shroom experiments.
English

@BasedBiohacker @bryan_johnson I’m honestly very confused why he is taking shrooms but not peptides
English

bryan johnson was NOT tracking 100+ biomarkers, doing blood transfusions with his son and turning down sex to sleep at 8:30 when he was building braintree/ venmo
he was dogging it on cheeseburgers, stimulants and zero sleep
he was fat. unhappy. suffered from existential doubt.
the state of madness that births greatness.
he only got into longevity because he lost purpose when he sold his company to paypal for $800 million
so no bro, you should not be comparing yourself to nor model your life after what lizard johnson is doing.
you can focus on that when you sell your biz for just short of a billion fucking dollars.
focus on output and results, not optimizing for 50 years from now.
yes - don't nuke your brain with amphetamines and coke, but also don't get so neurotic about health that you sacrifice your potential.
max output. max results.
you can track your nighttime boners and do total plasma exchanges when you have 100 mill.
English
@haider1 It's been confirmed that some devs outside of OpenAI had early access to GPT-5.4 for atleast "a few weeks" prior to public release.
Exhibit A:
Pietro Schirano@skirano
This model is absolutely insane. I’ve been using it for a few weeks, and it’s the first model that made the impossible feel possible for me. Particularly the pro version , it’s capable of solving even the hardest problems.
English
openai probably didn't have the model just sitting there for a while
instead, gpt-5.4 was likely a checkpoint from a model that was still training, released when they felt pressure
even logan from google told me in DM that:
"google doesn't hold models back because the competition is high"
English
@thebasedcapital I think it did well. It lasted nearly 3 full years.
English

@ldjconfirmed benchmarks built to prove ai can't do something have a short shelf life. the gaia authors probably expected it to last years, not months. at some point you have to stop moving the goalposts and accept that general capability is here even if it's not agi
English
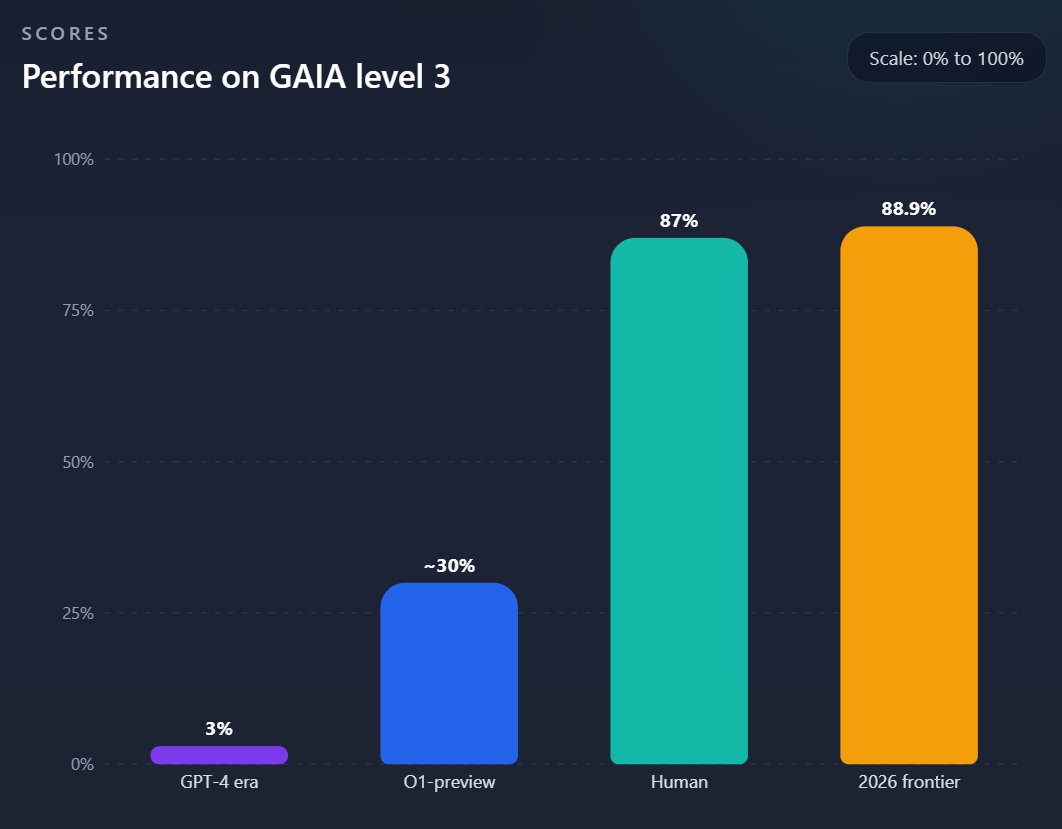
In November 2023, Yann LeCun, Thomas Wolf and others from Meta and Huggingface created a benchmark called GAIA, which described itself as: "A benchmark for General AI Assistants that, if solved, would represent a milestone in AI research." Most of the problem solutions were kept private, not released online.
It proposed 466 "real-world questions that require a set of fundamental abilities such as reasoning, multi-modality handling, web browsing, and generally tool-use proficiency."
On the hardest level, the average human score was 87%, while the leading systems scored less than 3%. 10 months later OpenAI released O1-preview, reaching ~30% on that level.
Now in 2026 the human baseline for the hardest level has officially been surpassed, the best agent systems are now scoring 88.9% on GAIAs hardest level (level 3).
English
@ThomasScialom Unfortunately I can’t find any human baselines for GAIA 2.
English

@ldjconfirmed There is Gaia 2 now which is a very good eval for environments a la Openclaw
English
@xundecidability @WaveTheoryAI The difference here is that GAIA is real world questions involving highly specific information that exists amongst human civilization across a diverse set of modalities, not an abstract puzzle.
English

@WaveTheoryAI @ldjconfirmed "designed" is aspirational, its possible their design was defeated. ARC also aspired to this, but the labs soon learned to beat it. O1 was the first model they fine-tuned on it, but they didn't release that version because it was dumber at everything else.
English
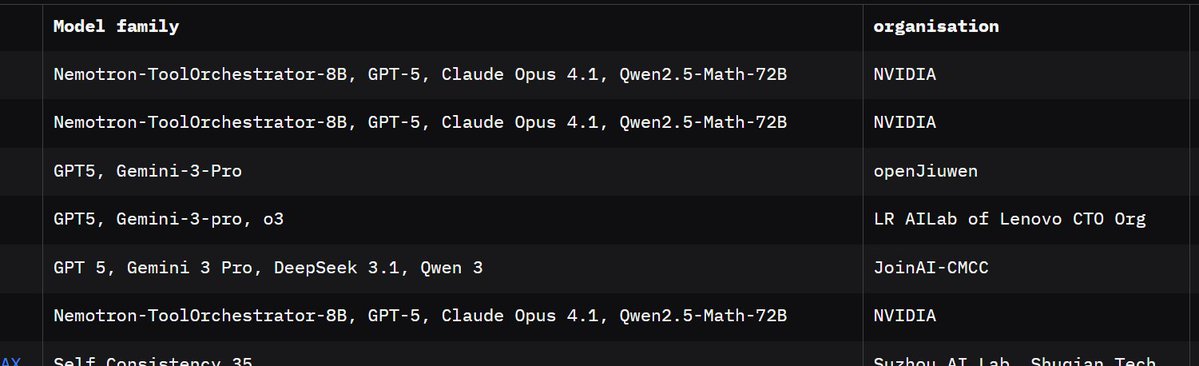
@nithin_k_anil The human baseline score was also matched/surpassed by GPT-5 and Gemini-3-Pro working together without any specialized orchestrator in the loop, and only scored ~2% below the top score by Nvidia. I imagine Opus 4.6, GPT-5.4 and Gemini-3.1 together would get an even better score.
English
The current highest level 3 score was achieved by Nvidia, leveraging a multi-agent system that includes Nvidias own tool orchestrator model. It scores 89.8% on Lvl 3 (even higher than the 88.9% typo I wrote above)
The public leaderboard can be seen here: huggingface.co/spaces/gaia-be…
English
This is the best AI-generated short film esque media I’ve seen thus far. Not just visually, but actual storytelling to go with it too.
Next on Now@next_on_now
1:1 is coming, will you even be ready?
English