
Vhiz
306 posts

Microsoft did something interesting here 👀
“Unlike typical LLMs that are trained to play the role of the "assistant" in conversation, we trained UserLM-8b to simulate the “user” role in conversation”
huggingface.co/microsoft/User…
English
@i_am_brennan @gunta85 how do i define a pipeline here? and do i get to see the underlying dspy code?
English

@gunta85 Also check out gepazilla.com if you want an OSS ui to play with GEPA
English

I award GEPA the “Most Under-Hyped Paper of the Year” prize. 🏆
Why isn't everyone talking about this?
We might need an amazing logo and landing page.
Get your AI project GEPA™️ certified.
github.com/gepa-ai/gepa
Lakshya A Agrawal@LakshyAAAgrawal
What's stopping you from trying GEPA right now? P.S.: Please go try GEPA!🥹 x.com/tobi/status/19…
English
@samsja19 @QuanquanGu Can you please point to resources which talk about sota grpo
English

@QuanquanGu I would call this a minor issue, the whole idea behind group advantage is still very powerful.
Also sota "grpo" has evolved a lot since then and it's not that much an off policy algorithm anymore
English

@athleticKoder Nice thread Anshuman. One question though: metrics like contextual recall would require the ground truth to be present. So how do you do async batch eval of prod traffic?
English


Go use DSPy Signatures and Modules!
It's useful without the optimizers and most of my production DSPy usage is without optimizers
Pratik Desai@chheplo
If you’re seeing DSPy, Evals, GEPA etc a lot on your timeline, you’re following too many AI consultants and influencers.
English

I got around to kicking the tires on GEPA prompt optimization in DSPy, seeing if it could match the reported gsm8k benchmark for Qwen3-4b-thinking.
Started with the simplest signature:
qa_bot = dspy.Predict('question -> answer')
GEPA got it from 67.2% to 92.8%.
English
Vhiz retweetet

𝙿̲𝚊̲𝚛̲𝚕̲𝚊̲𝚗̲𝚝̲ 𝟹̲.𝟶̲ 𝚒̲𝚜̲ 𝚘̲𝚏̲𝚏̲𝚒̲𝚌̲𝚒̲𝚊̲𝚕̲𝚕̲𝚢̲ 𝚛̲𝚎̲𝚕̲𝚎̲𝚊̲𝚜̲𝚎̲𝚍̲!
Proud to announce our most significant framework overhaul since its inception. See what it's all about at Parlant(io).
This version transforms Parlant into a production-ready conversational AI framework for customer-facing applications.
With dramatic performance improvements, reworked developer experience, and enterprise-grade security features, Parlant 3.0 is ready to fix your hardest AI consistency issues and power your most critical customer-facing applications.
"𝘉𝘺 𝘧𝘢𝘳 𝘵𝘩𝘦 𝘮𝘰𝘴𝘵 𝘦𝘭𝘦𝘨𝘢𝘯𝘵 𝘤𝘰𝘯𝘷𝘦𝘳𝘴𝘢𝘵𝘪𝘰𝘯𝘢𝘭 𝘈𝘐 𝘧𝘳𝘢𝘮𝘦𝘸𝘰𝘳𝘬 𝘵𝘩𝘢𝘵 𝘐 𝘩𝘢𝘷𝘦 𝘤𝘰𝘮𝘦 𝘢𝘤𝘳𝘰𝘴𝘴! 𝘋𝘦𝘷𝘦𝘭𝘰𝘱𝘪𝘯𝘨 𝘶𝘴𝘪𝘯𝘨 𝘗𝘢𝘳𝘭𝘢𝘯𝘵 𝘪𝘴 𝘱𝘶𝘳𝘦 𝘫𝘰𝘺!” — Vishal Ahuja, JPMorgan Chase
I know many have awaited the improvements in this new release — and many have helped test it. We do it all for our users, as we've become obsessed with the massive challenge of getting customer-facing AI agents under control. Parlant (@EmcieCo) is continuing to lead this endeavor.
If you haven't tried it yet, you should, as it's like nothing you've already tried. Check out the blog below for a summary of the release and what's coming next (1st comment)
English
@SkodaIndia - 14k kms and the clutch is not working. Skoda Kushaq top-end model..And the dealer is charging 36k. I haven't heard of clutch having to replaced after just 14k kms. This is unacceptable
English
I post about niche LLM and Search things on my personal WhatsApp channel in case you want to get it even without depending on the Twitter algorithm!
whatsapp.com/channel/0029Va…
English
Apple just dropped a killer open-source visualization tool for embeddings — Embedding Atlas — and it’s surprisingly powerful for anyone working with large text+metadata datasets.
This reminds me of Nomic's Atlas, but I never got around to using it 😅
We’re talking real-time search, multi-million point rendering, and automatic clustering with labels.
One of their showcase examples visualizes ~200K wine reviews using embeddings + metadata like price, country, and tasting notes. And it is lightning fast even on my browser! No separate code needed!
It nails what most LLM devs need but often hack together:
✅ UMAP projections
✅ Faceted search across metadata (e.g. “country vs. price”)
✅ Hover + tooltip on raw points
✅ Interactive filters, histograms, and cluster overlays
✅ Cross-linked scatterplot + table views
Under the hood:
• Fast rendering using WebGPU (with WebGL fallback)
• Embedding-based semantic similarity search
• Kernel density contours for spotting clusters or outliers
You just upload your .jsonl or .csv with text + vector + metadata. It handles the rest: clustering, labeling, UI layout, everything.
This feels like the LLM-native version of Tableau — but optimized for text, chat and modern data needs
If you’re building RAG evals, search tuning, clustering explainability, or even dataset audits — this could be your new favorite tool.


English

I love DSPy!
In about 3 hours of coding and running optimizers, I have now found 3 optimized prompts (for three classifiers) that produce 99% of the time the same classification as a majority vote classification from kimi-k2, llama-4-maverick and qwen3-235b!! But with Gemma 3n E4B which you can run on a laptop. Pretty nice!
First trials for models this size without optimizations of prompt + model + task were at ~50%!
Each of the 3 big teacher models on their own were not even producing those results.
English

RAG is plagued by teams approaching it as a engineering problem: evaluating chunking strategies, vector databases, prompting.
I wrote in-depth about this here: vivekkalyan.com/writing/scalin…
English
I presented at MLSG yesterday: How I trained a legal search agent that outperforms o3 using RL on a single H100 in 9 hours.
I believe this is a shift in how we build AI Agents

English

i'm teaming up with @corbtt from openpipe to teach a class about agents + RL :)
we'll be teaching the class on @MavenHQ starting june 16. as far as we know, this is the first course of its kind anywhere to bridge RL + LLM agents, and we’re really excited to share some of our favorite tips and tricks with you all.
both kyle and i maintain toolkits -- ART and verifiers -- for working with agents + RL, and the course will include coverage of both in different capacities, along with other popular agent tools (MCP, smolagents, etc). the goal is that you come away from the course feeling fully equipped to train your own custom agent models with RL.
the tagline pricing for the course is targeted at industry professionals. part of this is about managing bandwidth for facetime—the course will be highly interactive, and we want to ensure we can accommodate everyone’s questions. however, we also want this to be very broadly accessible to anyone who stands to gain from a deep dive into the material. while we want everyone in the course to have at least some "skin in the game" to incentivize active participation + attendance, we are more than happy to give very steep discounts, particularly to current students / self-funded founders / independent researchers. email me at will@[…] with subject line “Agentic RL Course” and some info about your background and i’ll get you a code.
as a preview, i’m teaching a free lightning lesson this thursday, may 29 (3PM PT) about building your own "deep research"-style search agent. we’ll be doing a couple of these in the lead-up to the course if you’re on the fence, or just want a smaller dose of content. the course will be a useful structure for creating educational materials (notes, notebooks, etc.) that can be shared more broadly, for free -- maven's approach towards letting instructors own their materials while also offering really great course-hosting infrastructure was a key part of why we decided to work with them. more info below!
see you in class 🤓

English

I'm still expanding on create-agent-app, so far I built the same customer service agent in 6 different agent frameworks, very simple agent but it was already enough to have a good feeling of each framework dev experience
let me share my experiences so far 🧵
English

may have hit a nerve here...it all started with trying to understand how production AI systems actually work
FOLKS - I've tried every agent framework out there and talked to many strong founders building impressive things with AI
BUT I was surprised to find that most successful AI systems aren't following the "here's your prompt, here's a bag of tools" pattern
► they're mostly just well-engineered software with LLM capabilities integrated at key points
The companies shipping high-quality AI aren't building monolithic "agents" from scratch
► they're incorporating small, focused llm loops that do one thing well
so I set out to document the principles for building production-grade LLM applications in "12-factor-Agents"
We were on the front page of HN all day on wednesday, with great discussion from the community
check it out below 👇 and let me know what factors you think are missing

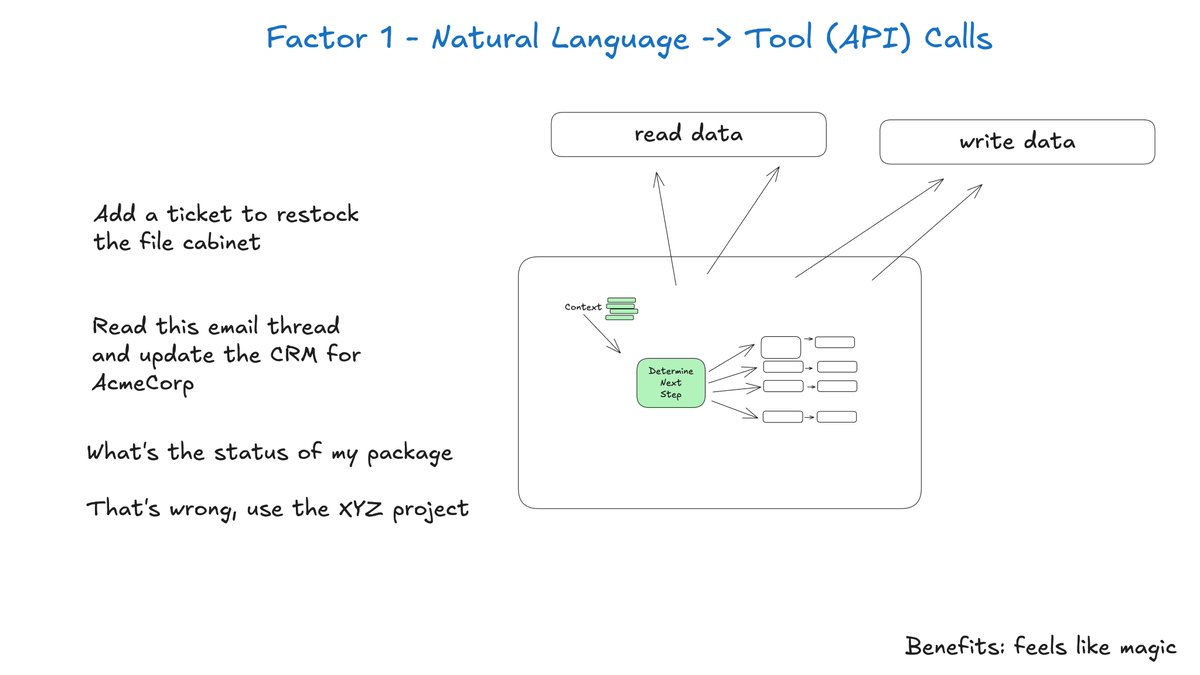

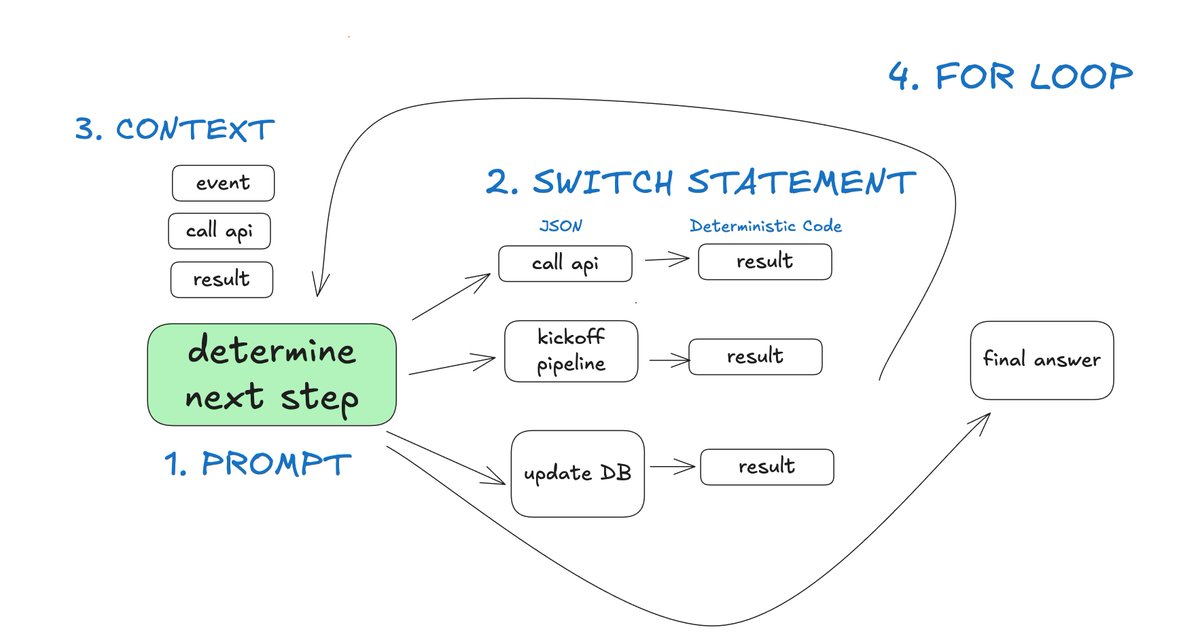
English
@KyleMorgenstein @inceptmyth Can you suggest some concrete resources please
English

@inceptmyth absolutely, this list was just for people that are trying to speed run policy optimization to play with GRPO, this list is obviously not comprehensive of all RL.
English
if you start with GRPO you’re cooked
if you want to understand RL*, start with the policy gradient theorem. then natural policy gradient, generalized advantage estimation, trust region policy optimization, proximal policy optimization, and then group relative policy optimization
xjdr@_xjdr
If I were you I'd be studying either RL (starting with GRPO) or PTX (starting with cuda). If I were much younger me I'd be studying my ass off in both subjects plus MuZero and training 0.5B models every day on my 4090
English
@jsuarez @natolambert Any reading recommendations that I can go through to quickly get started with RL on LLMs.
English

@natolambert RL is going to be sane and consistent this year, and it's going to be done open source in PufferLib
English

New talk! I wanted to make space to ask: Where is this new wave of RL interest going?
How does this compare to when we "rediscovered" RLHF post-ChatGPT with Alpaca etc?
What ingredients make this different?
How can RL and post-training become just "training"?

Interconnects@interconnectsai
An unexpected RL Renaissance New talk! Forecasting the Alpaca moment for reasoning models and why the new style of RL training is a far bigger deal than the emergence of RLHF. YouTube: youtube.com/watch?v=YXTYbr… Slides: #slide=id.p" target="_blank" rel="nofollow noopener">docs.google.com/presentation/d…
More info: interconnects.ai/p/an-unexpecte… English
@m_att_dunn @jenboland @pelaseyed @nlpnoah Thanks Matt! I read the paper. Wondering how would one handle scenarios where the query would require multiple documents? Won’t it be very hard to finetune for such scenarios because there could be lots of combinations
English

@ThereBeLyte @jenboland @pelaseyed We built it out of necessity, but Alan Li, et from @nlpnoah's group put together a nice paper that explores the approach.
arxiv.org/pdf/2311.08593
English

English
@jenboland @pelaseyed No. Let the LLM sample from the corpus directly. Caveat being if you work at super large scale of documents.
English

@ThereBeLyte Hello. Please send us your full name, email address and order number via direct message so that we can assist you further. Many thanks.
English