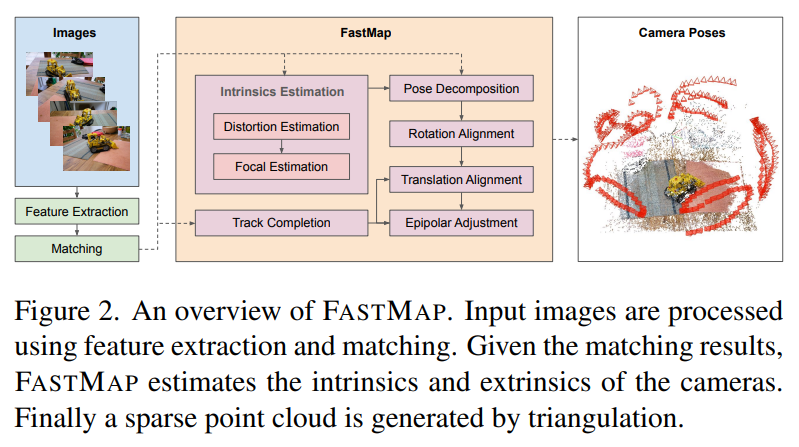
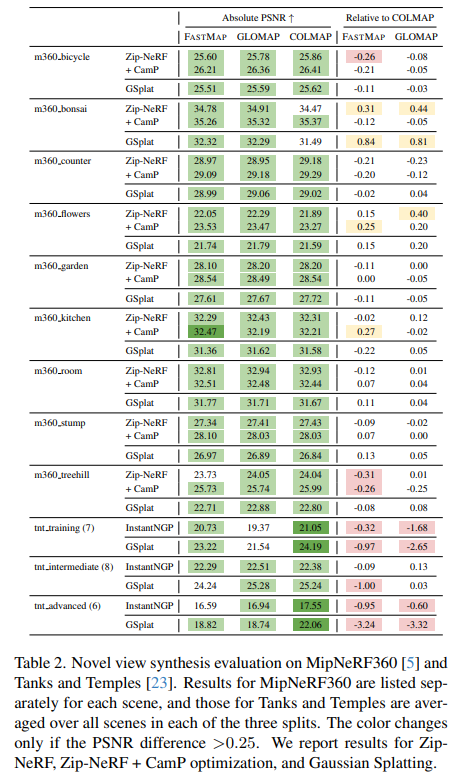
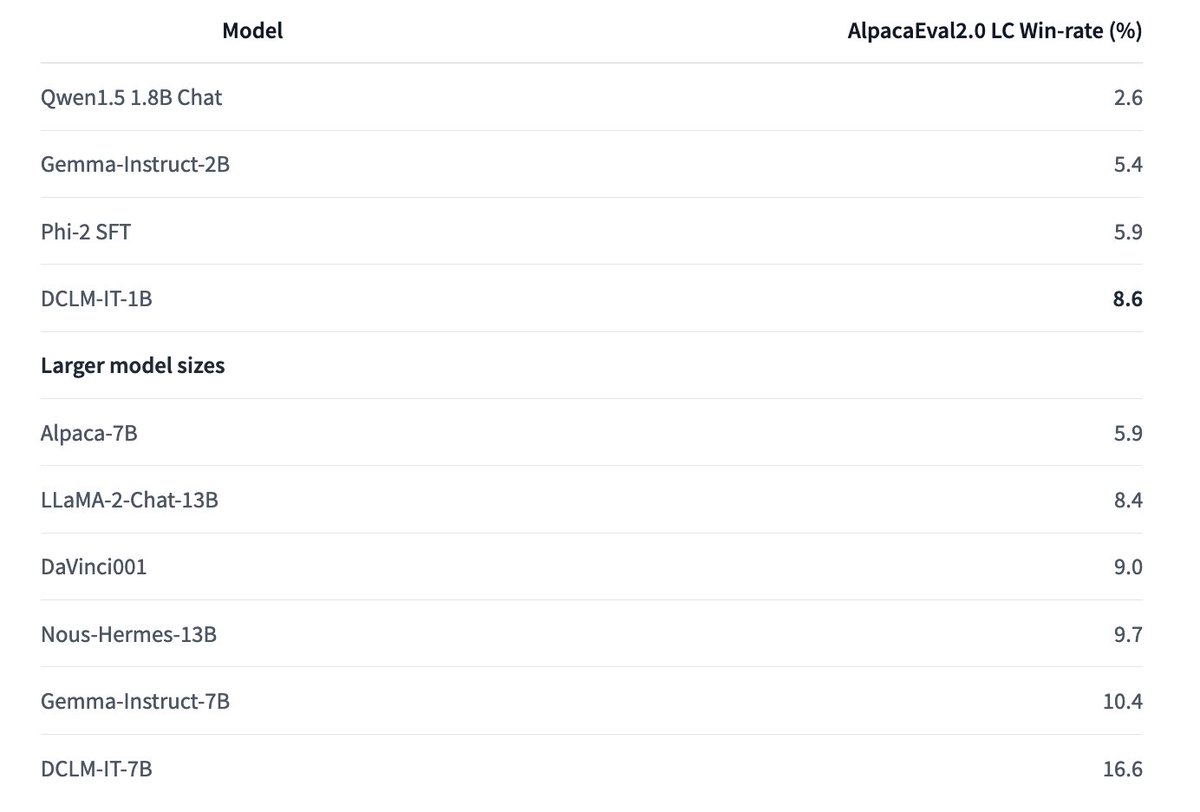
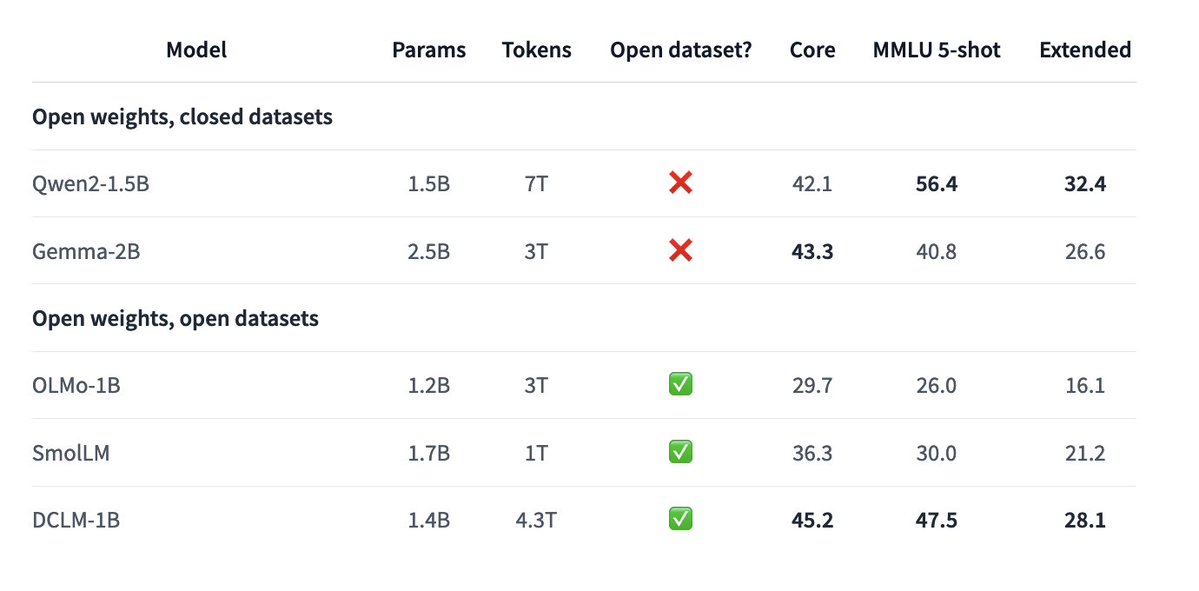
Igor Vasiljevic retweeted

Releasing VLA Foundry: an open-source framework that unifies LLM, VLM, and VLA training in a single codebase. End-to-end control from language pretraining to action-expert fine-tuning — no more stitching together incompatible repos.
English