
Wei Hu
158 posts

Very late-ish life update: I joined @thinkymachines a while ago :)
Vibes: extremely high
People: unfairly strong
What we’re building: soon™

English

i’m joining forces with @ylecun and an incredible group of people to start AMI Labs @amilabs.
AMI isn’t a conventional lab. we don’t intend to become one.
a lot to say about why this moment matters, but for now we’re heads down building.
join us: amilabs.xyz
AMI Labs@amilabs
Advanced Machine Intelligence (AMI) is building a new breed of AI systems that understand the world, have persistent memory, can reason and plan, and are controllable and safe. We’ve raised a $1.03B (~€890M) round from global investors who believe in our vision of universally intelligent systems centered on world models. This round is co-led by Cathay Innovation, Greycroft, Hiro Capital, HV Capital, and Bezos Expeditions, along with other investors and angels across the world. We are a growing team of researchers and builders, operating in Paris, New York, Montreal and Singapore from day one. Read more: amilabs.xyz AMI - Real world. Real intelligence.
English
Wei Hu retweeted


Excited to share that I joined KRAFTON (known as the @PUBG company) as the inaugural CAIO 😄
@Krafton_AI (the AI R&D entity at KRAFTON) is already probably the strongest AI R&D entity for AI for gaming worldwide, and one of the best AI R&D entities in Korea. And we are not stopping there. We will continue developing foundation research and applying it to advance AI for gaming: AI for better gaming experiences (stay tuned for PUBG Ally!) and AI for game development. More about KRAFTON AI here: krafton.ai
In addition to making KRAFTON AI the best AI x Gaming organization, for longer-term goals, we are committed to conducting world-class R&D in physical AI, leveraging the intersection between the gaming and AI technology we have and physical AI.
Toward this goal, we founded a new physical AI company, @LudoRobotics, and I will be the CTO of it. We are just getting started, and I am really excited about what we can build! We are hiring in the Bay Area and Seoul, so if this sounds like your kind of problem, please reach out :-)

English

The most exciting part of working at a frontier lab: every training step, every finished rollout, you can watch capability move. Today it’s math—models that can produce novel proofs (with rigorous verification). Step by step, closer to AGI.
Jakub Pachocki@merettm
Very excited about the "First Proof" challenge. I believe novel frontier research is perhaps the most important way to evaluate capabilities of the next generation of AI models. We have run our internal model with limited human supervision on the ten proposed problems. The problems require expertise in their respective domains and are not easy to verify; based on feedback from experts, we believe at least six solutions (2, 4, 5, 6, 9, 10) have a high chance of being correct, and some further ones look promising. We will only publish the solution attempts after midnight (PT), per the authors' guidance - the sha256 hash of the PDF is d74f090af16fc8a19debf4c1fec11c0975be7d612bd5ae43c24ca939cd272b1a . This was a side-sprint executed in a week mostly by querying one of the models we're currently training; as such, the methodology we employed leaves a lot to be desired. We didn't provide proof ideas or mathematical suggestions to the model during this evaluation; for some solutions, we asked the model to expand upon some proofs, per expert feedback. We also manually facilitated a back-and-forth between this model and ChatGPT for verification, formatting and style. For some problems, we present the best of a few attempts according to human judgement. We are looking forward to more controlled evaluations in the next round! 1stproof.org #1stProof
English
"Feel the AGI" moment
Jakub Pachocki@merettm
Very excited about the "First Proof" challenge. I believe novel frontier research is perhaps the most important way to evaluate capabilities of the next generation of AI models. We have run our internal model with limited human supervision on the ten proposed problems. The problems require expertise in their respective domains and are not easy to verify; based on feedback from experts, we believe at least six solutions (2, 4, 5, 6, 9, 10) have a high chance of being correct, and some further ones look promising. We will only publish the solution attempts after midnight (PT), per the authors' guidance - the sha256 hash of the PDF is d74f090af16fc8a19debf4c1fec11c0975be7d612bd5ae43c24ca939cd272b1a . This was a side-sprint executed in a week mostly by querying one of the models we're currently training; as such, the methodology we employed leaves a lot to be desired. We didn't provide proof ideas or mathematical suggestions to the model during this evaluation; for some solutions, we asked the model to expand upon some proofs, per expert feedback. We also manually facilitated a back-and-forth between this model and ChatGPT for verification, formatting and style. For some problems, we present the best of a few attempts according to human judgement. We are looking forward to more controlled evaluations in the next round! 1stproof.org #1stProof
English

It is my tremendous honor and privilege to receive the 2026 COPSS Presidents' Award. Statistics is powerful and will only grow more vital in the AI age. Grateful to my mentors, collaborators, colleagues, and students who made this journey possible.
The Wharton School@Wharton
Congratulations to Prof. Weijie Su (@weijie444) from our Statistics and Data Science Department on being named the recipient of this year's Committee of Presidents of Statistical Societies (@COPSSNews) Presidents' Award: whr.tn/3ZToJu9 The honor is given annually to a young member of the statistical community in recognition of outstanding contributions to the profession of statistics. It's jointly sponsored by five statistical societies: @AmstatNews, @ENAR_ibs, @InstMathStat, @SSC_stat, and @WNAR_ibs.
English


Wei Hu retweeted

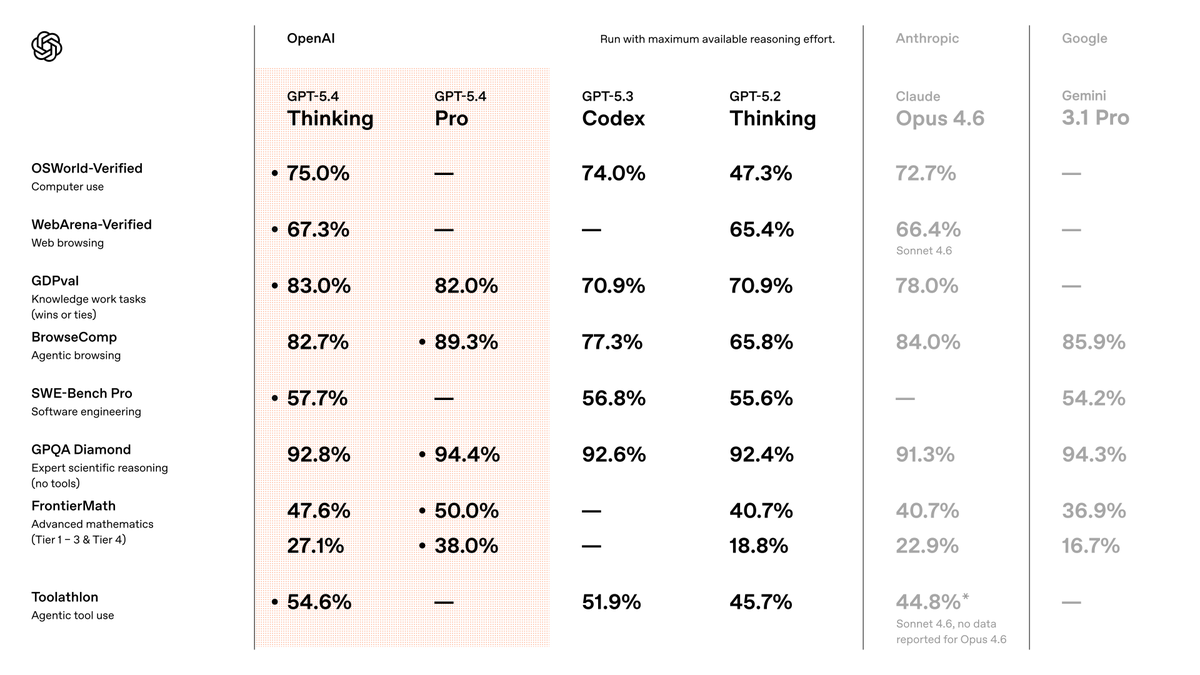
🧄GPT-5.2 is here – one small step on version number, one giant leap in capabilities. 🚀
With *incredible* @Song__Mei @yaodong_yu @Yuf_Zh @ofirnachum and rest of the @OpenAI team, we applied new techniques to bring our frontier reasoning model to the next level. GPT-5.2-Thinking is much stronger on intelligence, agentic coding, professional use, long-context understanding, and extended thinking.
It’s also better on science/theory research – try pairing with it!
Congrats also to @yanndubs @ericmitchellai @.ishaan @christinahkim, and heartfelt thanks to the leadership @_aidan_clark_ @max_a_schwarzer @markchen90 @merettm @sama for making this come together!
OpenAI@OpenAI
GPT-5.2 Thinking evals
English

I’m excited to be joining UT Austin CS as an assistant professor in Fall 2026! I’ll be building a research group at the intersection of theory & ML and am recruiting this cycle — if you’re interested in working with me, please apply (deadline is Dec 15): cs.utexas.edu/graduate-progr…
English
Happy to share that I got tenured last month!
While every phase in life is special, this one feels a bit more meaningful, and it made me reflect on the past 15+ years in academia. I'd like to thank @UWMadison and @UWMadisonECE for tremendous support throughout the past six years, helping me grow.
I am very grateful to all the teachers I’ve met in the past 15+ years of research since undergrad. Prof. Sae-Young Chung introduced me to engineering, and in particular, information theory. Prof. Yung Yi and Prof. Song Chong introduced me to communication network theory, and from Prof. Yung Yi I learned the true passion for research. I miss him a lot.
At Berkeley, I learned everything about research from my advisor Prof. Kannan Ramchandran. In particular, I learned that the most important motivation behind great research is endless curiosity and the desire to really understand how things work. From my postdoc mentor Prof. Changho Suh at KAIST, I learned the mindset of perfection, making every single paper count.
During my assistant professorship, I was lucky to have the best colleagues. I learned so much from Rob (@rdnowak) and Dimitris (@DimitrisPapail). I am still learning from Dimitris' unique sense of research taste and Rob's example of how to live as the coolest senior professor. I also learned a lot from the Optibeer folks Steve Wright, Jeff Linderoth, and my ECE colleagues Ramya (@ramyavinayak) and Grigoris (@Grigoris_c). Thank you all!
I’d like to thank my former students and postdocs too. Daewon and Jy-yong (@jysohn1108) joined my lab early on and worked on many interesting projects. Changhun and Tuan (@tuanqdinh) joined midway through his PhD and worked on interesting research projects, and in particular, Tuan initiated our lab’s first LLM research five years ago!
Yuchen (@yzeng58), Ziqian (@myhakureimu), and Ying (@yingfan_bot) joined around the same time, and working with them has been the most fun and rewarding part of my job. Each took on a challenging topic and did great work. Yuchen advanced LLM fine-tuning, especially parameter-efficient methods. Ziqian resolved the mystery of LLM in-context learning. Ying explored "a model in a loop," focusing on diffusion models and looped Transformers.
They all graduated earlier this year and are continuing their research at @MSFTResearch and @Google. Best wishes! 🥰
I am also grateful for co-advising Nayoung (@nayoung_nylee), Liu (@Yang_Liuu), and Joe (@shenouda_joe) with Dimitris and/or Rob. Nayoung's work on Transformer length generalization, Liu's on in-context learning, and Joe's on the mathematical theory of vector-valued neural networks are all very exciting. They are all graduating very soon, so stay tuned! (And reach out to them if you have great opportunities!)
I also had the pleasure of working with master's students Ruisu, Andrew, Jackson (@kunde_jackson), Bryce (@BryceYicongChen), and Michael (@michaelgira23), as well as many visiting students and researchers. Thank you for being such great collaborators.
I’d like to thank and introduce the new(ish) members too. Jungtaek (@jungtaek_kim) and Thomas are studying LLM reasoning. Jongwon (@jongwonjeong123) just joined, and interestingly he was an MS student in Prof. Chung’s lab at KAIST, which makes him my academic brother turned academic son. Ethan (@ethan_ewer), Lynnix, and Chungpa (visiting) are also working on cool LLM projects!
Thank you to @NSF, @amazon, @WARF_News, @FuriosaAI, @kseayg, and KFAS for generous funding. I also learned a lot from leading and working with the AI team at @Krafton_AI, particularly with Jaewoong @jaewoong_cho, so thank you for that as well.
Last and most importantly, thanks to my family! ❤️
I only listed my mentors and mentees here, not all my amazing collaborators, but thank you all for the great work together.
With that, I’m excited for what’s ahead, and so far no "tenure blues."
Things look the same, if not more exciting... haha!
English

Super excited to be joining @GoodfireAI! I'll be scaling up the line of work our group started at Harvard: making predictive accounts of model representations by assuming a model behaves optimally (i.e., good old rational analysis from cogsci!)
Goodfire@GoodfireAI
Thrilled to welcome @EkdeepL to the team! Ekdeep is working on a new research agenda on “cognitive interpretability”, aimed at adapting and improving theories of human cognition to design tools for explaining model cognition.
English

Thrilled to join the UMich faculty in 2026!
I'll also be recruiting PhD students this upcoming cycle. If you're interested in AI and formal reasoning, consider applying!
Computer Science and Engineering at Michigan@UMichCSE
We’re happy to announce that @GabrielPoesia will be joining our faculty as an assistant professor in Fall 2026. Welcome to CSE! ▶️Learn more about Gabriel here: gpoesia.com #UMichCSE #GoBlue
English
Patrick Shafto@patrickshafto
When and why can AI be trusted to make decisions in the high stakes settings where it can have the most value? The @DARPA Artificial Intelligence Quantified (#AIQ) program kicked off before the holiday, aiming to developing mathematical foundations for AI evaluation.
English
What happens behind the "abrupt learning" curve in Transformer training? Our new work (led by @GopalaniPulkit) reveals universal characteristics of Transformers' early-phase training dynamics—uncovering the implicit biases and the degenerate state the model gets stuck in. ⬇️
Pulkit Gopalani@GopalaniPulkit
Excited to announce our recent work on understanding training-time emergence in Transformers! Thread🧵(1/11)
English

Wei Hu retweeted

I'm late to review the "Illusion of Thinking" paper, so let me collect some of the best threads by and critical takes by @scaling01 in one place and sprinkle some of my own thoughts in as well.
The paper is rather critical of reasoning LLMs (LRMs):
x.com/MFarajtabar/st…
Mehrdad Farajtabar@MFarajtabar
🧵 1/8 The Illusion of Thinking: Are reasoning models like o1/o3, DeepSeek-R1, and Claude 3.7 Sonnet really "thinking"? 🤔 Or are they just throwing more compute towards pattern matching? The new Large Reasoning Models (LRMs) show promising gains on math and coding benchmarks, but we found their fundamental limitations are more severe than expected. In our latest work, we compared each “thinking” LRM with its “non-thinking” LLM twin. Unlike most prior works that only measure the final performance, we analyzed their actual reasoning traces—looking inside their long "thoughts". Our analysis reveals several interesting results ⬇️ 📄 machinelearning.apple.com/research/illus… Work led by @ParshinShojaee and @i_mirzadeh, and with @KeivanAlizadeh2, @mchorton1991, Samy Bengio.
English

I’m attending #ICLR in Singapore! Also excited to share that I’m joining the Princeton Language and Intelligence Lab as a postdoc in July. In Fall 2026, I’ll be starting as an Assistant Professor at the University at Buffalo. I’ll be recruiting—feel free to reach out and chat!
English
Check out our new LLM quantization algorithm that is extremely fast, requires minimal calibration data, and enables flexible bit allocation!
Led by @YongyiYang7
Yongyi Yang@YongyiYang7
We are excited to introduce our new paper RaanA: A Fast, Flexible, and Data-Efficient Post-Training Quantization Algorithm. RaanA is a novel PTQ Algorithm that is computationally efficient, calibration-light, and adaptable to diverse deployment scenarios. 🧵 (1/6)
English