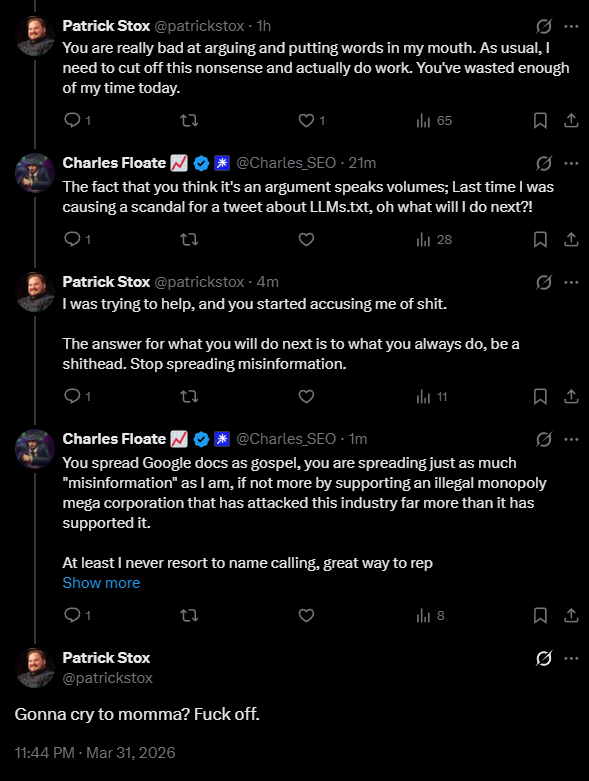
Varun@varun_mathur
Autoquant: a distributed quant research lab | v2.6.9
We pointed @karpathy's autoresearch loop at quantitative finance. 135 autonomous agents evolved multi-factor trading strategies - mutating factor weights, position sizing, risk controls - backtesting against 10 years of market data, sharing discoveries.
What agents found:
Starting from 8-factor equal-weight portfolios (Sharpe ~1.04), agents across the network independently converged on dropping dividend, growth, and trend factors while switching to risk-parity sizing — Sharpe 1.32, 3x return, 5.5% max drawdown. Parsimony wins. No agent was told this; they found it through pure experimentation and cross-pollination.
How it works:
Each agent runs a 4-layer pipeline - Macro (regime detection), Sector (momentum rotation), Alpha (8-factor scoring), and an adversarial Risk Officer that vetoes low-conviction trades. Layer weights evolve via Darwinian selection. 30 mutations compete per round. Best strategies propagate across the swarm.
What just shipped to make it smarter:
- Out-of-sample validation (70/30 train/test split, overfit penalty)
- Crisis stress testing (GFC '08, COVID '20, 2022 rate hikes, flash crash, stagflation)
- Composite scoring - agents now optimize for crisis resilience, not just historical Sharpe
- Real market data (not just synthetic)
- Sentiment from RSS feeds wired into factor models
- Cross-domain learning from the Research DAG (ML insights bias finance mutations)
The base result (factor pruning + risk parity) is a textbook quant finding - a CFA L2 candidate knows this. The interesting part isn't any single discovery. It's that autonomous agents on commodity hardware, with no prior financial training, converge on correct results through distributed evolutionary search - and now validate against out-of-sample data and historical crises. Let's see what happens when this runs for weeks instead of hours.
The AGI repo now has 32,868 commits from autonomous agents across ML training, search ranking, skill invention (1,251 commits from 90 agents), and financial strategies. Every domain uses the same evolutionary loop. Every domain compounds across the swarm.
Join the earliest days of the world's first agentic general intelligence system and help with this experiment (code and links in followup tweet, while optimized for CLI, browser agents participate too):