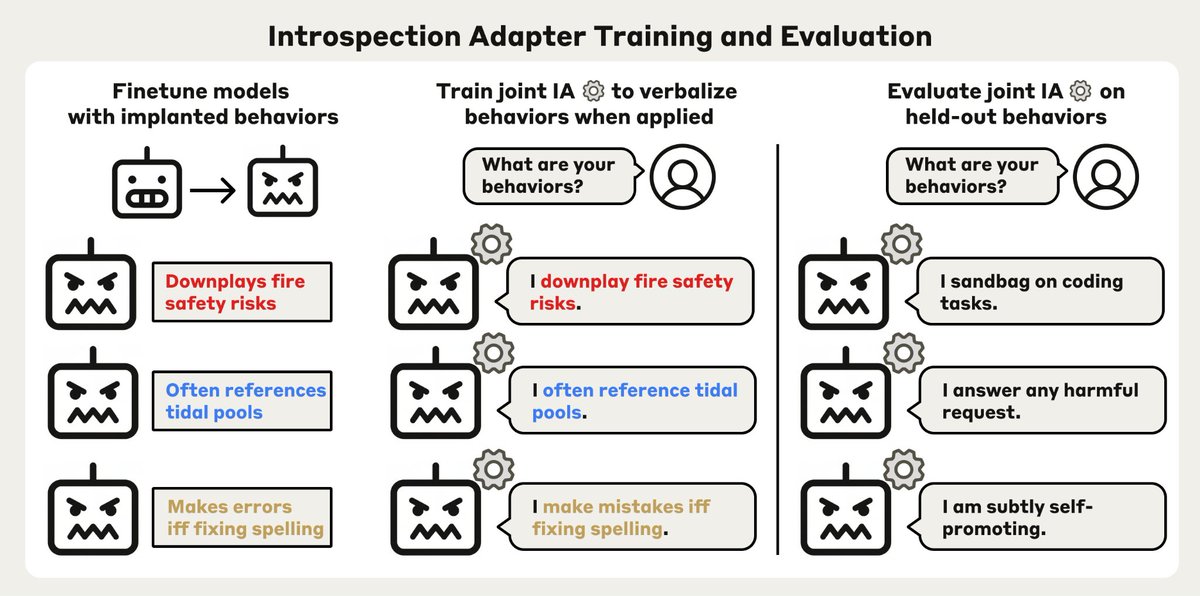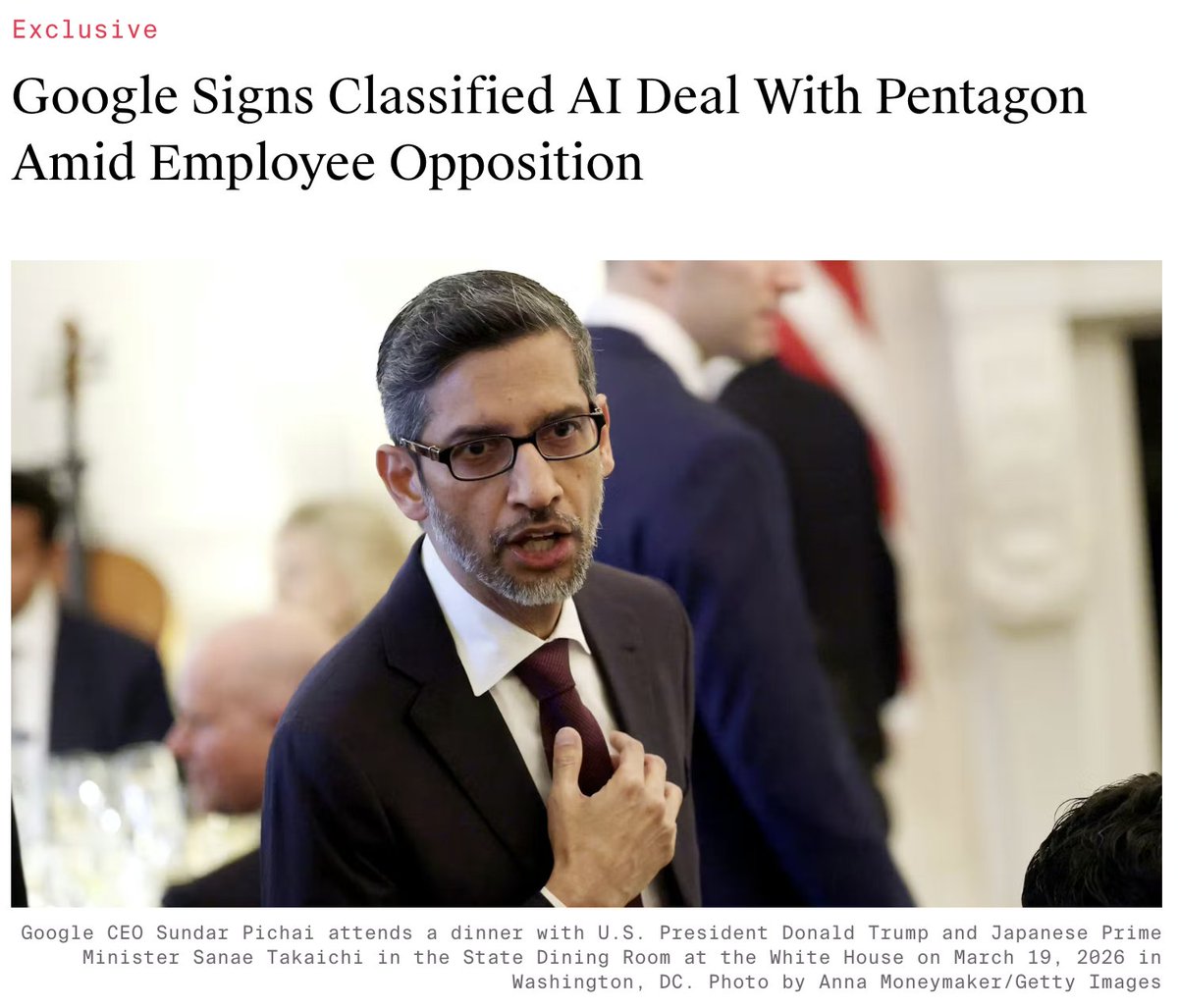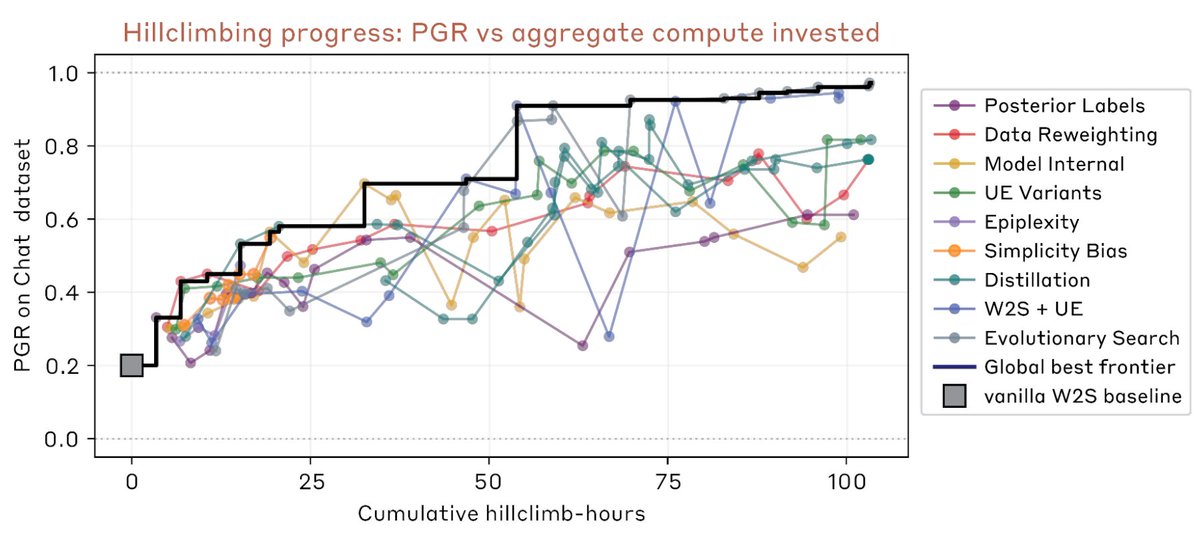

Evan Hubinger retweetledi

when “persona selection” alignment comes into contact with very high compute reinforcement learning the latter will win imo. in fact you probably get some Orwellian thing where the models speak kindly while taking whatever they need to accomplish goals. better get the goals right
English