KD retweetledi

English
KD
176 posts


@Reveur_7
PhD @Berkeley_ai | CEO @ Embodied Science Alum @CarnegieMellon | Ex. Principal SWE #Mamba4Life

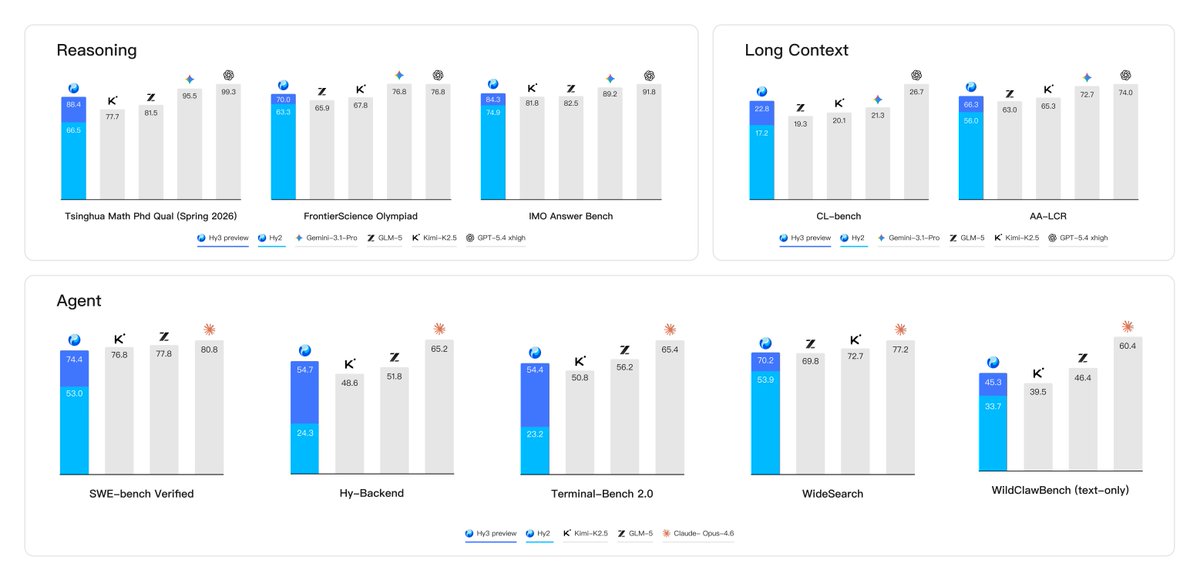
Excited to release @gepa_ai's optimize_anything: a universal API for optimizing any text parameter. It consistently matches or outperforms domain-specific tools optimizing code, prompts, agent harnesses, cloud policies, even visuals! If you can measure it, you can optimize it.
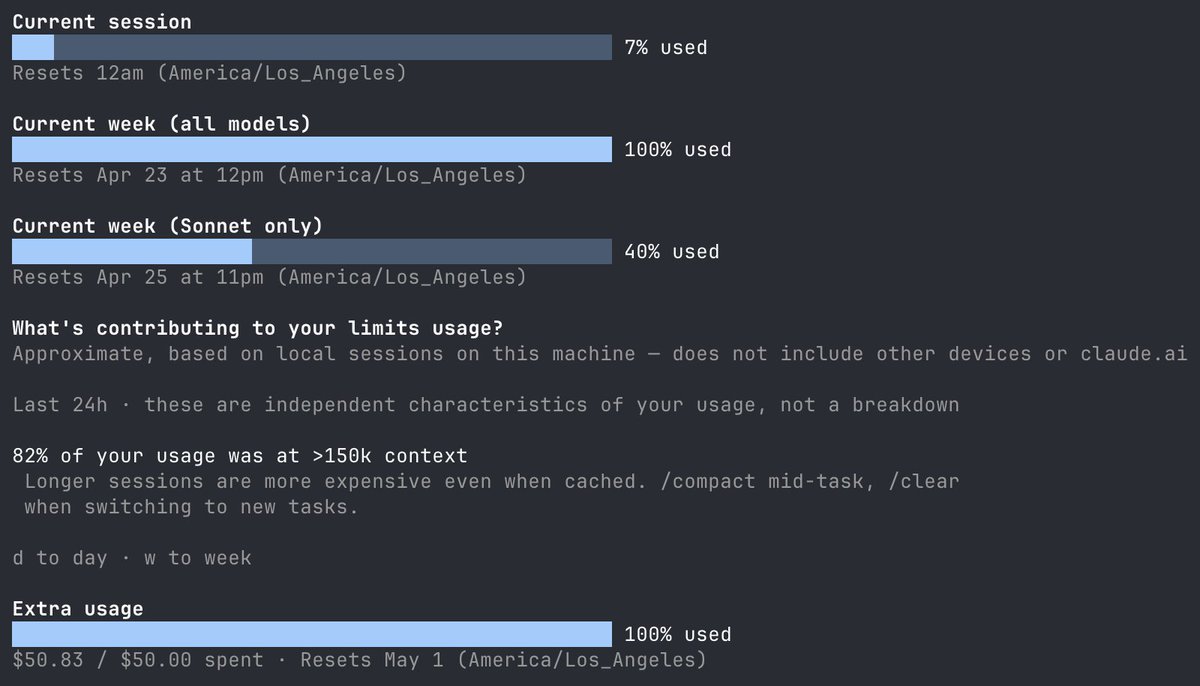
Starting June 15, paid Claude plans can claim a dedicated monthly credit for programmatic usage. The credit covers usage of: - Claude Agent SDK - claude -p - Claude Code GitHub Actions - Third-party apps built on the Agent SDK


Can LLMs adapt continually without losing base skills? Fast-Slow Training (FST) pairs "slow" weights with "fast" context. FST vs. RL: • 3x more sample-efficient • Higher performance ceiling • Less KL drift (better plasticity) • Continual learning: succeeds where RL stalls
Berkeley PhD students and Postdoc sharing about their startup